

Abstract:
SSD在许多特定位置生成具有不同的高宽比和size的锚框,通过预测锚框的类别和与与之对应真实边缘框的偏差来训练网络。SSD可以实现多尺度目标检测。SSD比two-stage的目标检测算法更简单。SSD在许多数据集上超越了Faster R-CNN,并且与其他one-stage方法相比,SSD在输入图像尺寸较小的情况下,具有更高的精度。
1.Introduction(研究现状)
Faster R-CNN虽然准确,但对于嵌入式系统来说计算量太大,即使是在高端硬件上,对于实时应用程序来说也太慢。有人想要优化,但到目前为止,显著提高速度只是以显著降低检测精度为代价的。
本文提出了第一个基于深度网络的目标检测器,检测速度显著提升。检测速度的提升来源于取消bounding box proposals(候选框)。我们的改进包括使用一个小型卷积滤波器来预测物体类别和边界框位置的偏移量,使用独立的预测器(过滤器)用于不同的宽高比检测,并将这些过滤器应用于网络的后期阶段的多个特征图,以便在多个尺度上执行检测。通过这些修改——特别是在不同尺度下使用多层预测——我们可以在相对低分辨率的输入下实现高精度,进一步提高检测速度。
We summarize our contributions as follows:
SSD比其他one-stage检测器(例如YOLO)更快,和two-stage相比一样准确。
SSD的核心是将卷积过滤器应用于特征图去预测(锚框的)类别得分和与真实边缘框的偏差。
为了达到较高的检测精度,我们从不同尺度的特征图中生成不同尺度的预测,即多尺度检测。
这些设计特性带来了简单的端到端训练和高精度,甚至在低分辨率输入图像,进一步提高速度和精度的折衷。
实验包括在PASCAL VOC、COCO和ILSVRC上不同输入尺寸下评估模型的时间和精度,并与一系列最新的最先进的方法进行比较。
2.The Single Shot Detector (SSD)(这一段主要讲了模型和训练时的技巧)
SSD在训练时只需要一个输入图像和每个对象的ground truth boxes(真实边缘框)。以一种卷积的方式,我们评估在几个不同尺度的特征图的每个位置上的一组不同长宽比的锚框。对于每个锚框,我们预测所有对象类别的置信度和偏移量。在训练时,我们首先将这些锚框与真实边缘框进行匹配。模型损失是定位损失和置信度损失(如Softmax)之间的加权和。
2.1Model
SSD方法基于前馈卷积网络,生成一些固定大小的锚框集合,并为这些锚框中存在的对象分类评分,然后进行非极大值抑制步骤,以生成最终检测。最前面的网络层基于用于高质量图像分类的标准体系结构(用于提取特征得到第一个特征图,因为后面的所有特征图都是在第一个特征图基础上得到的,所以第一个特征图比较重要,需要使用比较好的网络提取特征),我们将其称为base network。然后我们在网络中添加辅助结构,以产生具有以下关键特征的检测:
Multi-scale feature maps for detection:在截断的基础网络的末端添加了卷积特征层,这些层的大小逐渐减少,并允许在多个尺度上预测探测。对于每个特征层,用于分类和回归的卷积模型是不同的。
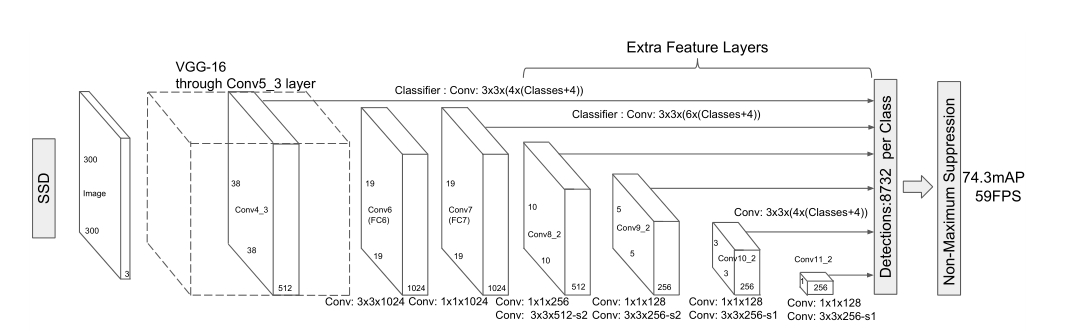

Convolutional predictors for detection(用于检测的卷积预测器):每一个添加的特征层都可以使用一组卷积过滤器产生一组分类和回归。用于预测的内核可以生成类别的分数和相对于默认框的偏移量。在每个像素上,它生成一组输出值。(YOLO采用了全连接层而不是卷积实现这一功能)
Default boxes and aspect ratios(锚框和宽高比):对于每个特征图可以产生不同宽高比(这里应该是size)的锚框。
2.2 Training
训练SSD和训练使用特征提取的典型检测器(two-stage)之间的关键区别是,真值信息需要分配到锚框。一旦确定了这个分配,损失函数和反向传播就端到端应用。训练还包括选择用于检测的锚框和尺度集,以及hard negative mining和数据增强策略。(hard negative mining就是多找一些hard negative加入负样本集)
Matching strategy:我们首先将每个真实边缘框匹配到与之具有最佳jaccard重叠的锚框。与MultiBox不同的是,我们将锚框匹配到任何具有大于阈值(0.5)的jaccard重叠的真实边缘框。这简化了学习问题,允许网络预测多个重叠默认框的高分,而不是只选择最大重叠的那个。
Training objective:总体损失函数为定位损失(loc)和置信度损失(conf)的加权和。
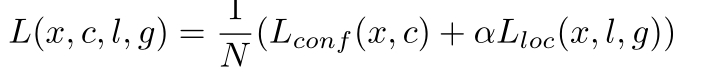
其中N是匹配的锚框数。如果N=0,设损失为0。使用平滑L1损失函数计算位置损失。
类别损失采用softmax函数计算。
通过交叉验证,权重项α设为1。
Choosing scales and aspect ratios for default boxes(为锚框选择尺寸和比例):
每个特征图的锚框的size计算为:
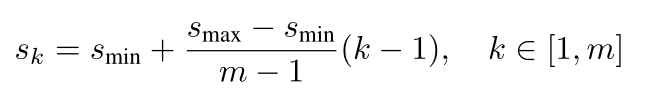
最小值是0.2,最大值是0.9。
比例为:
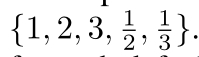
每个特征图的每个位置都会产生不同尺寸和比例的组合的锚框。
Hard negative mining(hard negative mining就是多找一些hard negative加入负样本集):
在匹配步骤之后,大多数锚框都是负样本,这会导致正样本和负样本数量不平衡。我们不使用所有的负样本,而是使用每个锚框的最高置信度损失进行排序,并选择最上面的,这样负数和正数的比例最多为3:1。
Data augmentation:
为了使模型对不同的输入对象大小和形状具有更强的鲁棒性,每个训练图像通过以下选项之一随机采样:
1.使用整个原始输入图像。
2.对图像进行采样,使其与物体的重叠最小为0.1、0.3、0.5、0.7或0.9。
3.随机采样。
3.Experimental Results(这一段主要讲了在多种数据集上的实验结果)
Base network
VGG16并做了修改。SGD。动量0.9。初始学习率0.001。weight decay是0.0005。batch size 32。
3.1 PASCAL VOC2007
我们很好。对于小目标的检测不好。
这并不奇怪,因为这些小对象在最顶层甚至可能没有任何信息。增加输入大小(例如300×300to512×512)可以帮助改进对小对象的检测,但仍有很大的改进空间。从积极的方面来看,我们可以清楚地看到SSD在大型对象上的性能非常好。它对于不同的物体长宽比非常健壮,因为我们在每个特征地图位置使用不同长宽比的默认框。
3.2 Model analysis(分析对模型影响大的因素)
为了更好地理解SSD,我们进行了控制实验,以检查每个组件如何影响性能。对于所有的实验,我们使用相同的设置和输入大小(300×300),除了对设置或组件的指定更改。
Data augmentation is crucial:展示了锚框大小和宽高比对于模型检测不同类别目标的灵敏度的影响。
更多的锚框形状会更好。
Atrous(空洞卷积)更快:
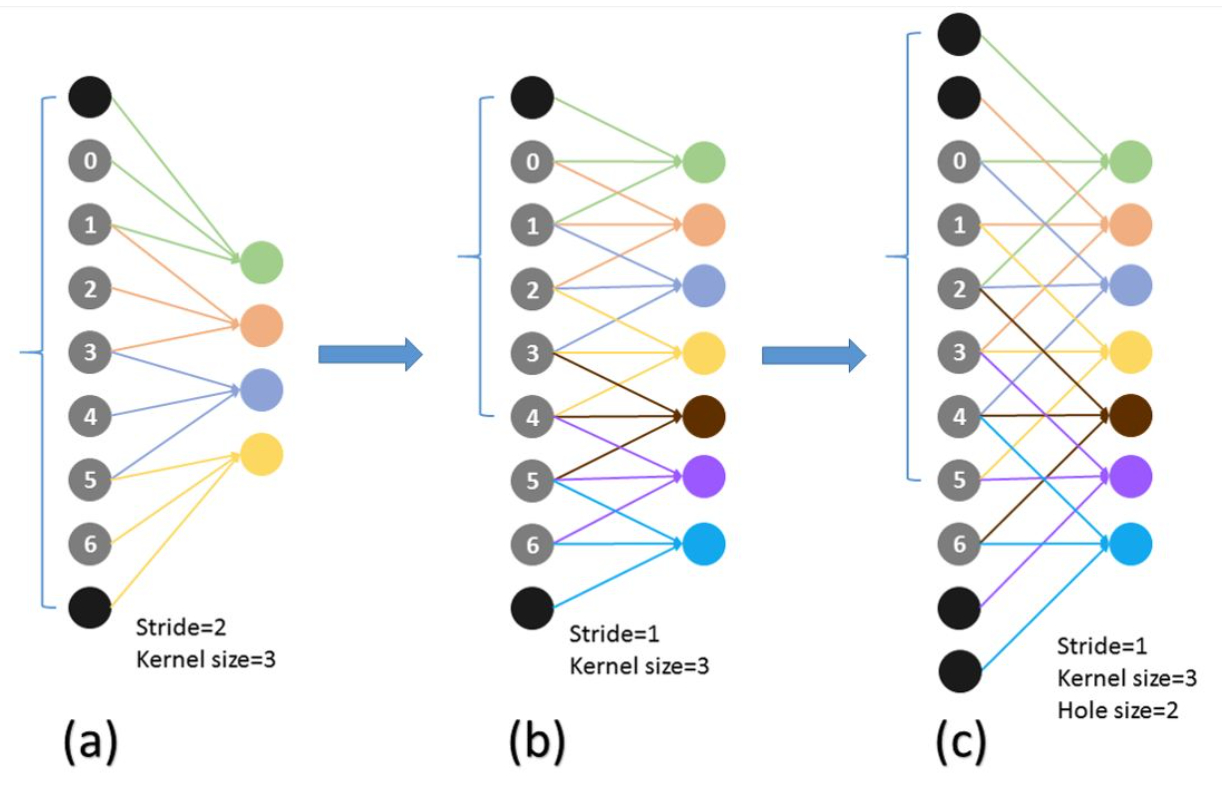
带洞卷积的有效性基于一个假设:紧密相邻的像素几乎相同,全部纳入属于冗余,不如跳H(hole size)个取一个。感受野更大。
不同分辨率的多个输出层更好(多尺度更好):SSD的主要贡献是在不同的输出层上使用不同size的锚框。
3.3 PASCAL VOC2012
我们很好。
3.4 COCO
我们很好,对于小目标的检测没有Faster RCNN效果好。
3.5 Preliminary ILSVRC results
再次验证了SSD是高质量实时检测的通用框架。
3.6 Data Augmentation for Small Object Accuracy
Without a follow-up feature resampling step as in Faster R-CNN, the classification task for small objects is relatively hard for SSD。
数据增强:随机放大。在放大之前需要得到许多小目标。即缩小—–>随机裁剪——->放大。
新的增强技巧显著提高了对小对象的性能。这一结果强调了数据增强策略对最终模型精度的重要性。
改进SSD的一种方法:设计更好的锚框,使其位置和尺寸可以更好地拟合特征图上每个位置的接受域。
3.7 Inference time(做出推断)
考虑到SSD会产生大量的框,在预测过程中有效地执行非最大值抑制(nms)是非常必要的。
比较了速度和精度,我们综合是最好的,SSD300 is the only real-time detection method that can achieve above 70% mAP 。
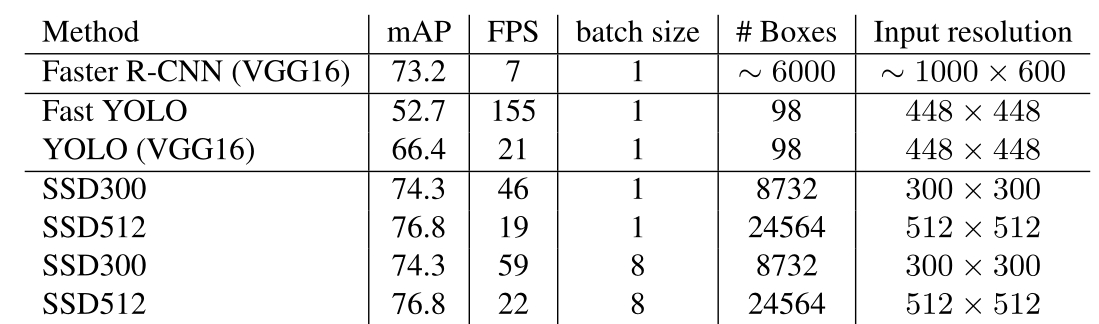
我们的80%的时间是花在了Base Network(VGG16)上,Therefore, using a faster base network could even further improve the speed, which can possibly make the SSD512 model real-time as well.
4.Related Work
There are two methods for object detection in images,基于滑动窗口的目标检测方法和基于候选区域的目标检测方法。在卷积神经网络出现之前,这两种方法的性能差不多。随着RCNN将候选区域与卷积网络相结合,带来了巨大的改进之后,基于候选区域的目标检测方法开始流行起来。
讲了一下目标检测各算法的发展(改进)。
SSD主要是去掉了候选区域步骤,并且支持多尺度。
5 Conclusions
本文介绍了SSD,一种快速的 single-shot 多类别目标检测器。我们模型的一个关键特征是使用了多尺度目标检测。我们通过实验验证了给定适当的训练策略,大量精心选择的锚框会提高性能。我们建立的SSD模型至少比现有方法多一个数量级的锚框采样位置、尺度和宽高比。我们证明,在相同的VGG-16基础架构下,SSD在精度和速度方面优于目前最先进的目标探测器。我们的SSD512模型在PASCAL VOC和COCO数据集上的准确性显著优于最新的Faster R-CNN3倍。我们的实时SSD300模型运行在59fps,这比当前的实时YOLO更快,同时精度更高。
除了它的独立应用,我们相信我们的相对简单的SSD模型为使用目标检测组件的大型系统提供了有用的构建块。一个很有前途的未来方向是探索其作为系统的一部分使用循环神经网络检测和跟踪视频中的目标。我们太强啦!
6 Acknowledgment
致谢……
References
……………………….
SSD真的强,可惜作者放弃了………
Original: https://blog.csdn.net/qq_41825891/article/details/121363891
Author: 我还是你多年
Title: SSD论文解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681051/
转载文章受原作者版权保护。转载请注明原作者出处!