

论文名称:Deformable Convolutional Networks
论文下载:https://arxiv.org/abs/1703.06211
论文年份:ICCV 2017
论文被引:2791(2022/05/15)
论文代码:https://github.com/msracver/Deformable-ConvNets
论文笔记
本文提出了可变形卷积神经网络,其基于两个模块:可变形卷积和可变形ROI池化。
具体地,可变形卷积是利用额外的卷积层学习每个感受野的偏移量。可变形ROI池化通过FC层学习额外的偏移量。此外,还提出了可变形位置敏感ROI池化,其基于位置敏感ROI池化,通过额外的卷积层学习偏移量。
可变形卷积是空洞卷积的泛化,如图 1 © 所示。可变形卷积可以自适应确定尺度或感受野大小,对于具有精细定位的视觉识别(例如目标检测和语义分割)是有帮助的。
可变形卷积与常规卷积具有相同的输入和输出维度。
Abstract
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in their building modules. In this work, we introduce two new modules to enhance the transformation modeling capability of CNNs, namely, deformable convolution and deformable RoI pooling. Both are based on the idea of augmenting the spatial sampling locations in the modules with additional offsets and learning the offsets from the target tasks, without additional supervision. The new modules can readily replace their plain counterparts in existing CNNs and can be easily trained end-to-end by standard back-propagation, giving rise to deformable convolutional networks. Extensive experiments validate the performance of our approach. F or the first time, we show that learning dense spatial transformation in deep CNNs is effective for sophisticated vision tasks such as object detection and semantic segmentation.
卷积神经网络 (CNN) 由于其构建模块中的固定几何结构,本质上仅限于对几何变换进行建模。在这项工作中,我们引入了两个新模块来 增强 CNN 的变换建模能力,即可变形卷积 (deformable convolution) 和可变形 RoI 池化 (deformable RoI pooling)。两者都基于 使用额外偏移量增加模块中的空间采样位置,并从目标任务中学习偏移量的想法,而无需额外的监督。新模块可以很容易地替换现有 CNN 中的普通模块,并且可以通过标准反向传播轻松地进行端到端训练,从而 产生可变形的卷积网络。大量实验验证了我们方法的性能。我们首次表明,在深度 CNN 中学习密集空间变换对于复杂的视觉任务(如目标检测和语义分割)是有效的。
- Introduction
视觉识别的一个关键挑战是如何 适应目标尺度、姿势、视点和零件变形的几何变化或模型几何变换。一般来说,有两种方式。
- 首先是 构建具有足够期望变化的训练数据集。这通常是通过增加现有数据样本来实现的,例如,通过 仿射变换。可以从数据中学习稳健的表示,但通常以昂贵的训练和复杂的模型参数为代价。
- 第二种是 使用变换不变的特征和算法。该类别包含许多众所周知的技术,例如 SIFT(尺度不变特征变换)[42] 和基于滑动窗口的目标检测范例。
上述方式有 两个缺点。
- 首先, 假设几何变换是固定的和已知的。这种先验知识用于扩充数据,并设计特征和算法。这个假设阻止了对具有未知几何变换的新任务的泛化,这些任务没有正确建模。
- 其次, 对于过于复杂的转换,即使是已知的,不变特征和算法的手工设计也可能很困难或不可行。
最近,卷积神经网络 (CNN) [35] 在图像分类 [31]、语义分割 [41] 和目标检测 [16] 等视觉识别任务中取得了显着的成功。尽管如此,它们仍然具有上述两个缺点。他们 对几何变换建模的能力主要来自广泛的数据增强、大模型容量和一些简单的手工模块(例如, 用于小平移不变性的 max-pooling [1])。
简而言之, CNN 本质上仅限于对大型未知转换进行建模。限制源于 CNN 模块的固定几何结构:
- 卷积单元在固定位置对输入特征图进行采样;
- 池化层以固定比例降低空间分辨率;
- RoI(感兴趣区域)池化层将 RoI 分成固定的空间箱等。
缺乏处理几何变换的内部机制。这会导致明显的问题。
- 举一个例子, 同一 CNN 层中所有激活单元的感受野大小相同。这对于在空间位置上编码语义的高级 CNN 层是不可取的。因为不同的位置可能对应于具有不同尺度或变形的目标,所以 自适应确定尺度或感受野大小对于具有精细定位的视觉识别是可取的,例如,使用完全卷积网络的语义分割[41]。
- 再举一个例子,虽然最近目标检测取得了显着和快速的进展 [16,52,15,47,46,40,7],但所有方法仍然 依赖于基于原始边界框的特征提取。这显然是次优的,尤其是对于非刚性目标。
在这项工作中,我们引入了两个新模块,它们极大地增强了 CNN 对几何变换建模的能力。
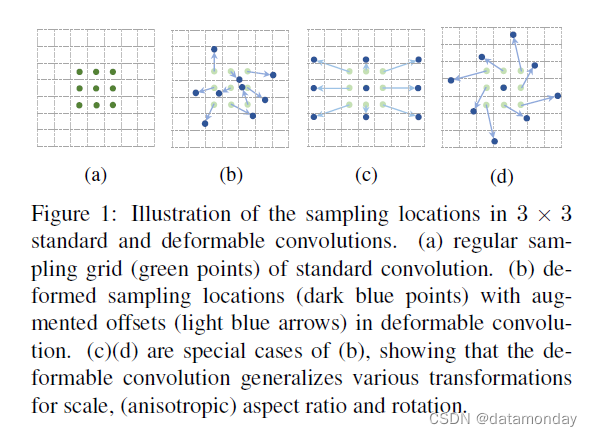

图 1:3 × 3 标准和可变形卷积中的采样位置示意图。 (a) 标准卷积的规则采样网格(绿点)。 (b) 在可变形卷积中具有增强偏移(浅蓝色箭头)的变形采样位置(深蓝色点)。 ©(d) 是 (b) 的特殊情况,表明可变形卷积泛化了缩放、(各向异性)纵横比和旋转的各种变换。
- 第一个是 可变形卷积 (deformable convolution)。它 将二维偏移添加到标准卷积中的常规网格采样位置。它使采样网格能够自由变形。如图 1 所示。 偏移量是通过额外的卷积层从前面的特征图中学习的。因此, 变形以局部、密集和自适应的方式以输入特征为条件。
- 第二个是 可变形的 RoI 池化 (deformable RoI pooling)。它为先前 RoI 池化 [15, 7] 的 常规 bin 分区中的每个 bin 位置添加一个偏移量。类似地, 偏移量是从前面的特征图和 RoI 中学习的,从而可以对不同形状的目标进行自适应部分定位。
两个模块都很轻。他们 为偏移学习添加了少量的参数和计算。它们可以很容易地替换深度 CNN 中的普通对应物,并且可以通过标准反向传播轻松地进行端到端训练。 生成的 CNN 称为可变形卷积网络或可变形 ConvNet。
我们的方法与空间变换网络 (spatial transform networks) [26] 和可变形零件模型 (deformable part models) [11] 具有相似的高级精神。它们都 具有内部转换参数,并且纯粹从数据中学习这些参数。 可变形卷积网络的一个关键区别在于它们以简单、高效、深度和端到端的方式处理密集的空间变换。在第 3.1 节中,我们详细讨论了我们的工作与以前的工作的关系,并分析了可变形卷积网络的优越性。
; 2. Deformable Convolutional Networks
CNN 中的特征图和卷积是 3D 的。 可变形卷积和 RoI 池化模块都在 2D 空间域上运行。该操作在通道维度上保持不变。在不失一般性的情况下,为清楚起见,此处以 2D 形式描述模块。扩展到 3D 很简单。
2.1. Deformable Convolution
2D 卷积包括两个步骤:
- 1)在 输入特征图 x 上使用规则网格 R 进行采样;
- 2)w 加权的采样值的总和。 网格 R 定义了感受野大小和膨胀 (dilation)。例如, R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 0 , 1 ) , ( 1 , 1 ) } R = {(−1, −1), (−1, 0), . . . , (0, 1), (1, 1)}R ={(−1 ,−1 ),(−1 ,0 ),…,(0 ,1 ),(1 ,1 )} 定义了一个 3 × 3 的核,膨胀为 1。
对于输出特征图 y 上的每个位置 p0,有
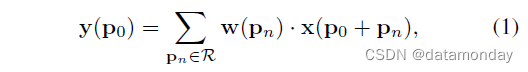
其中 pn 枚举 R 中的位置。
在可变形卷积中, 规则网格 R 增加了偏移量 {∆pn|n = 1, …, N},其中 N = |R|。公式 (1) 变成
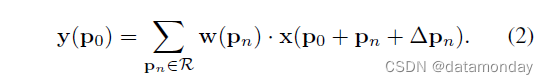
现在,采样是在不规则和偏移位置 pn+Δpn 上。 由于偏移量 Δpn 通常是小数,因此公式 (2) 通过双线性插值实现
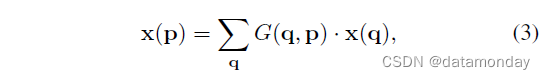
其中 p 表示任意(分数)位置(p = p0 + pn + Δpn 用于公式(2)),q 枚举特征图 x 中的所有积分空间位置,G(·,·) 是双线性插值核。请注意,G 是二维的。它被分成两个一维核
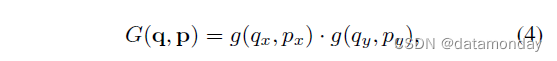
其中 g(a, b) = max(0, 1 – |a – b|)。公式 (3) 计算速度很快,因为 G(q, p) 仅在几个 qs 内不为零。
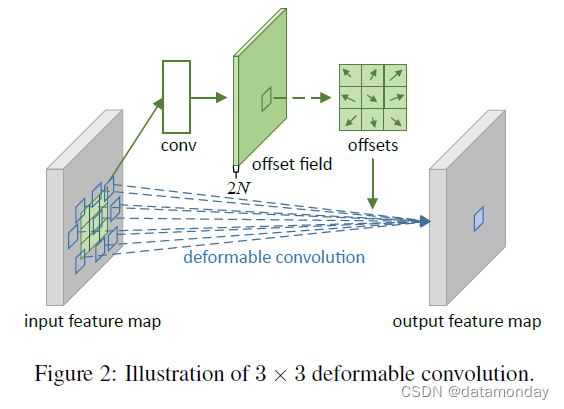
如图 2 所示, 偏移量是通过在相同的输入特征图上应用卷积层来获得的。卷积核具有与当前卷积层相同的空间分辨率和膨胀(例如,图 2 中的膨胀 1 也是 3×3)。 输出偏移字段与输入特征图具有相同的空间分辨率。 通道维度 2N 对应于 N 个 2D 偏移。 在训练期间,同时学习用于生成输出特征的卷积核和偏移量。为了学习偏移量,梯度通过公式 (3) 和 (4) 中的双线性操作反向传播,在附录 A 中有详细说明。
; 2.2. Deformable RoI Pooling
RoI 池化用于所有基于区域提议的目标检测方法 [16,15,47,7]。它 将任意大小的输入矩形区域转换为固定大小的特征。
RoI Pooling [15] 给定输入特征图 x 和大小为 w×h 和左上角 p0 的 RoI,RoI pooling 将 RoI 分成 k × k(k 是一个自由参数)bins,并输出一个 k × k 特征图 y。对于 (i, j)-th bin (0 ≤ i, j < k),有
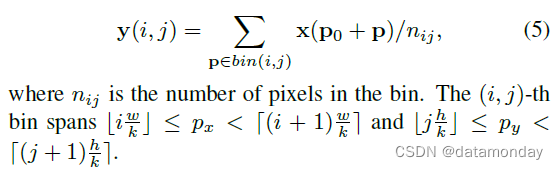
与公式 (2) 类似,在可变形 RoI 池化中,偏移量 {Δpij|0 ≤ i, j < k} 被添加到空间分箱位置。公式 (5) 变为
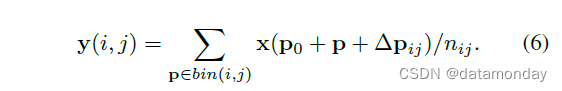
通常,Δpij 是分数。公式 (6) 通过公式 (3) 和 (4) 通过双线性插值实现。
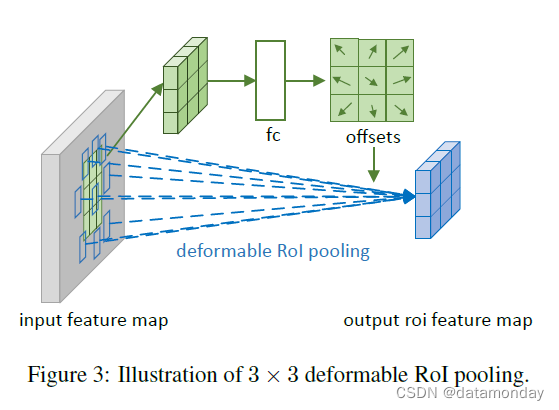
图 3 说明了如何获得偏移量。首先,RoI pooling (Eq. (5)) 生成池化特征图。从映射中,fc 层生成归一化偏移量 Δ p ^ i j Δ\hat{p}{ij}Δp ^i j ,然后通过与 RoI 的宽度和高度的元素乘积将其转换为等式 (6) 中的偏移量 Δ p i j Δp{ij}Δp i j ,如 Δ p i j = γ ⋅ Δ p ^ i j ◦ ( w , h ) Δp_{ij} = γ · Δ\hat{p}_{ij} ◦ (w, h)Δp i j =γ⋅Δp ^i j ◦(w ,h )。这里 γ γγ 是一个预定义的标量,用于 调制偏移量的大小。它根据经验 设置为γ = 0.1 γ = 0.1 γ=0 .1。偏移归一化对于使偏移学习对 RoI 大小保持不变是必要的。 fc 层通过反向传播学习,详见附录 A。
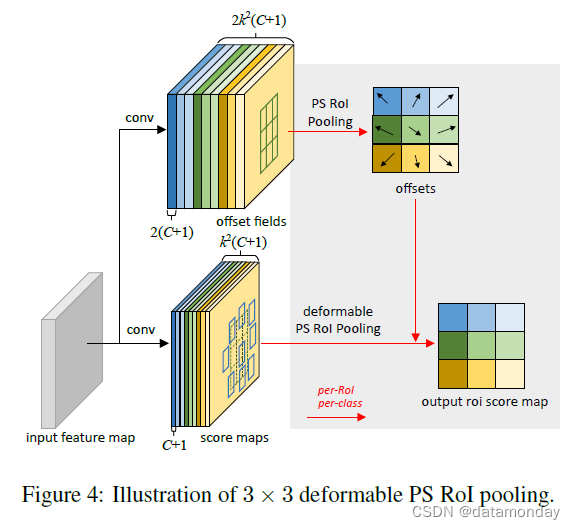
Position-Sensitive (PS) RoI Pooling [7] 是完全卷积的,与 RoI 池化不同。通过一个conv层,首先 将所有输入特征图转换为每个目标类的k 2 k^2 k 2 个分数图 (score map)(对于 C 个目标类,总共 C + 1 个),如图 4 中的底部分支所示。不需要区分类,例如分数图表示为 {xi,j},其中 (i, j) 枚举所有 bin。在这些分数图上执行池化。第 (i, j) 个 bin 的输出值是通过从与该 bin 对应的一个得分图 xi,j 求和获得的。简而言之,与公式 (5) 中的 RoI pooling 的区别在于, 一般特征图 x 被特定的正敏感分数图 (positive-sensitive score map) xi,j 替换。
在可变形 PS RoI 池化中,公式 (6) 的唯一变化是 x 也被修改为 xi,j。但是,偏移学习是不同的。它遵循 [7] 中的”完全卷积”精神,如图 4 所示。 在顶部分支中,卷积层生成完整的空间分辨率偏移场 (spatial resolution offset fields)。对于每个 RoI(也适用于每个类别),PS RoI pooling 应用于此类字段以获得归一化偏移量 Δ p ^ i j Δ\hat{p}{ij}Δp ^i j ,然后以与上述可变形 RoI 池化相同的方式将其转换为实际偏移量 Δ p i j Δp{ij}Δp i j 。
2.3. Deformable ConvNets
可变形卷积和 RoI 池化模块都具有与其普通版本相同的输入和输出。
因此,它们可以很容易地替换现有 CNN 中的普通对应物。 在训练中,这些添加的用于偏移学习的 conv 和 fc 层被初始化为零权重。它们的 学习率设置为现有层的学习率的 β 倍(默认情况下 β = 1,对于 Faster R-CNN 中的 fc 层,β = 0.01)。它们 通过公式 (3) 和公式 (4) 中的双线性插值操作通过反向传播进行训练。生成的 CNN 称为可变形 ConvNet。
为了将可变形 ConvNets 与最先进的 CNN 架构集成,我们注意到 这些架构由两个阶段组成。
- 首先, 深度全卷积网络在整个输入图像上生成特征图。
- 其次, 浅层任务特定网络从特征图生成结果。
我们详细说明以下两个步骤。
用于特征提取的可变形卷积 我们采用两种最先进的特征提取架构: ResNet-101 [22] 和 Inception-ResNet [51] 的修改版本。两者 都在 ImageNet [8] 分类数据集上进行了预训练。
最初的 Inception-ResNet 是为图像识别而设计的。它 存在特征错位问题 (feature misalignment),并且对于密集预测任务存在问题。它被修改以解决对齐问题[20]。修改后的版本被称为”Aligned-Inception-ResNet”,在附录 B 中有详细说明。
两个模型都包含几个卷积块、一个平均池和一个用于 ImageNet 分类的 1000 路 fc 层。平均池化和 fc 层被移除。 最后添加一个随机初始化的 1×1 卷积,以将通道维度减小到 1024。按照惯例 [4, 7],最后一个卷积块中的有效步幅从 32 像素减少到 16 像素,以增加特征图解析度。具体来说,在最后一个块的开头,步幅从 2 变为 1(ResNet-101 和 Aligned-Inception-ResNet 的”conv5″)。为了补偿,该块中所有卷积滤波器的膨胀(内核大小> 1)从1更改为2。
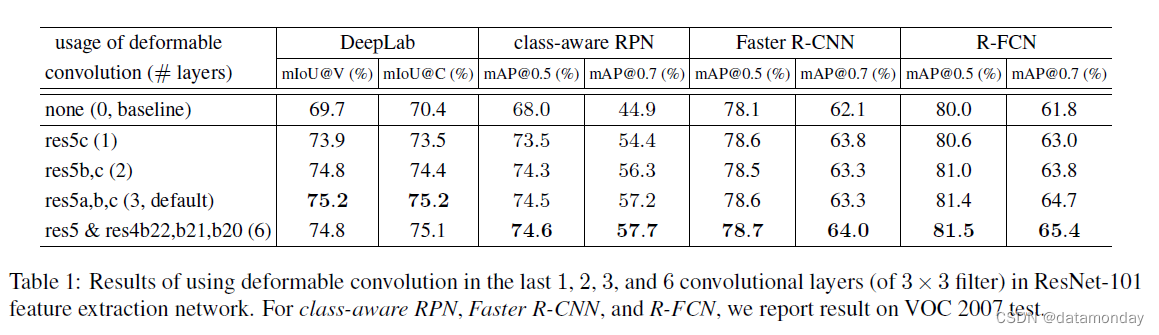
可选地, 可变形卷积应用于最后几个卷积层(卷积核大小> 1)。我们尝试了不同数量的此类层,发现 3 层可以作为不同任务的良好折衷,如表 1 所示。
分割和检测网络 任务特定网络建立在上述特征提取网络的输出特征图之上。
在下面,C 表示目标类别的数量。
DeepLab [5] 是一种最先进的语义分割方法。它 在特征图上添加了一个 1 × 1 的卷积层,以生成 (C + 1) 个表示每个像素分类分数的图。随后的 softmax 层输出每个像素的概率。
Category-Aware RPN 与 [47] 中的区域提议网络几乎相同,只是将 2 类(目标或非目标)卷积分类器替换为 (C + 1) 类卷积分类器。它可以被认为是 SSD [40] 的简化版本。
Faster R-CNN [47] 是最先进的检测器。在我们的实现中,RPN 分支被添加到 conv4 块的顶部,跟在 [47] 之后。在之前的实践中 [22, 24],RoI 池化层被插入到 ResNet-101 中的 conv4 和 conv5 块之间,每个 RoI 留下 10 层。这种设计实现了良好的准确性,但具有很高的 per-RoI 计算。相反,我们采用了[38]中的简化设计。最后添加了 RoI 池化层。在池化的 RoI 特征之上,添加了两个维度为 1024 的 fc 层,然后是边界框回归和分类分支。尽管这种简化(从 10 层 conv5 块到 2 层 fc 层)会略微降低准确性,但它仍然是一个足够强大的基线,并且在这项工作中不是一个问题。
可选地,可以将 RoI 池化层更改为可变形 RoI 池化。
R-FCN [7] 是另一种最先进的检测器。它的每个 RoI 计算成本可以忽略不计。我们遵循原来的实现。可选地,它的 RoI 池化层可以更改为可变形位置敏感的 RoI 池化。
; 3. Understanding Deformable ConvNets
这项工作建立在使用额外偏移量增加卷积和 RoI 池中的空间采样位置并从目标任务中学习偏移量的想法之上。
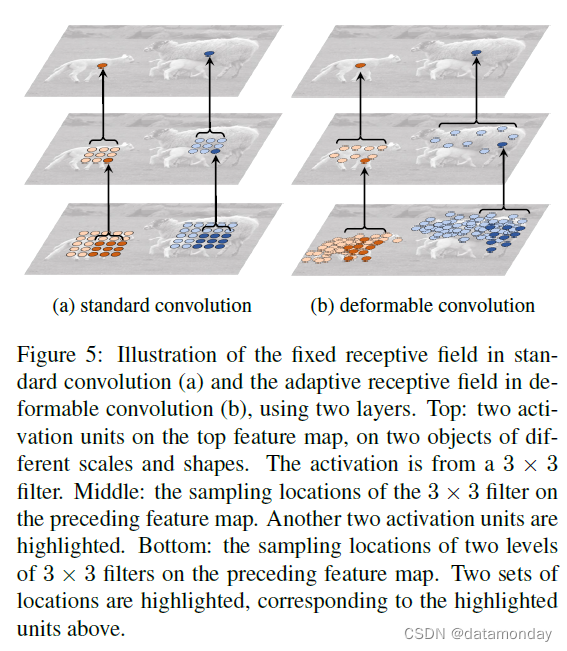
图 5:标准卷积 (a) 中的固定感受野和可变形卷积 (b) 中的自适应感受野的图示,使用两层。顶部:顶部特征图上的两个激活单元,在两个不同尺度和形状的对象上。激活来自 3 × 3 滤波器。中:前面特征图上 3×3 滤波器的采样位置。另外两个激活单元被突出显示。下图:前面特征图上两层 3×3 滤波器的采样位置。两组位置被突出显示,对应于上面突出显示的单位。
当可变形卷积堆叠时,复合变形 (composited deformation) 的效果是深远的。图 5 对此进行了举例说明。 标准卷积中的感受野和采样位置在整个顶部特征图(左)上都是固定的。它们根据可变形卷积中目标的比例和形状进行自适应调整(右)。更多示例如图 6 所示。表 2 提供了这种自适应变形的定量证据。
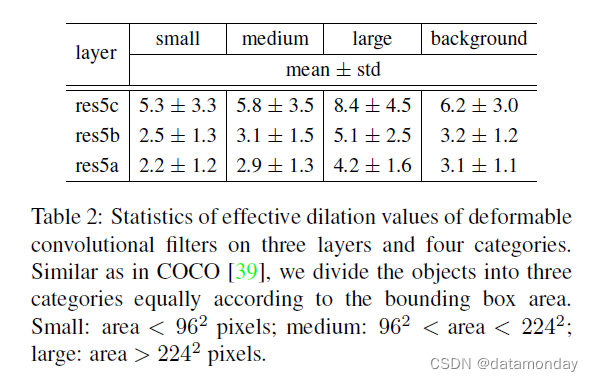
表 2:可变形卷积滤波器在三层四类上的有效膨胀值统计。与 COCO [39] 类似,我们根据边界框区域将对象平均分为三类。小:面积 < 96^2 像素;中:962 < 面积 < 224^2;大:面积 > 224^2 像素。
可变形 RoI 池化的效果类似,如图 7 所示。 标准 RoI 池中网格结构的规律性不再成立。相反,零件会偏离 RoI 箱并移动到附近的目标前景区域。 定位能力得到增强,尤其是 对于非刚性物体 (non-rigid objects)。


3.1. In Context of Related Works
我们的工作在不同方面与以前的工作有关。我们详细讨论了关系和差异。
- 空间变换网络(STN)[26] 这是第一个在深度学习框架中从数据中学习空间变换的工作。它通过仿射变换等全局参数变换来扭曲特征图。
- 这种扭曲是昂贵的,并且 学习变换参数是困难的。 STN 在小规模图像分类问题上取得了成功。 逆 STN 方法 [37] 通过有效的变换参数传播代替了昂贵的特征扭曲。
可变形卷积中的偏移学习可以被认为是 STN [26] 中的一种极轻量级的空间变换器。然而, 可变形卷积不采用全局参数变换和特征扭曲。相反,它 以局部和密集的方式对特征图进行采样。为了生成新的特征图,它有一个加权求和步骤,这在 STN 中是不存在的。
可变形卷积很容易集成到任何 CNN 架构中。它的训练很容易。它 对于需要密集(例如,语义分割)或半密集(例如,目标检测)预测的复杂视觉任务被证明是有效的。对于 STN [26, 37],这些任务很困难(如果不是不可行的话)。
主动卷积 (Active Convolution) [27] 这项工作是当代的。它还使用偏移量增加卷积中的采样位置,并通过端到端的反向传播学习偏移量。它在 图像分类任务上显示有效。
与可变形卷积的两个关键区别使这项工作不那么通用和自适应。
- 首先,它 在不同的空间位置共享偏移量。
- 其次, 偏移量是每个任务或每次训练学习的静态模型参数。相反, 可变形卷积中的偏移量是动态模型输出,每个图像位置都不同。它们 对图像中的密集空间变换进行建模,并且对(半)密集预测任务(例如目标检测和语义分割)有效。
有效感受野 (Effective Receptive Field) [43] 发现并非感受野中的所有像素都对输出响应做出同等贡献。 靠近中心的像素具有更大的影响。有效感受野只占理论感受野的一小部分,呈高斯分布。尽管理论上的感受野大小随着卷积层的数量线性增加,但令人惊讶的结果是,有效感受野大小随着数量的平方根线性增加,因此,速度比我们预期的要慢得多。
- 这一发现表明, 即使是深层 CNN 中的顶层单元也可能没有足够大的感受野。这部分解释了为什么 atrous 卷积 [23] 广泛用于视觉任务(见下文)。它表明了 自适应感受野学习的需求。
- 可变形卷积能够自适应地学习感受野,如图 5、6 和表 2 所示。
- Atrous 卷积 [23] 它将正常滤波器的步幅增大到大于 1,并将原始权重保持在稀疏采样位置。这 增加了感受野大小并在参数和计算中保持相同的复杂性。它已被广泛用于语义分割 [41, 5, 54](在 [54] 中也称为扩张卷积),目标检测 [7] 和图像分类 [55]。
- 可变形卷积是空洞卷积的泛化,如图 1 © 所示。表 3 中给出了与空洞卷积的广泛比较。
Deformable Part Models (DPM) [11] Deformable RoI pooling 与 DPM 相似,因为这两种方法都学习目标部分的空间变形以最大化分类分数。可变形 RoI 池化更简单,因为没有考虑部件之间的空间关系。
- DPM 是一种浅层模型,对变形的建模能力有限。虽然它的推理算法可以 通过将距离变换视为特殊的池化操作来转换为 CNN [17],但它的训练不是端到端的,并且涉及启发式选择,例如组件和零件尺寸的选择。相比之下, 可变形的 ConvNets 很深,可以进行端到端的训练。当多个可变形模块堆叠时,对变形的建模能力变得更强。
- DeepID-Net [44] 它引入了变形约束池化层,该层还考虑了物体检测的部分变形。因此,它与可变形 RoI 池具有相似的精神,但要复杂得多。
- 这项工作是高度工程化的,并且基于 RCNN [16]。目前尚不清楚如何以端到端的方式使其适应最近最先进的目标检测方法 [47, 7]。
- RoI 池化中的空间操作空间金字塔池化 [34] 在尺度上使用手工制作的池区域。它是计算机视觉中的主要方法,也用于基于深度学习的目标检测 [21, 15]。
- 学习池化区域的空间布局很少受到研究。 [28] 中的工作从一个大的过完备集中学习了一个稀疏的池化区域子集。大集合是手工设计的,学习不是端到端的。
- Deformable RoI pooling 是第一个在 CNN 中端到端学习池化区域的方法。虽然目前这些区域的大小相同,但在空间金字塔池 [34] 中扩展到多种大小是很简单的。
变换不变特征及其学习 在设计变换不变特征方面已经付出了巨大的努力。值得注意的例子包括 尺度不变特征变换 (SIFT) [42] 和 ORB [49](O 表示方向)。在 CNN 的背景下有大量这样的作品。在 [36] 中研究了 CNN 表示对图像转换的不变性和等价性。一些作品学习了 关于不同类型转换的不变 CNN 表示,例如 [50],scattering networks [3],convolutional jungles [32] 和 TIpooling [33]。一些作品专门用于特定的变换,例如对称 [13, 9],比例 [29] 和旋转 [53]。
- 正如第 1 节中分析的那样,在这些作品中,转换是先验已知的。知识(例如参数化)用于手工构建特征提取算法的结构,或者固定在 SIFT 中,或者具有可学习的参数,例如基于 CNN 的参数。他们无法处理新任务中的未知转换。
- 相比之下,我们的可变形模块概括了各种变换(见图 1)。变换不变性是从目标任务中学习的。
动态滤波器 (Dynamic Filter) [2] 与可变形卷积类似,动态滤波器也以输入特征为条件并切换样本。不同的是, 只学习了滤波器权重,而不是像我们这样的采样位置。这项工作适用于视频和立体预测。
低级滤波器的组合 高斯滤波器及其平滑导数 [30] 被广泛用于提取低级图像结构,例如角点、边缘、T 形接头等。在某些条件下,此类滤波器形成一组基及其线性组合在同一组几何变换中形成新的滤波器,例如 Steerable Filters [12] 中的多个方向和 [45] 中的多个尺度。我们注意到,尽管 [45] 中使用了可变形内核这个术语,但它的含义与我们在这项工作中的含义不同。
大多数 CNN 从头开始学习所有的卷积滤波器。最近的工作 [25] 表明它可能是不必要的。它通过低级滤波器(最高 4 阶的高斯导数)的加权组合来代替自由形式的滤波器,并学习权重系数。当训练数据较小时,滤波器函数空间上的正则化可以提高泛化能力。
上述工作与我们的工作有关, 当多个滤波器(尤其是具有不同尺度的滤波器)组合在一起时,生成的滤波器可能具有复杂的权重,并且类似于我们的可变形卷积滤波器。然而, 可变形卷积学习采样位置而不是滤波器权重。
- Experiments
4.1. Experiment Setup and Implementation
语义分割。我们使用 PASCAL VOC [10] 和 CityScapes [6]。对于 PASCAL VOC,有 20 个语义类别。按照 [19、41、4] 中的协议,我们使用 VOC 2012 数据集和 [18] 中的附加掩码注释。训练集包括 10582 张图像。对验证集中的 1, 449 张图像进行评估。对于 CityScapes,按照 [5] 中的协议,分别对训练集中的 2975 张图像和验证集中的 500 张图像进行训练和评估。有 19 个语义类别和一个背景类别。
为了评估,我们使用在图像像素上定义的平均交并比 (mIoU) 度量,遵循标准协议 [10, 6]。我们分别对 PASCAl VOC 和 Cityscapes 使用 mIoU@V 和 mIoU@C。
在训练和推理中,图像的大小被调整为 PASCAL VOC 的短边为 360 像素,Cityscapes 的短边为 1024 像素。在 SGD 训练中,每个 mini-batch 中随机抽取一张图像。对 PASCAL VOC 和 Cityscapes 分别进行了 30k 和 45k 次迭代,每个都有 8 个 GPU 和一个 mini-batch。在前 2/3 和最后 1/3 次迭代中,学习率分别为 10-3 和 10-4。
目标检测我们使用 PASCAL VOC 和 COCO [39] 数据集。对于 PASCAL VOC,按照 [15] 中的协议,在 VOC 2007 trainval 和 VOC 2012 trainval 的联合上进行训练。评估基于 VOC 2007 测试。对于 COCO,按照标准协议 [39],分别对 trainval 中的 120k 图像和 test-dev 中的 20k 图像进行训练和评估。
对于评估,我们使用标准平均精度 (mAP) 分数 [10, 39]。对于 PASCAL VOC,我们使用 0.5 和 0.7 的 IoU 阈值报告 mAP 分数。对于COCO,我们使用mAP@[0.5:0.95]的标准COCO度量,以及mAP@0.5。
在训练和推理中,图像的大小被调整为具有 600 像素的较短边。在 SGD 训练中,每个 mini-batch 中随机抽取一张图像。对于类感知 RPN,从图像中采样了 256 个 RoI。对于 Faster RCNN 和 R-FCN,分别为区域提议和目标检测网络采样了 256 和 128 个 RoI。在 RoI pooling 中采用 7 × 7 bins。为了促进 VOC 的消融实验,我们遵循 [38] 并利用预训练和固定的 RPN 提议来训练 Faster R-CNN 和 R-FCN,而区域提议和目标检测网络之间没有特征共享。 RPN 网络是单独训练的,如 [47] 中程序的第一阶段。对于 COCO,执行 [48] 中的联合训练,并为训练启用特征共享。在 8 个 GPU 上,PASCAL VOC 和 COCO 分别进行了 30k 和 240k 次迭代。在前 2/3 和最后 1/3 次迭代中,学习率分别设置为 10-3 和 10-4。
4.2. Ablation Study
进行了广泛的消融研究以验证我们方法的有效性和效率。
可变形卷积表 1 使用 ResNet-101 特征提取网络评估可变形卷积的效果。 当使用更多可变形的卷积层时,准确度稳步提高,尤其是对于 DeepLab 和类感知 RPN。当 DeepLab 使用 3 个可变形层,其他可变形层使用 6 个时,改进达到饱和。在剩下的实验中,我们在特征提取网络中使用了 3。
我们凭经验观察到, 可变形卷积层中的学习偏移对图像内容具有高度自适应性,如图 5 和图 6 所示。为了更好地理解可变形卷积的机制,我们 为可变形卷积滤波器定义了一个称为有效膨胀的度量。它是 滤波器中所有相邻采样位置对之间距离的平均值。它是对滤波器感受野大小的粗略测量。
我们在 VOC 2007 测试图像上应用具有 3 个可变形层的 R-FCN 网络(如表 1 所示)。我们 根据真实边界框标注和滤波器中心的位置将可变形卷积滤波器分为四类:小、中、大和背景。表 2 报告了有效膨胀值的统计数据(平均值和标准差)。它清楚地表明:
1) 可变形滤波器的感受野大小与目标大小相关,表明变形是从图像内容中有效学习的;
2) 背景区域的滤波器大小介于中等和大型物体之间,表明识别背景区域需要相对较大的感受野。这些观察结果在不同层次上是一致的。
默认的 ResNet-101 模型对最后三个 3 × 3 卷积层使用带扩张 2 的空洞卷积(参见第 2.3 节)。我们进一步尝试了扩张值 4、6 和 8,并在表 3 中报告了结果。它表明:
1) 当使用较大的扩张值时,所有任务的准确性都会提高,这表明默认网络的感受野太小;
2) 不同任务的最佳扩张值不同,例如,DeepLab 为 6,Faster R-CNN 为 4;
3) 可变形卷积具有最好的精度。这些观察结果验证了滤波器变形的自适应学习是有效且必要的。
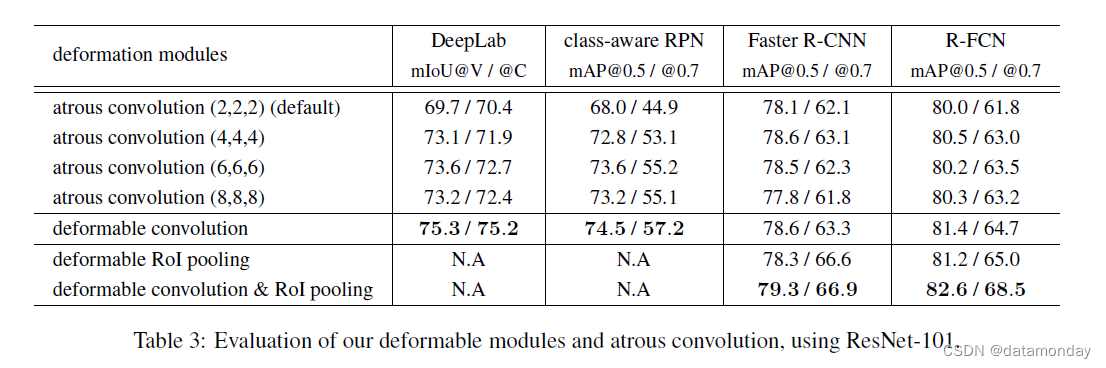
Deformable RoI Pooling 适用于 Faster RCNN 和 R-FCN。如表 3 所示,单独使用它已经产生了显着的性能提升,尤其是在严格的 mAP@0.7 指标下。当同时使用可变形卷积和 RoI Pooling 时,可以获得显着的精度提升。
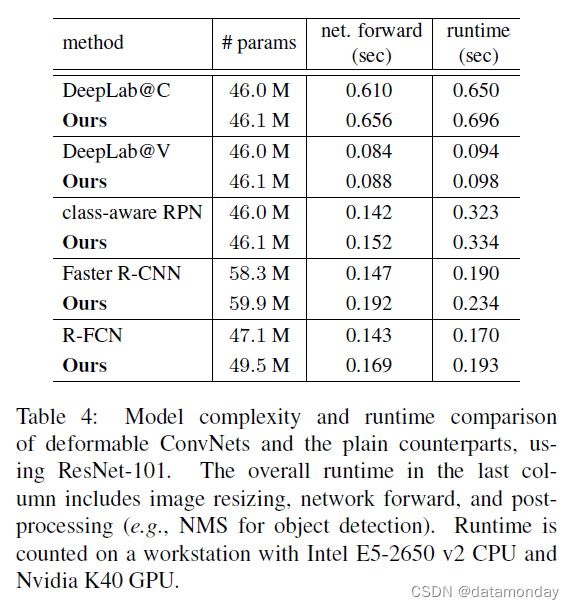
模型复杂性和运行时间 表 4 报告了所提出的可变形卷积网络及其普通版本的模型复杂性和运行时间。可变形卷积网络仅在模型参数和计算上增加了很小的开销。这表明显着的性能改进来自建模几何变换的能力,而不是增加模型参数。
; 4.3. Object Detection on COCO
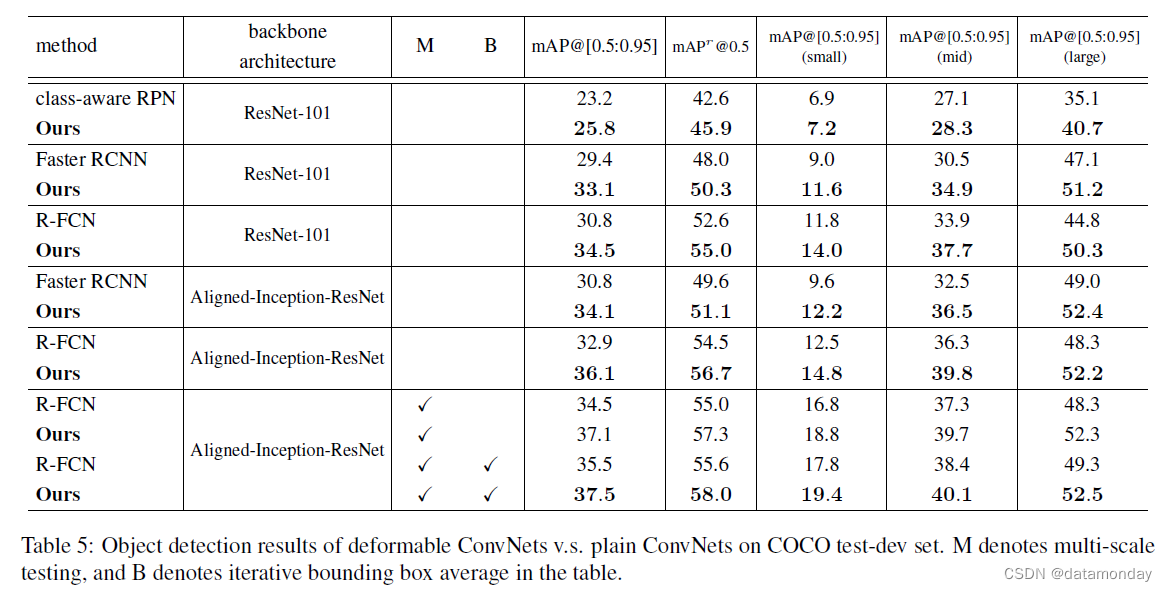
在表 5 中,我们在可变形卷积网络和普通卷积网络之间进行了广泛的比较,以在 COCO 测试开发集上进行目标检测。我们首先使用 ResNet-101 模型进行实验。 class-aware RPN、Faster R-CNN 和 R-FCN 的可变形版本的 mAP@[0.5:0.95] 分数分别为 25.8%、33.1% 和 34.5%,相对提高了 11%、13% 和 12%分别高于他们的plainConvNets同行。通过在 Faster R-CNN 和 RFCN 中将 ResNet101 替换为 Aligned-Inception-ResNet,由于更强大的特征表示,它们的 plain-ConvNet 基线都得到了改善。可变形卷积网络带来的有效性能提升也成立。通过在多个图像尺度上进一步测试(图像较短的边在 [480, 576, 688, 864, 1200, 1400])并执行迭代边界框平均 [14],mAP@[0.5:0.95] 分数增加到R-FCN 的可变形版本为 37.5%。请注意, 可变形 ConvNets 的性能增益与这些花里胡哨的东西是互补的。
- Conclusion
本文介绍了可变形 ConvNets,它是一种简单、高效、深度和端到端的解决方案,用于对密集空间变换进行建模。我们第一次表明, 在 CNN 中学习密集空间变换来完成复杂的视觉任务是可行且有效的,例如目标检测和语义分割。
A. Deformable Convolution/RoI Pooling Backpropagation
在可变形卷积公式 (2) 中,偏移量 Δpn 梯度计算为
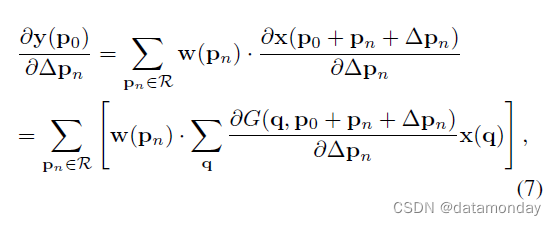
其中 ∂G(q,p0+pn+Δpn)/∂Δpn 项可以从公式 (4) 推导出来。请注意,偏移量 Δpn 是 2D 的,为了简单起见,我们使用 ∂Δpn 来表示 ∂Δpxn 和 ∂Δpyn。
关于偏移量 Δpij 的梯度可以通过下式计算
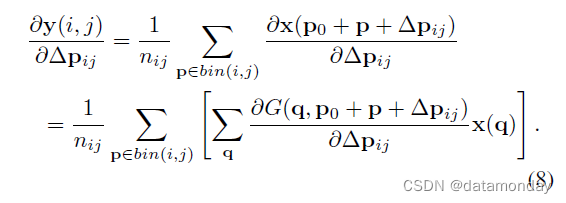
通过计算 Δ p i j = γ ⋅ Δ p ^ i j ◦ ( w , h ) Δp_{ij} = γ · Δ\hat{p}{ij} ◦ (w, h)Δp i j =γ⋅Δp ^i j ◦(w ,h ) 中的导数,可以很容易地获得关于归一化偏移量 Δ p i j Δp{ij}Δp i j 的梯度。
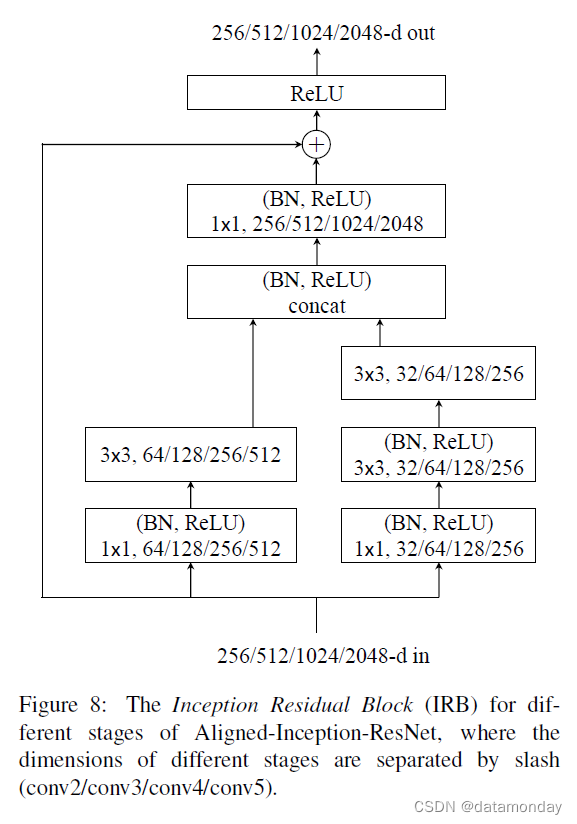
; B. Details of Aligned-Inception-ResNet
在原始的 Inception-ResNet [51] 架构中,利用了多层有效的卷积/池化,这为密集预测任务带来了特征对齐问题。对于特征图上靠近输出的单元,其在图像上的投影空间位置与其感受野中心的位置不对齐。同时,任务特定的网络通常是在对齐假设下设计的。例如,在用于语义分割的流行 FCN 中,利用单元格的特征来预测相应投影图像位置处的像素标签。
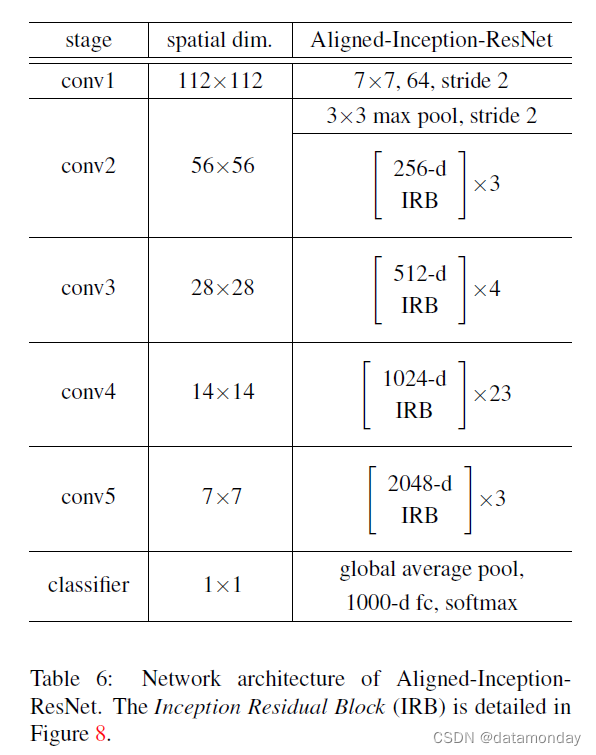
为了解决这个问题,修改了网络架构 [20],称为”Aligned-Inception-ResNet”,如表 6 所示。当特征维度发生变化时,使用步长为 2 的 1×1 卷积层。 Aligned-Inception-ResNet 和原始的 Inception-ResNet [51] 之间有两个主要区别。首先,AlignedInception-ResNet 没有特征对齐问题,通过在卷积层和池化层中进行适当的填充。其次,Aligned-Inception-ResNet 由重复的模块组成,其设计比原始的 Inception-ResNet 架构更简单。
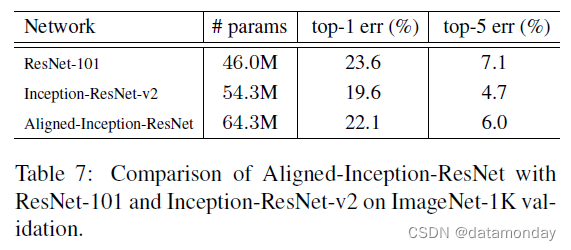
Aligned-Inception-ResNet 模型在 ImageNet-1K 分类 [8] 上进行了预训练。训练过程遵循[22]。表 7 报告了模型复杂度、top-1 和 top-5 分类错误。
Original: https://blog.csdn.net/weixin_39653948/article/details/124787684
Author: datamonday
Title: 【CV】可变形卷积:用于目标检测和语义分割的卷积层
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681651/
转载文章受原作者版权保护。转载请注明原作者出处!