

一. 任务介绍
收到一个任务,对交通场景中的图片进行目标检测,要能识别出指定的6个类别物品在图中的位置。比如要识别下图中的小汽车、行人、自行车、卡车等。
比如下图:


经过识别后,如图所示:

经过目标检测模型预测的图片
本系列文章共两篇,总结记录了一个计算机视觉小白,如何一步一步完成这个任务的过程,分为原理篇和实践篇,包括目标检测的原理和算法的学习;模型选择并在公开的数据集合上体验;利用模型在自己的数据集上训练、调试参数、训练加速、结果衡量等过程。
要想学透东西,我认为最好的办法还是亲自动手做一遍,解决遇到的每个问题。就像我国一首古诗所写: 纸上得来终觉浅,绝知此事要躬行。做好准备,我们要开始我们的学习之旅了。
首先我们要搞明白在计算机视觉里目标检测究竟是什么?目标检测的原理是什么?
二. 什么是目标检测?
目标检测的任务是找出图像中所有感兴趣的目标(物体),确定他们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状、姿态,再加上光照、遮挡等因素的干扰,目标检测在计算机视觉中也是一项具有挑战性的任务。
机器视觉中关于目标检测有4大类任务:
- 分类(Classification):给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位(Location):定位出这个目标的的位置。
- 检测(Detection):即定位出这个目标的位置并且知道目标物是什么。
- 分割(Segmentation):分为实例的分割(Instance-level)和场景分割(Scene-level),解决”每一个像素属于哪个目标物或场景”的问题。
这4大类任务结果如图所示:

我们要解决的目标检测任务,是一个分类问题和回归问题的叠加,分类是区分目标属于哪个类别,回归用来定位目标所在的位置。
那么,目标检测的性能评估指标都有哪些呢?常用的方法有哪些呢?
三. 目标检测方法的性能评估方法
我们先思考下,图像分类问题的性能衡量用准确率就够了。比如,一个小狗的图片,我们准确地把狗识别出来。但是,这个图像分类的衡量指标不能直接用在目标检测上,因为每张图片中可能含有不同类别的不同目标。
目标检测算法的预测结果应该包含:图像、图像中的目标类别、以及每个目标的边框位置。我们用这个结构的数据和验证集的数据进行比较,来衡量目标检测的质量。例如:我们给定图片和一些边框、分类名称等解释性文字,如下:

对于这个图片,模型在训练时得到的图片可能是这样的:

以及3组解释性数据,包含分类结果、边框的坐标数据、边框的宽和高。如下图所示(假设图中的坐标数据和宽高数据单位都是像素):
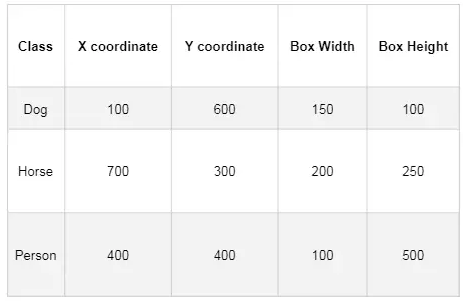
训练好的模型会在一张图上产生很多这样的预测结果,但是大多数的结果置信度都不高,只需要考虑那些超过某个置信度的预测结果。
那么,我们要怎么量化预测结果的正确性呢?
能够告诉我们每个预测结果框正确性的指标,是”交并比”(Intersection over Union, IoU)。
- 什么是IoU呢?
交并比是预测边界框和标注数据边界框的交集和并集之间的比率,这个统计量也叫做 Jaccard 指数(Jaccard Index)。要获得交集和并集的值,我们首先把预测边界框覆盖在参考边界框之上,如图:

现在对于每个类别,预测边界框和标注数据边界框的重叠部分叫做交集,而两个边界框跨越的所有区域叫做并集。
比如,图中的马,看起来是这样的:
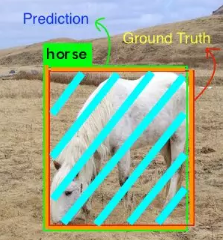
这个例子中交集区域相当大,交集覆盖的是边界框重合区域(蓝绿色区域),并集覆盖的是橙色和蓝绿色的所有区域。
然后,IoU是这样计算的:

利用IoU,我们就能判断检测结果是否正确,常用的阈值是0.5。 如果IoU > 0.5,就认为是一个正确的检测,否则就认为是一个错误的检测。注意:这里的0.5只是一个人为经验值,根据不同的场景要做调整。为了学习方便起见,我们先用0.5,等学会了再调整也不迟。
- 什么是精确率呢?
现在,我们为模型生成的每一个检测边框计算其IoU值,利用该IoU数值和阈值,我们为图片中的每一个类计算其正确检测的数量A。对于每张图片,我们都有标准数据,可以告诉我们在图片中某个特定类别的真实数量B,那么A/B就是该类别的预测精确率了。
比如,给定的图片中类别C的精确率=图片中类别C的真正类数量/图片中类别 C 所有目标的数量。

- 什么是平均精度呢?
对于一个给定的类别,让我们对验证集中的每张图片都计算它的精确率。假设我们的验证集中有 100 张图片,并且我们知道每张图片都包含了所有的类别(根据参考标准告诉我们的信息)。这样对于每个类别,我们会有 100 个精度率的值(每张图片一个值)。让我们对这些 100 个值进行平均。这个平均值叫做该类的平均精度(Average Precision)。
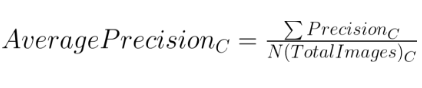
某个类别的平均精度 = 验证集中该类的所有精确率的和 / 含有该类别目标的图像数量。
- 什么是平均精度均值呢?
假设我们有20个类别,对每一个类别,我们都进行相同的计算流程:IoU -> 精确率(Precision) -> 平均精度(Average Precision)。这样就有20个类别的平均进度,我们对所有类别的平均精度值计算其均值(average/mean)。这个新的值,就是我们的平均精度均值 mAP。 (Mean Average Precision)

平均精确度均值 = 所有类别的平均精度值之和/所有类别的数目。
平均精度均值(mAP,Mean Average Precision)是预测目标位置和类别的性能度量标准。我们的任务也将采用平均精度均值作为性能衡量指标。
在确定了算法性能度量后,我们来看看常用目标检测的算法有哪些?
四. 目标检测的算法
基于深度学习的目标检测算法分为2类:Two Stage和One Stage。
- Two Stage:先预设一个区域,改区域称为region proposal,即一个可能包含待检测物体的预选框(简称RP),再通过卷积神经网络进行样本分类计算。流程是:特征提取 -> 生成RP -> 分类/回归定位。常见的Two Stage算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN等。
-
One Stage:不用生成RP,直接在网络中提取特征值来分类目标和定位。流程是:特征提取 -> 分类/回归定位。常见的One Stage算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、YOLOv5、SSD、RetinaNet等。
-
利用滑动窗口生成RP
对于Two Stage的算法,RP的产生是一个很耗时的过程:通过一个窗口从左到右,从上到下的在整张图片上以一定的步长进行滑动扫描,每次滑动的时候对当前窗口执行分类计算,如果当前窗口得到较高的概率,则认为检测到了物体。过程如下图所示,这个方法也叫滑动窗口。

滑动窗口其实就是个穷举的过程,由于事先不知道要检测的目标大小,所以要设置不同大小比例的窗口去滑动,而且要选取合适的步长。这样做就会非常耗时。R-CNN就是针对此的一个改进策略,利用一种启发式的方法只扫描可能包含目标的子区域。
- 利用非极大值抑制算法来挑出最优解
不管是哪个目标检测的算法,一个目标都会被多次检测到,我们会有很多结果,但是大多数的结果置信度都不高,我们利用非极大值抑制算法(NMS)就能挑出那个置信度最好的结果。如下图所示:
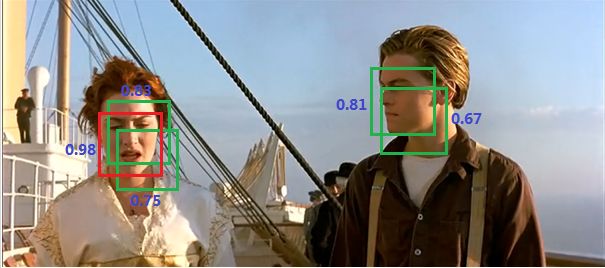
可以看到人脸被多次检测(红色框和绿色框),但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于图中的Rose,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IoU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。
- 算法选择
那么我们该选择哪个算法来完成我们的任务呢?
我们需要根据前文确定的性能衡量指标,对所有的算法做横向对比,这样才能挑出来最好的那个方法。这个过程会比较耗时,对于我们完成任务将会是一个障碍,庆幸的是这个比较已经有牛人帮我们做了,我们此时先使用结果,然后在将来有时间自己再尝试做这个横向的性能比较。
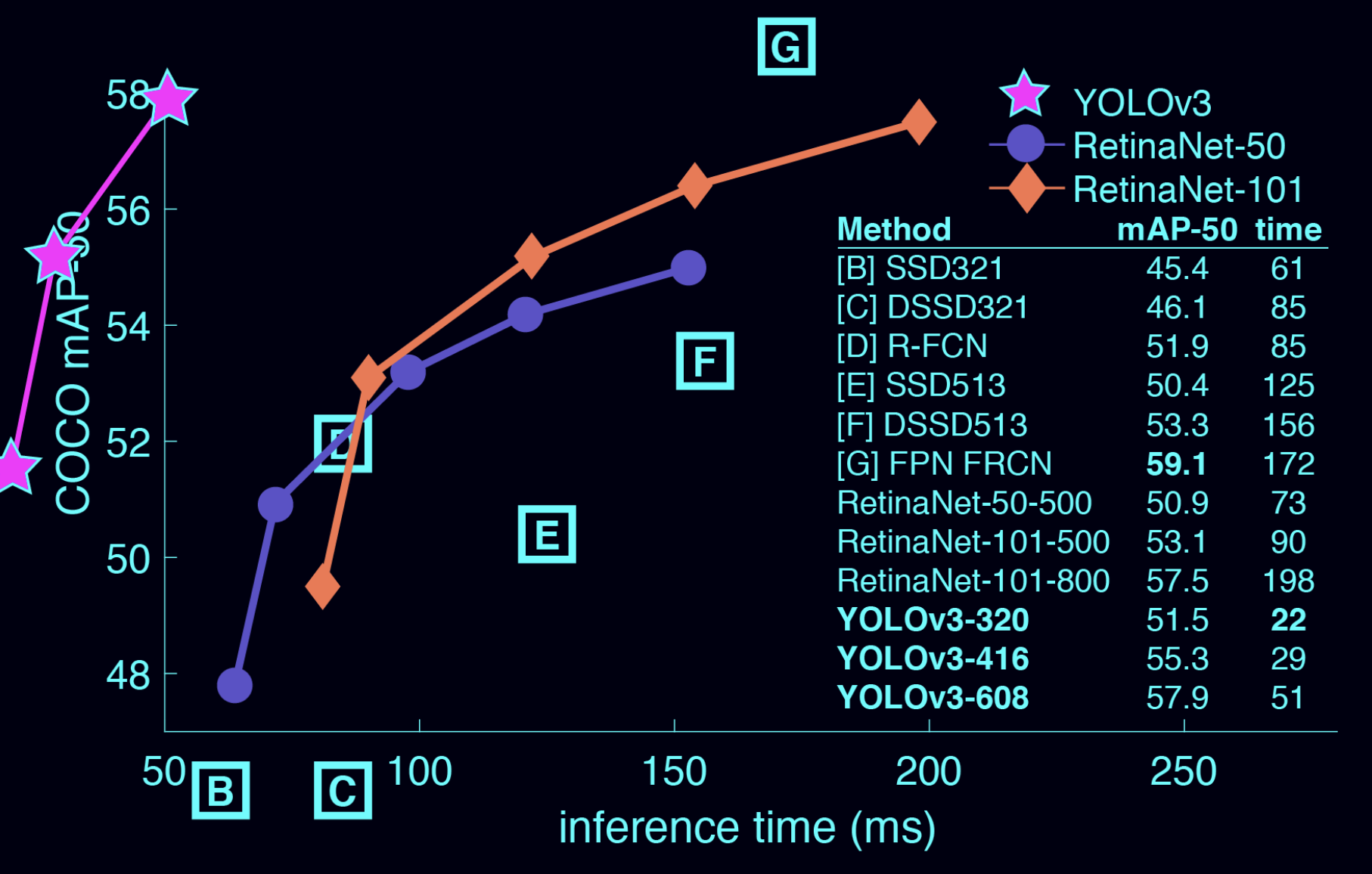
这是一张根据mAP和识别时间对各种目标检测算法做的结果统计图,如果单从mAP的角度看,最好的选择是FPN FRCN,但是交互时间却能达到172ms;如果看YOLOv3,mAP是57.9,交互时间只有51ms。所以我们的识别算法选用YOLOv3。
五. YOLOv3原理
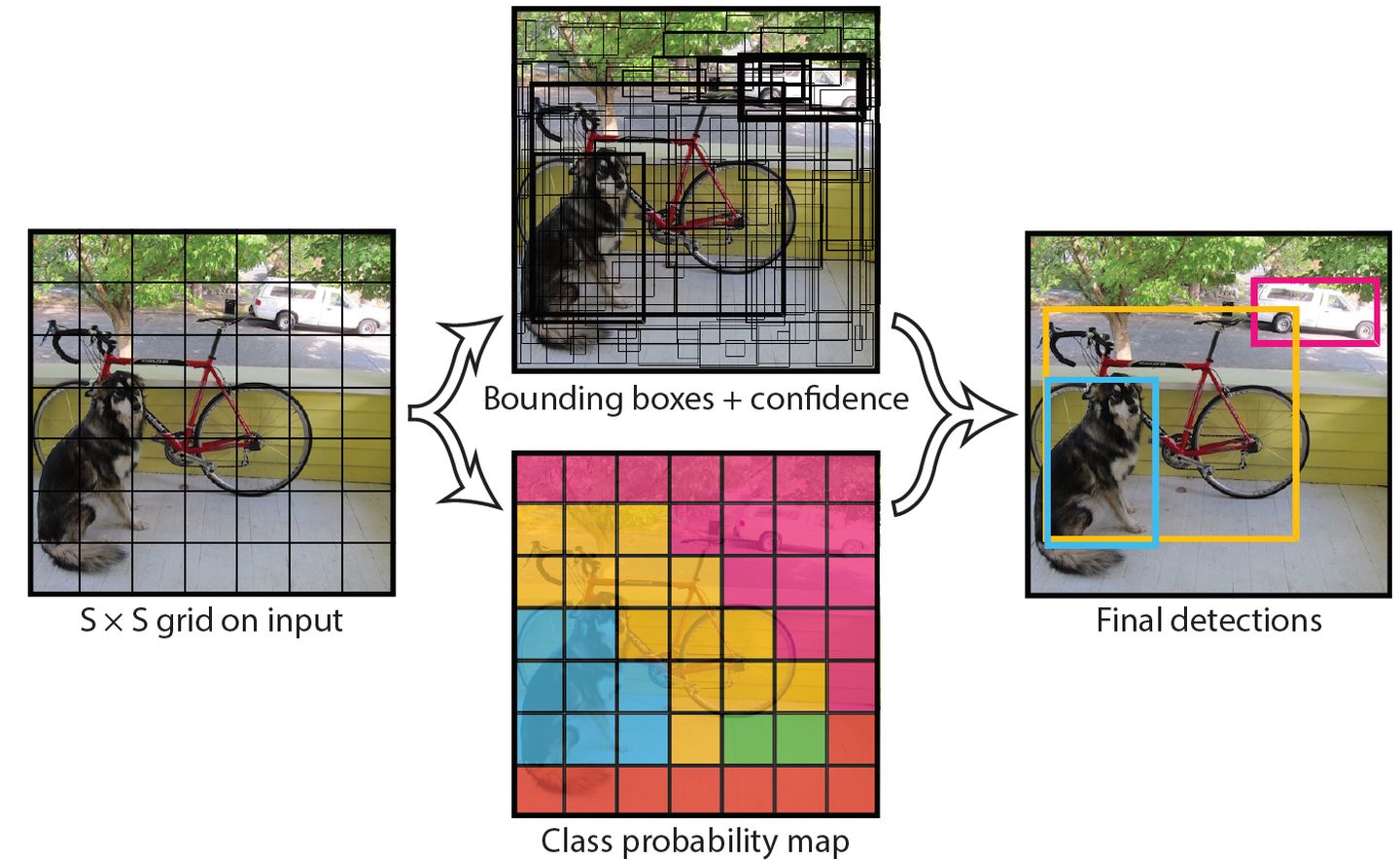
YOLO是You Only Look Once的简称,它不使用窗口滑动,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
整体来看,YOLO算法采用一个单独的CNN模型实现目标检测,整个系统如图所示:

首先将输入图片尺寸调整到448×448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。
YOLO的CNN把输入的图片分割成
的网格,然后每个单元格负责去检测那些中心点落在该格子内的目标。如下图所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会生成预测值,当该边界框是背景时(即不包含目标),此时。而当该边界框包含目标时,。边界框的准确度可以用IoU来表征,记为 。因此置信度可以定义为。很多人可能将YOLO的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x, y, w, h),其中(x, y)是边界框的中心坐标,而(w, h)是边界框的宽与高。还有一点要注意,中心坐标的预测值是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如下图所示。而边界框的预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0, 1]范围。这样,每个边界框的预测值实际上包含5个元素:(x, y, w, h, c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。对于每一个单元格其还要给出预测出C个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率,即。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores):。边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。

总结下,每个单元格需要预测 (B * 5 + C) 个值。如果将输入图片划分为
网格,那么最终预测值为大小的张量。整个模型的预测值结构如下图所示:
六. YOLO网络设计
YOLO采用卷积网络来提取特征,使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层。对于卷积层,主要使用1×1卷积来做channle reduction,然后紧跟3×3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数,但是最后一层却采用线性激活函数。如图所示:

七. YOLO网络训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用上图中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224×224增加到了448×448。如图所示:

目标检测的原理和YOLO原理就到此了,更多的细节可以找更多资料阅读。
那么接着的问题是如何开始用YOLO识别图片呢?我的想法是先通过学习YOLO项目,用公开的数据集进行训练,再实现自己的训练集训练。后续的实践部分将在下篇文章中讲述。
Original: https://blog.csdn.net/guohuang/article/details/122951195
Author: guohuang
Title: 从0开始实现目标检测——原理篇
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681474/
转载文章受原作者版权保护。转载请注明原作者出处!