

目录
- 一、设置学习率
- 二、训练自己的数据集
- 三、错误记录
- 四、多尺度训练
- 五、GC
- 六、代码解读
* - 官方文档:
- 1、config文件
- 2、DeltaXYWHBBoxCoder
- 3、roi_extractor
- 七、常用函数
* - 1. mmcv.track_parallel_progress()
一、设置学习率
学习率在configs/*.py文件中设置


因为之前的lr是在8个gpu的情况下设置的,所以这里应该除以8降低学习率。
mmdetection是根据8个gpu且samples_per_gpu=2来设置学习率为0.02,自己的学习率应该为[0.02/(8 * 2)] * samples_per_gpu * gpus
; 二、训练自己的数据集
参考链接:1. https://zhuanlan.zhihu.com/p/76191492
2. https://github.com/open-mmlab/mmdetection/blob/master/demo/MMDet_Tutorial.ipynb
To train a new detector, there are usually three things to do:
- Support a new dataset
- Modify the config
- Train a new detector
训练一个新的目标检测器需要创建自己的数据集然后修改配置文件,再进行训练。
There are three ways to support a new dataset in MMDetection:
-
reorganize the dataset into COCO format.
-
reorganize the dataset into a middle format.
-
implement a new dataset.
有三种方法可以创建新的数据集:
- 将新的数据集格式转化成COCO数据集格式以指定的目录形式放在指定的目录下,要修改mmdetection/mmdet/datasets/coco.py里的CLASSES和config文件里model字典的的num_classes和data字典的img_scale(输入图像尺寸的最大边和最小边)和optimizer中的lr,接着在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。
- 将新的数据集转化成中间格式
- 构建一个新的Dataset继承CustomDataset
如采用第二种方法要将annotations转化成MMDetection接受的中间形式,如下图:

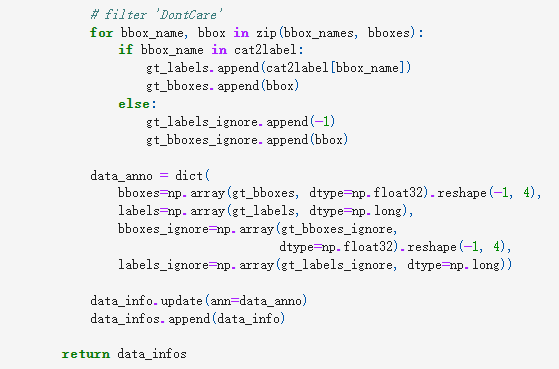
这时就可以用原来的 load_annotations函数,但需要自己写一个继承CustomDataset的Dataset类,如下所示:(文件在mmdet/datasets/*.py),这时就不用修改mmdetection/mmdet/datasets/coco.py里的CLASSES了,因为用自己的新建Dataset类了

再修改config文件,可以自己写一个属于自己的config文件,注意要修改文件路径。
实测用自己的数据集训练并预测成功
首先在mmdet/datasets/文件夹下新建一个自己的数据集py文件,然后可以直接复制仿写coco.py文件,类名要改成自己的数据集,CLASSES修改为自己的类别注意一个类别要加逗号,这样才是元组数据类型;接着要在mmdet/dataset/ init.py文件的__all__添加自己的数据集名,还要加上from .MyDataset(自己的数据集的py文件名) import MyDataset(自己的数据集类名),最后要记得重新安装mmdet才能将自己的数据集注册进DATASETS,可以运行 pip install -v -e .,不要忘了.,还要记得修改config文件里的num_classes和classes,并不用修改网上所说的mmdet/core/evaluation/class_names.py文件,也可以预测出自己的类别。
我在kaggle上成功用下面的方法也添加了自己的数据集,这种方法就是注册了一个继承CoCoDataset类的子类,并重新CLASSES,但在其他地方却显示未注册。
@DATASETS.register_module()
class UnderwaterDataset(CocoDataset):
CLASSES = set(['starfish'])
三、错误记录
1、ValueError: need at least one array to concatenate
出现这种错误可以用configs/cascade_rcnn/underwater.py代码验证,如果没有读取到肯定是数据集的问题,我出现问题的原因是数据集json文件的categories的name与config文件和Dataset的CLASSES里的不一样。
2、AttributeError: ‘ConfigDict’ object has no attribute ‘train_cfg’ during custom dataset training
链接:https://github.com/open-mmlab/mmdetection/issues/4603
用 model = build_detector( cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))取代 model = build_detector( cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
3、KeyError: ‘xxx is not in the dataset registry’
链接:https://github.com/open-mmlab/mmdetection/issues/3751
在mmdet/datasets/下新建自己数据集的py文件,可以仿照CoCo数据集写法, @DATASETS.register_module
class MyDataset xxxx
再在__init__.py文件里
from .my_dataset import MyDataset
然后再在__all__加上自己的数据集
pip install -v -e .
4、has no key: init_cfg
5、TypeError: CascadeRCNN: ResNet: init () got an unexpected keyword argument ‘groups’
错误原因是resnet没有groups这个参数,是因为我将ResneXt写成了Resnet
6、TypeError: CascadeRCNN: SwinTransformer: init () got an unexpected keyword argument ‘ delete ‘
错误原因:If your config does not inherit a config, do not add delete.
四、多尺度训练
The term of “multiscale training” is adopted in many papers, which indicates resizing images to different scales at each iteration. In the challenge, we use the setting [(400, 1600), (1400, 1600)] which means the short edge are randomly sampled from 400~1400, and the long edge is fixed as 1600.
由源码可知有两种模式,range和value,range模式只能有两种尺度,小边从两个尺度小边的范围内去,大边在以两个尺度大边为范围随机取一个整数;value模式可以有任意多个输入尺度,随机挑选一个尺度作为resize的尺度


; 五、GC
https://zhuanlan.zhihu.com/p/102817180
六、代码解读
官方文档:
https://mmdetection.readthedocs.io/zh_CN/latest/tutorials/config.html
1、config文件
参考链接:目标检测比赛中的tricks:https://zhuanlan.zhihu.com/p/102817180
MMDetection 中常用算法详解:Faster R-CNN:https://zhuanlan.zhihu.com/p/422456194
model settings
model = dict(
type='CascadeRCNN',#算法名称
backbone=dict(
type='ResNeXt',#特征提取网络类型
depth=101,#深度
num_stages=4,#resnet的stage数,一般都是4个,resnet包括一个stem和4个stage输出
out_indices=(0, 1, 2, 3),#输出的特征图索引,表示四个stage输出都需要
# 表示本模块输出的特征图索引,(0, 1, 2, 3),表示4个 stage 输出都需要,
# 其 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)
frozen_stages=1,#冻结的stage数,-1表示不冻结,0表示冻结stage0,1表示冻结0,1,以此类推
norm_cfg=dict(type='BN', requires_grad=True),#采用的归一化算子(一般是BN或者GN),这里采用BN,且梯度更新
norm_eval=True,#backbone的所有BN层都采用eval模式,即均值和方差都直接采用全局预训练值,不进行更新
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'),
groups=64,
base_width=4),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],# resnet模块四个stage的四个尺度输出feature map的的通道数
out_channels=256,# fpn输出的每个尺度特征图的通道数
num_outs=5),# fpn输出的特征图个数
# FPN 模块实现了c2 ~ c5 4 个特征图输入,p2 ~ p6 5个特征图输出,其 strides = (4,8,16,32,64)。其中p6是m5上采样得来的一个大感受野特征图以检测超大物体。
rpn_head=dict(
type='RPNHead',# rpn网络模型
in_channels=256,# rpn网络的输入通道数
feat_channels=256,# 中间特征图通道数
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],#决定anchor大小,不同尺度特征图的锚点面积为base_size = scale * stride
ratios=[0.5, 1.0, 2.0],#每个feature map生成的anchor宽高比,可修改优化
strides=[4, 8, 16, 32, 64]),#每个尺度的feature map生成anchor对于原图的步长,对应于stage的stride,# 锚生成器的步幅。这与 FPN 特征步幅一致。 如果未设置 base_sizes,则当前步幅值将被视为 base_sizes。
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',#见下面
target_means=[.0, .0, .0, .0],# 输出的四个target值减去均值除以标准差
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),# ROI类型为ROIAlign,输出尺寸为7,连接rpn和rcnn
out_channels=256,# 输入shape为(batch,nms_post,4)输出为(batch,nms_post,256,roi_feat_size,roi_feat_size),256为fpn层输出的特征图通道大小
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='Shared2FCBBoxHead',# 两个共享的FC模块
in_channels=256,# 输入通道数,相当于FPN输出通道数
fc_out_channels=1024,# 输出通道数,应用两次共享全连接层,输出shape为(batch*nms_post,1024)
roi_feat_size=7,# ROIAlign或者ROIPool输出的特征图大小
num_classes=1,,类别个数
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=True,# 是否采用class_agnostic的方式来预测,true时表示输出bbox只考虑其是否为前景,后续分类的时候再根据该bbox在网络中的类别得分来分类,也就是一个框可以对应多个类别,影响bbox分支的通道数,True表示4通道输出,False表示4*num_classes通道输出
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=1,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
]),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,# 分别计算每个anchor和所有gt的iou,大于0.7为正样本
neg_iou_thr=0.3,# 小于0.3为负样本
min_pos_iou=0.3,# 计算每个gt和所有anchor的iou,最大的大于0.3则保留这个anchor,这会生成低质量的anchor,执不执行取决于match_low_quality。
match_low_quality=True,
ignore_iof_thr=-1),#
sampler=dict(
type='RandomSampler',
num=256,# 需要提取的正负样本总数
pos_fraction=0.5,# 正样本比例
neg_pos_ub=-1,# 正负样本比例,用于确定负样本采样个数上界,-1表示负样本在正样本个数不足的情况下用于补齐256
add_gt_as_proposals=False),# 是否加入gt作为proposal
#是防止高质量正样本太少而加入的,可以保证前期收敛更快、更稳定,属于训练技巧,在 RPN 模块设置为 False,主要用于 R-CNN(RCNN模块设置为True),因为前期 RPN 提供的正样本不够,可能会导致训练不稳定或者前期收敛慢的问题。
allowed_border=0,# 允许在bbox周围外扩一定的像素
pos_weight=-1, # 正样本权重,-1表示不改变原始的权重
debug=False), # debug模式
rpn_proposal=dict(#rpn输入给rcnn的anchor
nms_pre=2000,
max_per_img=2000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,#这里都是0.5的原因是一般rcnn的anchor是由rpn输入的高质量的anchor。
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.7,
min_pos_iou=0.7,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
]),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)))
公共逻辑部分输出 batch * nms_post 个候选框的分类和回归预测结果
将所有预测结果按照 batch 维度进行切分,然后依据单张图片进行后处理,后处理逻辑为:先解码并还原为原图尺度;然后利用 score_thr 去除低分值预测;然后进行 NMS;最后保留最多 max_per_img 个结果
dataset settings
dataset_type = 'UnderwaterDataset'
data_root = '/kaggle/working/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'anotation_train.json',
img_prefix=data_root + 'image/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotation_valid.json',
img_prefix=data_root + 'image/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotation_valid.json',
img_prefix=data_root + 'image/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')# 每隔多少epoch验证一次,以及验证的评价指标
optimizer
optimizer = dict(type='SGD', lr=0.02/8, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
#runner = dict(type='EpochBasedRunner', max_epochs=12)
total_epochs =12
checkpoint_config = dict(interval=1) # 每隔多少epoch保存一次模型文件
yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
2、DeltaXYWHBBoxCoder
mmdet/core/bbox/coder/delat_xywh_bbox_coder.py
源码:
def bbox2delta(proposals, gt, means=(0., 0., 0., 0.), stds=(1., 1., 1., 1.)):
"""Compute deltas of proposals w.r.t. gt.
We usually compute the deltas of x, y, w, h of proposals w.r.t ground
truth bboxes to get regression target.
This is the inverse function of :func:delta2bbox.
Args:
proposals (Tensor): Boxes to be transformed, shape (N, ..., 4)
gt (Tensor): Gt bboxes to be used as base, shape (N, ..., 4)
means (Sequence[float]): Denormalizing means for delta coordinates
stds (Sequence[float]): Denormalizing standard deviation for delta
coordinates
Returns:
Tensor: deltas with shape (N, 4), where columns represent dx, dy,
dw, dh.
"""
assert proposals.size() == gt.size()
proposals = proposals.float()
gt = gt.float()
px = (proposals[..., 0] + proposals[..., 2]) * 0.5
py = (proposals[..., 1] + proposals[..., 3]) * 0.5
pw = proposals[..., 2] - proposals[..., 0]
ph = proposals[..., 3] - proposals[..., 1]
gx = (gt[..., 0] + gt[..., 2]) * 0.5
gy = (gt[..., 1] + gt[..., 3]) * 0.5
gw = gt[..., 2] - gt[..., 0]
gh = gt[..., 3] - gt[..., 1]
dx = (gx - px) / pw
dy = (gy - py) / ph
dw = torch.log(gw / pw)
dh = torch.log(gh / ph)
deltas = torch.stack([dx, dy, dw, dh], dim=-1)
means = deltas.new_tensor(means).unsqueeze(0)
stds = deltas.new_tensor(stds).unsqueeze(0)
deltas = deltas.sub_(means).div_(stds)
return deltas
@mmcv.jit(coderize=True)
def delta2bbox(rois,
deltas,
means=(0., 0., 0., 0.),
stds=(1., 1., 1., 1.),
max_shape=None,
wh_ratio_clip=16 / 1000,
clip_border=True,
add_ctr_clamp=False,
ctr_clamp=32):
"""Apply deltas to shift/scale base boxes.
Typically the rois are anchor or proposed bounding boxes and the deltas are
network outputs used to shift/scale those boxes.
This is the inverse function of :func:bbox2delta.
Args:
rois (Tensor): Boxes to be transformed. Has shape (N, 4).
deltas (Tensor): Encoded offsets relative to each roi.
Has shape (N, num_classes * 4) or (N, 4). Note
N = num_base_anchors * W * H, when rois is a grid of
anchors. Offset encoding follows [1]_.
means (Sequence[float]): Denormalizing means for delta coordinates.
Default (0., 0., 0., 0.).
stds (Sequence[float]): Denormalizing standard deviation for delta
coordinates. Default (1., 1., 1., 1.).
max_shape (tuple[int, int]): Maximum bounds for boxes, specifies
(H, W). Default None.
wh_ratio_clip (float): Maximum aspect ratio for boxes. Default
16 / 1000.
clip_border (bool, optional): Whether clip the objects outside the
border of the image. Default True.
add_ctr_clamp (bool): Whether to add center clamp. When set to True,
the center of the prediction bounding box will be clamped to
avoid being too far away from the center of the anchor.
Only used by YOLOF. Default False.
ctr_clamp (int): the maximum pixel shift to clamp. Only used by YOLOF.
Default 32.
Returns:
Tensor: Boxes with shape (N, num_classes * 4) or (N, 4), where 4
represent tl_x, tl_y, br_x, br_y.
References:
.. [1] https://arxiv.org/abs/1311.2524
Example:
>>> rois = torch.Tensor([[ 0., 0., 1., 1.],
>>> [ 0., 0., 1., 1.],
>>> [ 0., 0., 1., 1.],
>>> [ 5., 5., 5., 5.]])
>>> deltas = torch.Tensor([[ 0., 0., 0., 0.],
>>> [ 1., 1., 1., 1.],
>>> [ 0., 0., 2., -1.],
>>> [ 0.7, -1.9, -0.5, 0.3]])
>>> delta2bbox(rois, deltas, max_shape=(32, 32, 3))
tensor([[0.0000, 0.0000, 1.0000, 1.0000],
[0.1409, 0.1409, 2.8591, 2.8591],
[0.0000, 0.3161, 4.1945, 0.6839],
[5.0000, 5.0000, 5.0000, 5.0000]])
"""
num_bboxes, num_classes = deltas.size(0), deltas.size(1) // 4
if num_bboxes == 0:
return deltas
deltas = deltas.reshape(-1, 4)
means = deltas.new_tensor(means).view(1, -1)
stds = deltas.new_tensor(stds).view(1, -1)
denorm_deltas = deltas * stds + means
dxy = denorm_deltas[:, :2]
dwh = denorm_deltas[:, 2:]
rois_ = rois.repeat(1, num_classes).reshape(-1, 4)
pxy = ((rois_[:, :2] + rois_[:, 2:]) * 0.5)
pwh = (rois_[:, 2:] - rois_[:, :2])
dxy_wh = pwh * dxy
max_ratio = np.abs(np.log(wh_ratio_clip))
if add_ctr_clamp:
dxy_wh = torch.clamp(dxy_wh, max=ctr_clamp, min=-ctr_clamp)
dwh = torch.clamp(dwh, max=max_ratio)
else:
dwh = dwh.clamp(min=-max_ratio, max=max_ratio)
gxy = pxy + dxy_wh
gwh = pwh * dwh.exp()
x1y1 = gxy - (gwh * 0.5)
x2y2 = gxy + (gwh * 0.5)
bboxes = torch.cat([x1y1, x2y2], dim=-1)
if clip_border and max_shape is not None:
bboxes[..., 0::2].clamp_(min=0, max=max_shape[1])
bboxes[..., 1::2].clamp_(min=0, max=max_shape[0])
bboxes = bboxes.reshape(num_bboxes, -1)
return bboxes
3、roi_extractor
参考链接:目标检测比赛中的tricks(已更新更多代码解析)
MMDetection 中常用算法详解:Faster R-CNN
config代码:
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32],
gc_context=True),
源码: mmdet/models/roi_heads/roi_extractors/single_level_roi_extractor.py
def forward(self, feats, rois, roi_scale_factor=None):
"""Forward function."""
out_size = self.roi_layers[0].output_size
print("self.roi_layers[0].output_size:",self.roi_layers[0].output_size)
print("self.roi_layers:",self.roi_layers)
num_levels = len(feats)
expand_dims = (-1, self.out_channels * out_size[0] * out_size[1])
if torch.onnx.is_in_onnx_export():
roi_feats = rois[:, :1].clone().detach()
roi_feats = roi_feats.expand(*expand_dims)
roi_feats = roi_feats.reshape(-1, self.out_channels, *out_size)
roi_feats = roi_feats * 0
else:
roi_feats = feats[0].new_zeros(
rois.size(0), self.out_channels, *out_size)
if torch.__version__ == 'parrots':
roi_feats.requires_grad = True
if num_levels == 1:
if len(rois) == 0:
return roi_feats
return self.roi_layers[0](feats[0], rois)
if self.gc_context:
context = []
for feat in feats:
context.append(self.pool(feat))
print("context[0].shape:",context[0].shape)
print("context[1].shape:", context[1].shape)
target_lvls = self.map_roi_levels(rois, num_levels)
batch_size = feats[0].shape[0]
if roi_scale_factor is not None:
rois = self.roi_rescale(rois, roi_scale_factor)
for i in range(num_levels):
mask = target_lvls == i
if torch.onnx.is_in_onnx_export():
mask = mask.float().unsqueeze(-1)
rois_i = rois.clone().detach()
rois_i *= mask
mask_exp = mask.expand(*expand_dims).reshape(roi_feats.shape)
roi_feats_t = self.roi_layers[i](feats[i], rois_i)
roi_feats_t *= mask_exp
roi_feats += roi_feats_t
continue
inds = mask.nonzero(as_tuple=False).squeeze(1)
if inds.numel() > 0:
rois_ = rois[inds]
roi_feats_t = self.roi_layers[i](feats[i], rois_)
if self.gc_context:
for j in range(batch_size):
roi_feats_t[rois_[:, 0] == j] += context[i][j]
roi_feats[inds] = roi_feats_t
else:
roi_feats += sum(
x.view(-1)[0]
for x in self.parameters()) * 0. + feats[i].sum() * 0.
print("roi_feats:",roi_feats.shape)
return roi_feats
可见roi head总流程就是:roi_extractor输入的是來自rpn生成的形状为(512,5)的512个proposal(如果batch_size为2的话就是(1024,5))和fpn生成的四个尺度的feature map(维度是(batch_size,256,w,h)),将512个proposal按照算法对应到不同的feature map上,然后通过roi pooling生成(512 _batch_size,256,7,7)的张量,然后遍历所有尺度的feature map最后输出的是(512,256,7,7)的张量送入bbox head中。形状为(batch_size_512,256,7,7)bbox_feats输入到两层共享全连接层bbox head输出bbox_pred(形状为(512,4)和cls_score(形状为(512,num_classes)
cls_score, bbox_pred = bbox_head(bbox_feats)


!](https://img-blog.csdnimg.cn/e3ae649e751944ef88f5c1c9d57e3d41.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcGhpbHkxMjM=,size_20,color_FFFFFF,t_70,g_se,x_16)
当batch_size为2时,



七、常用函数
1. mmcv.track_parallel_progress()
功能是多线程的对许多任务进行处理,比如多线程的读取数据集加快速度。
def track_parallel_progress(func,
tasks,
nproc,
initializer=None,
initargs=None,
bar_width=50,
chunksize=1,
skip_first=False,
keep_order=True,
file=sys.stdout):
参数func是应用于每个任务的函数,tasks是任务列表,nproc是worker线程数。
Original: https://blog.csdn.net/phily123/article/details/121963512
Author: phily123
Title: 目标检测学习笔记——mmdetection
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/680516/
转载文章受原作者版权保护。转载请注明原作者出处!