

机器学习分类器——案例(opencv sklearn svm ann python)
ps:最近师姐给我们留了一个任务,记录一下从一开始的什么都不懂到现在把任务做出来,并从中学习到的东西吧。。。。
语言环境python3.7,用到的库
import os
import cv2
import math
import time
import numpy as np
import tqdm
from skimage.feature import hog
from sklearn import svm,datasets,metrics
import matplotlib.pyplot as plt
from skimage import feature as ft
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import *
from sklearn import tree,neighbors
from xgboost import XGBClassifier
from sklearn.base import TransformerMixin,BaseEstimator
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import CategoricalNB,GaussianNB
from sklearn.model_selection import cross_val_score
from yellowbrick.classifier.rocauc import roc_auc
import joblib
任务要求:给定数据集train和test文件夹,其中文件夹中包含四个文件夹(后来才知道是对应于多分类的四个类别),数据格式是图片(也是后来才知道已经灰度处理过了)
小插曲:本来想展示一下文件夹层及目录,奈何图片过多,效果并不好,记录一下获取文件结构图的方法吧。
1.win+R cmd
2.进入想要展示的文件夹内
3.输入tree/f>file.txt命令,在响应的文件夹下生成txt文件可以看到文件结构图。
数据集目录结构:


ps:一开始什么都不懂,后来读文献知道了处理问题的整体思路,先来说一下整体思路吧。
整体思路:

数据预处理
方法:我的理解是把图片的像素变成0和255,来分割目标区域(细胞核),后面特征提取可以用到。
知识点:(方法原理可进一步了解)
直方图均衡化( Histogram Equalization):一种增强图像对比度的方法。
滤波: 尽量保留图像细节特征的条件下对目标图像的噪声进行抑制 , 消除图像中的噪声成分叫作图像的平滑化或滤波操作 。种类:均值滤波、中值滤波
图像的阈值分割:基于区域的图像分割技术,原理是把图像像素点分为若干类。本次采用ostu法或者迭代法计算阈值(很多种方法)
程序代码:
def ImgProcessing(img):
imgHist = cv2.equalizeHist(img)
imgblur = cv2.blur(imgHist, (5, 5))
imgthre, ostu = cv2.threshold(imgblur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
return ostu
path = "Resource\\train\\1_typical_epithelial_cell\\1_122.jpg"
img = cv2.imread(path, 0)
thres = ImgProcessing(imgcopy)
cv2.namedWindow("result",0)
cv2.resizeWindow("result",600,300)
result = cv2.hconcat([thres,img])
cv2.imshow('result',result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
效果演示:如果想得到目标是黑色背景是白色,修改cv2.threshold的参数即可,因为后面的轮廓检测要求传入的目标是白色,故这里目标选择白色。(也是采坑遇见错误查阅官方文档才知道。。。)

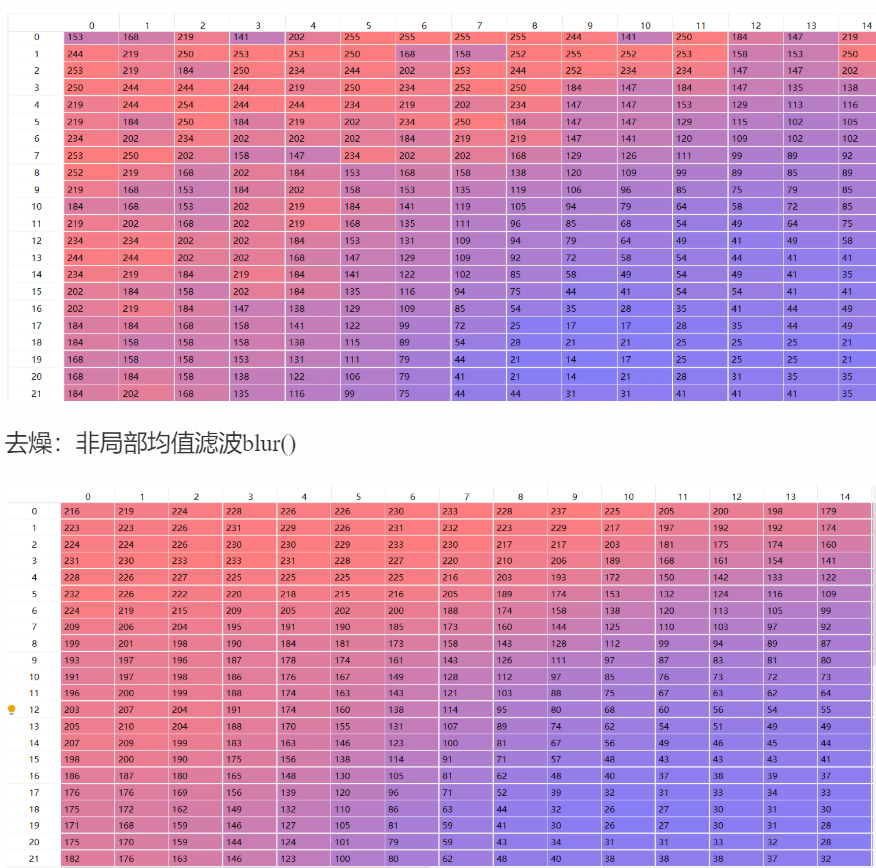
去燥效果演示:
将预处理后的图片保存到trainpro和testpro文件夹中
方法:传入文件路径,获取每张图片然后对每张图片处理后保存到文件夹中

程序代码:
def get_label_dir(path):
for file_name in os.listdir(path):
img_dir = os.path.join(path, file_name)
img = cv2.imread(img_dir,0)
imgHist = cv2.equalizeHist(img)
imgblur = cv2.blur(imgHist, (5, 5))
bestyuzhi1 = diedai(imgblur)
ret1, th1 = cv2.threshold(imgblur, bestyuzhi1, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
cv2.imwrite("Resource\\testpro\\6_garbage\\"+file_name,th1)
get_label_dir("Resource\\test\\6_garbage")
获取特征
本次计算11个基本特征值和Hog特征(还有很多特征可以自行查阅,具体问题具体分析)最后把特征保存到Features列表中,一个图片对应一个11长度的列表。
基本特征:(轮廓特征)周长、面积、长度、宽度、圆度、椭圆度、矩形度、规划形状因子;(纹理特征)均值、方差、平滑度、熵值、三阶矩;
Hog特征:一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。 通过提取有用信息并扔掉多余的信息来简化图像 。 特征描述子将一张大小为width×height×3 (通道数)的图片化成一个长度为n的特征向量数组。以HOG特征为例,输入图像的大小是64×128×3,输出是一个长度为3780(假设)的特征向量 。本次提取756个特征。
程序代码:
def getContours(thres,Features):
contours, hierarchy = cv2.findContours(thres, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnt = contours[0]
area = cv2.contourArea(contours[0])
length = cv2.arcLength(contours[0],True)
a = area*4*math.pi
b = math.pow(length,2)
if b!=0:
roundness = a/b
else:
roundness = 0
rect = cv2.minAreaRect(contours[0])
wideth = rect[1][0]
highth = rect[1][1]
box = cv2.cv2.Boxpoint() if imutils.is_cv2() else cv2.boxPoints(rect)
box = np.int0(box)
minrectarea = np.int0(rect[1][0]*rect[1][1])
rect_degree = area/minrectarea
for i in range(len(contours)):
if len(contours[i]) >= 5:
cv2.drawContours(thres, contours, -1, (150, 10, 255), 3)
ellipse = cv2.fitEllipse(contours[i])
ellipse_area = np.int0(ellipse[1][0] * ellipse[1][1])
ellipse_degree = 4 * area / ellipse_area
d1 = ellipse[1][0]
d2 = ellipse[1][1]
if d1 * d2 * length !=0:
REF = area * (3 * (d1 + d2) - 2 * math.sqrt(d1 * d2)) / (d1 * d2 * length)
else :
REF =0
wenli_gt = cv2.moments(contours[0])
Features.append(round(wideth,3))
Features.append(round(highth,3))
Features.append(round(area,3))
Features.append(round(length,3))
Features.append(round(roundness,3))
Features.append(round(rect_degree,3))
Features.append(round(ellipse_degree,3))
Features.append(round(REF,3))
Features.append(round(wenli_gt['mu02'],3))
def grain_feature(img,Features):
mean , stddv = cv2.meanStdDev(img)
wenli_r = 1-1/(1+stddv*stddv)
imagea = np.histogram(img.ravel(), bins=256)[0]
wenli_s = skimage.measure.shannon_entropy(imagea,base=2)
Features.append(round(wenli_r[0][0],6))
Features.append(round(wenli_s,3))
def get_features(path):
Features_set = []
for file_name in os.listdir(path):
Features = []
img_dir = os.path.join(path, file_name)
img = cv2.imread(img_dir,0)
imgcopy = img.copy()
thres = ImgProcessing(imgcopy)
getContours(thres,Features)
grain_feature(imgcopy,Features)
Features_set.append(Features)
return Features_set
获取Hog特征代码:
def get_hog_feat(path):
Features = []
try:
for file_name in os.listdir(path):
img_dir = os.path.join(path, file_name)
img = cv2.imread(img_dir,0)
imgcopy = cv2.resize(img,(32,64))
features, hog_img = ft.hog(imgcopy, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(2, 2), visualize=True)
Features.append(features)
except cv2.error:
print(file_name)
return Features
制作数据集准备传入模型中,将四类训练集的特征都放入X_train中,Y_train存放标签1,2,3,4(有的模型要求是0,1,2,3,代码中有体现)
path_train = "Resource\\train"
path_test = "Resource\\test"
def get_data(path):
X = []
Y = []
cnt =0
for file_name in os.listdir(path):
Features = []
img_dir = os.path.join(path, file_name)
Features = get_hog_feat(img_dir)
cnt = cnt + 1
for i in Features:
X.append(i)
Y.append(cnt)
return X,Y
X_train ,Y_train = get_data(path_train)
X_test,Y_test = get_data(path_test)
如果遇到传入数据有空值的错误可以使用以下代码
关于np.nan_to_num可查看官方文档https://numpy.org/doc/stable/reference/generated/numpy.nan_to_num.html
X_train = np.nan_to_num(X_train)
Y_train = np.nan_to_num(Y_train)
X_test = np.nan_to_num(X_test)
Y_test = np.nan_to_num(Y_test)
数据降维
特征向量的维数过高会增加计算的复杂度,数据降维消除特征之间的数量级。
使用sklearn中的from sklearn.preprocessing import StandardScaler,使用方法可查看官方文档,sklearn的文档做的很好,有很多example,嘻嘻嘻。
sc_X = StandardScaler()
X_trainscaled = sc_X.fit_transform(X_train)
X_testscaled = sc_X.fit_transform(X_test)
X_testscaled = np.nan_to_num(X_testscaled)
ps:数据准备好开始训练
分类器训练和模型衡量标准
本次训练包含svm支持向量机,ann人工神经网络(MLP多层感知机),Decision Tree决策树、XGBboost(种梯度提升决策树的实现)k-nn(K近邻),Naive Bayes(朴素贝叶斯),有很多方法可以使用,但是很多原理还需要进一步学习。。。
分类器的训练模型参数均保存到.dat文件中,可以节约每次训练的时间。
程序代码:
linear = svm.SVC(kernel='linear',C=1,decision_function_shape='ovo').fit(X_train ,Y_train)
linear = svm.SVC(decision_function_shape='ovo').fit(X_train ,Y_train)
linear_pred = linear.predict(X_test)
linear = joblib.load("Hog_linear.dat")
accuracy_lin = linear.score(X_test,Y_test)
print("SVM-linear准确度为%.2f%%" % (accuracy_lin*100))
MLP = MLPClassifier().fit(X_trainscaled,Y_train)
accuracy_ANN = MLP.score(X_testscaled,Y_test)
print("Hog特征之ANN准确度%.2f%%" % (accuracy_ANN*100.0))
About SVM:kernel(核函数linear、rbf、poly、sigmoid),gamma值、惩罚系数c的选取都会影响最终的准确度的,由于是多分类, 逻辑回归和 SVM 等二元分类模型本身不支持多类分类,需要元策略 ,分类策略采用的是ovo,还有ovr。
关于分类策略ovo和ovr:
由于SVM本质上是二分类模型,多分类可以是二分类的延伸。例如给定多分类class 1,class 2,class 3,class4。
ovo(One-vs-One):
class1 vs class 2
class 1 vs class3 等总共有n(n-1)/2种(4*3/2=6)
ovr(One-vs-Rest)n种:
class 1 vs [class2,class3,class4]
class 2 vs [class1,class 3,class 4]
class 3 vs [class1,class 2 ,class4]
class4 vs [class1,class2,class3]
About ANN
ANN就是借鉴了神经突触机制,在结点中设置了函数,比如sigmoid或者tanh函数,来完成抑制或激活的目标。
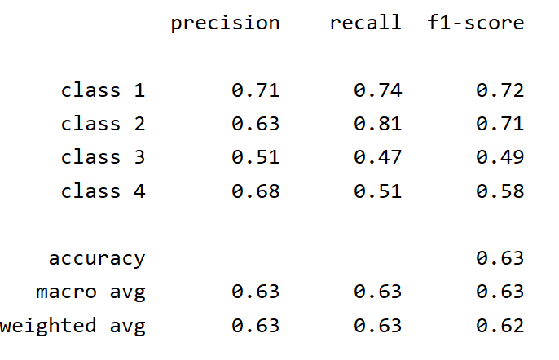
衡量标准
计算准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Measure的数值、画AUC曲线和混淆矩阵。
准确率(Accuracy):1-错误率
精确率(Precision):有多少比例是好的
召回率(Recall):好的信息中有多少被检索出来
F1-Measure的数值:对查准率/查全率的重视程度
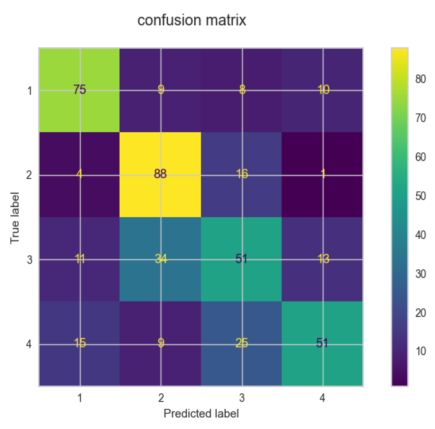
混淆矩阵:看出有多少个分类正确,有多少个被分类到其他的类中
ROC-AUC曲线:ROC曲线下的面积
target_names = ['class 1', 'class 2', 'class 3','class 4']
print(classification_report(Y_test, MLP_pre, target_names=target_names))
disp = metrics.ConfusionMatrixDisplay.from_predictions(Y_test, MLP_pre)
disp.figure_.suptitle("confusion matrix")
print(f"confusion matrix:\n{disp.confusion_matrix}")
plt.show()
model = MLPClassifier()
roc_auc(MLP, X_train, Y_train, X_test=X_test, y_test=Y_test, encoder={1:'typical', 2:'Lymphocyte', 3:'Single',4:'garbage'})
效果演示:
其他的分类器
DTC = tree.DecisionTreeClassifier()
DTC.fit(X_trainscaled,Y_train)
DTC = joblib.load("Hog_DTC.dat")
accuracy_DTC = DTC.score(X_testscaled,Y_test)
print("Hog特征之DTC准确度%.2f%%" % (accuracy_DTC*100.0))
XGB = XGBClassifier().fit(X_trainscaled,Y_train)
accuracy_XGB = XGB.score(X_testscaled,Y_test)
print("Hog特征之XGB准确度%.2f%%" % (accuracy_XGB*100.0))
n_neighbors = 20
h = 0.02
K_N = neighbors.KNeighborsClassifier(n_neighbors,weights="distance")
K_N.fit(X_trainscaled,Y_train)
accuracy_KNN = K_N.score(X_testscaled, Y_test)
print("Hog特征之KNN准确度%.2f%%" % (accuracy_KNN * 100.0))
acc = []
for i in range(1,40):
neigh = neighbors.KNeighborsClassifier(n_neighbors = i).fit(X_trainscaled,Y_train)
yhat = neigh.predict(X_testscaled)
acc.append(metrics.accuracy_score(Y_test, yhat))
plt.figure(figsize=(10,6))
plt.plot(range(1,40),acc,color = 'blue',linestyle='dashed',
marker='o',markerfacecolor='red', markersize=10)
plt.title('accuracy vs. K Value')
plt.xlabel('K')
plt.ylabel('Accuracy')
print("Maximum accuracy:-",max(acc),"at K =",acc.index(max(acc)))
plt.show()
NB_G = GaussianNB().fit(X_trainscaled,Y_train)
NB_G = joblib.load("Hog_NB_G.dat")
accuracy_NBG = NB_G.score(X_testscaled,Y_test)
print("Hog特征之NB_G准确度%.2f%%" % (accuracy_NBG*100.0))
About DT
决策树通过递归地进行特征选择,将训练集数据 D 进行分类最终生成一颗由节点和有向边组成的树结构。其中结点分为两种类型:内部节点和叶节点,内部结点表示一个特征,叶结点表示一个类别。
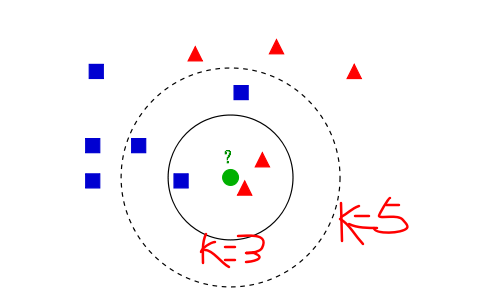
About k-nn
即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。( 这就类似于现实生活中少数服从多数的思想)
ps:关于分类器的算法的原理和理解很浅,希望后期可以多看原理,多看背后的数学逻辑,对适合数据的参数选择能力还不够,加油吧。
Original: https://blog.csdn.net/shan_5233/article/details/124397795
Author: shan_5233
Title: 机器学习分类器——案例(opencv sklearn svm ann)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/680843/
转载文章受原作者版权保护。转载请注明原作者出处!