

1.环境配置
操作系统 Windows
python 3.8
paddlepaddle-gpu 2.3.0
CUDA 10.2
cuDNN 7.6.5
ppdet 2.2.4
2.项目结构
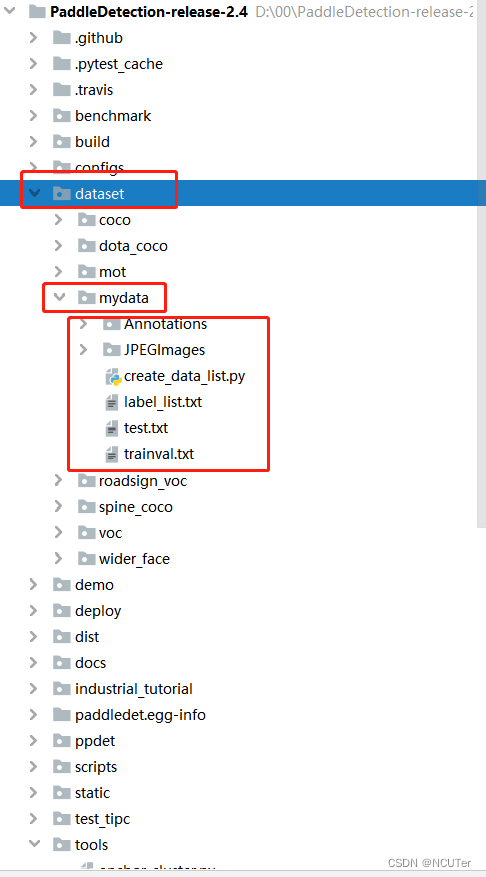

3.准备数据集
1、下载源码后,打开项目,在PaddleDetection/dataset目录下新建文件夹 mydata
2、在PaddleDetection/dataset/mydata目录下新建文件夹Annotations、JPEGImages
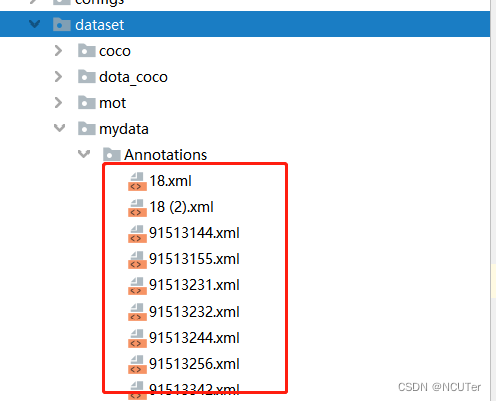
3、将所有所有标注的XML文件放到dataset/mydata/Annotations目录下 如下图
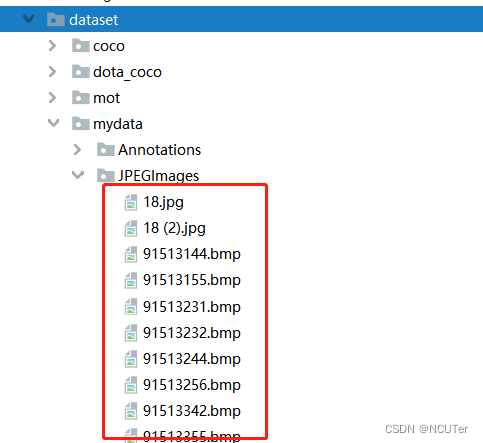
4、将所有标注的图片放到dataset/mydata/JPEGImages目录下,如下图
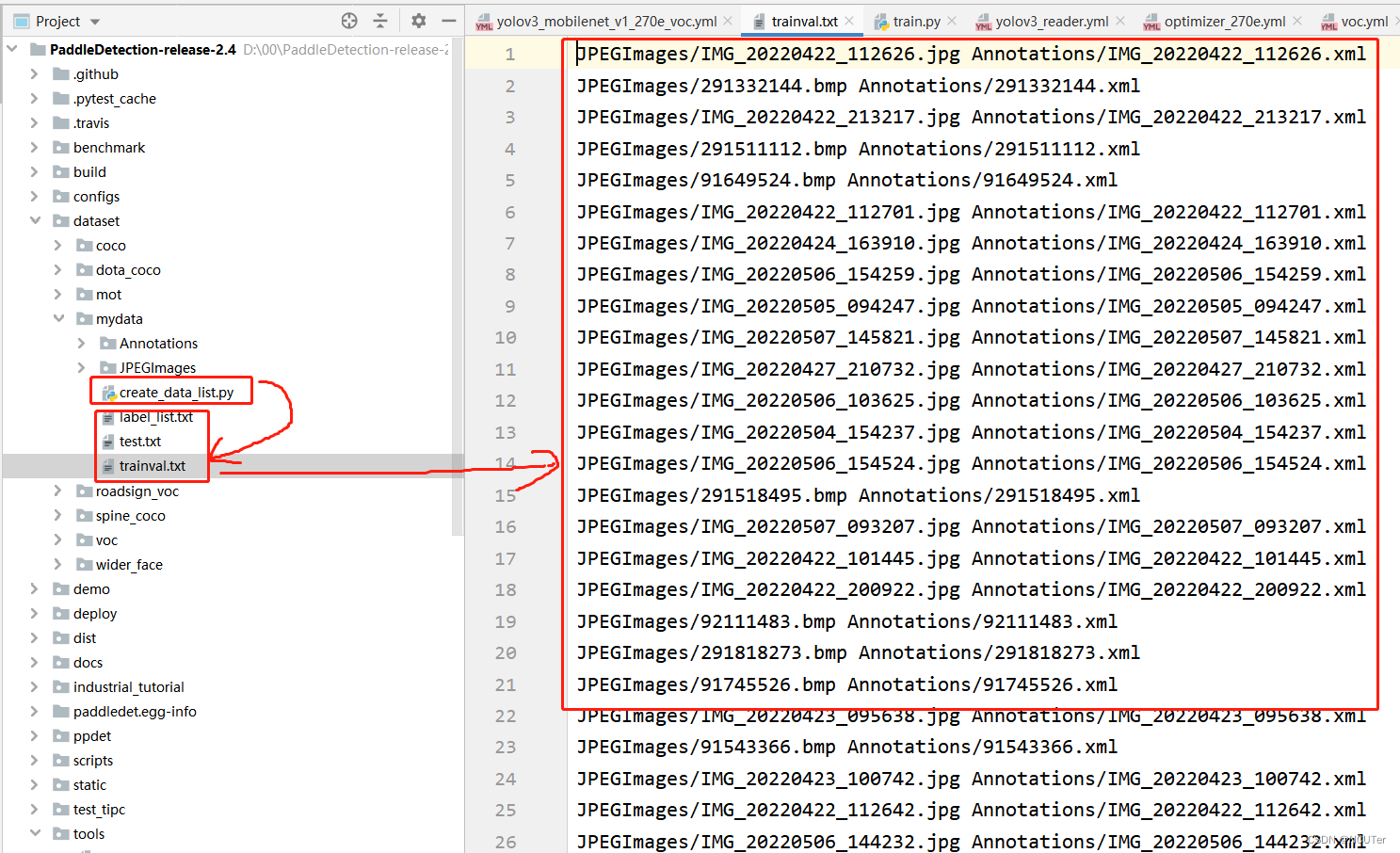
5.利用 create_data_list.py 来生成对应的文本文件
4.修改指定配置文件
本项目中,使用YOLOv3模型里的configs/yolov3/yolov3_mobilenet_v1_270e_voc.yml 训练
从上图看到yolov3_mobilenet_v1_270e_voc.yml 配置需要依赖其他的配置文件。该例子依赖:
在修改文件之前,先给大家解释一下各依赖文件的作用:

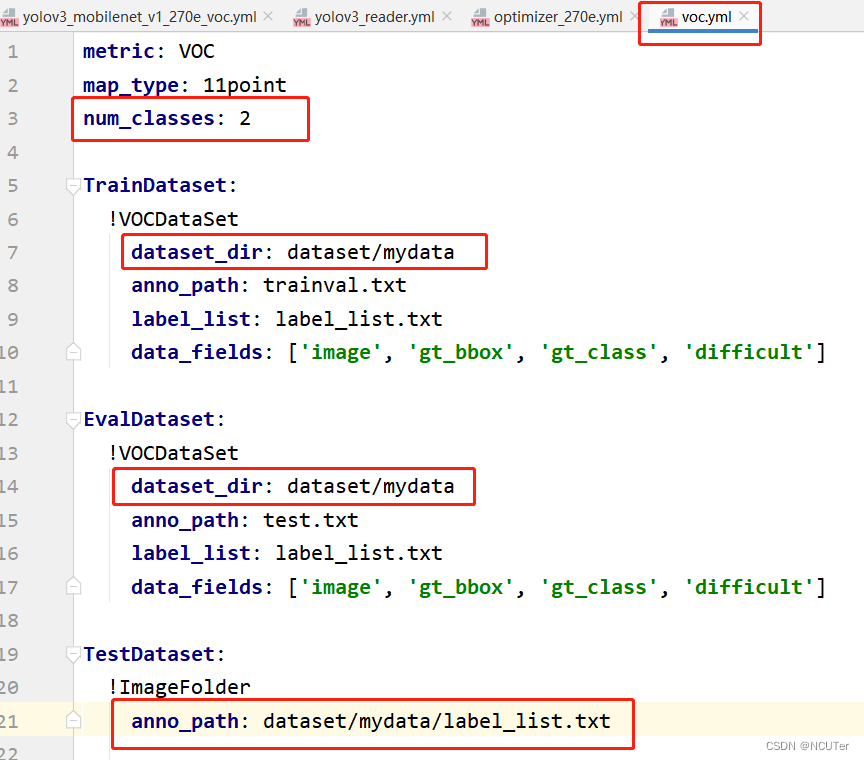
①’ …/datasets/voc.yml’主要说明了训练数据和验证数据的路径,包括数据格式(coco、voc等)
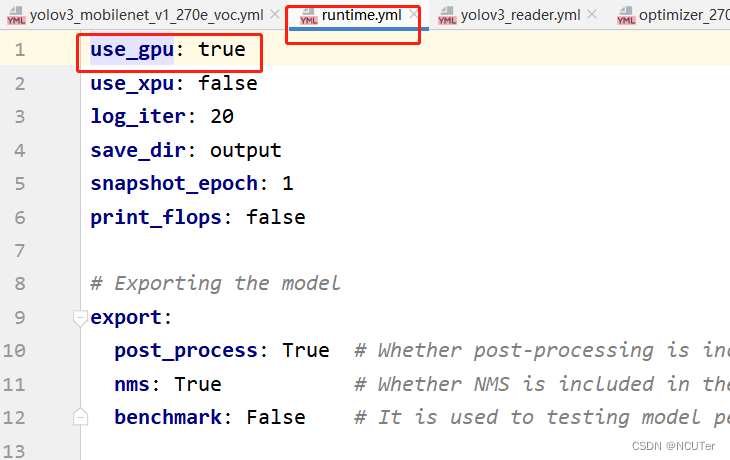
②’…/runtime.yml’,主要说明了公共的运行状态,比如说是否使用GPU、迭代轮数等等
③’_base/optimizer_270e.yml’,主要说明了学习率和优化器的配置,以及设置epochs。在其他的训练的配置中,学习率和优化器是放在了一个新的配置文件中。 ‘base/yolov3_mobilenet_v1.yml’,主要说明模型、和主干网络的情况说明.。。。
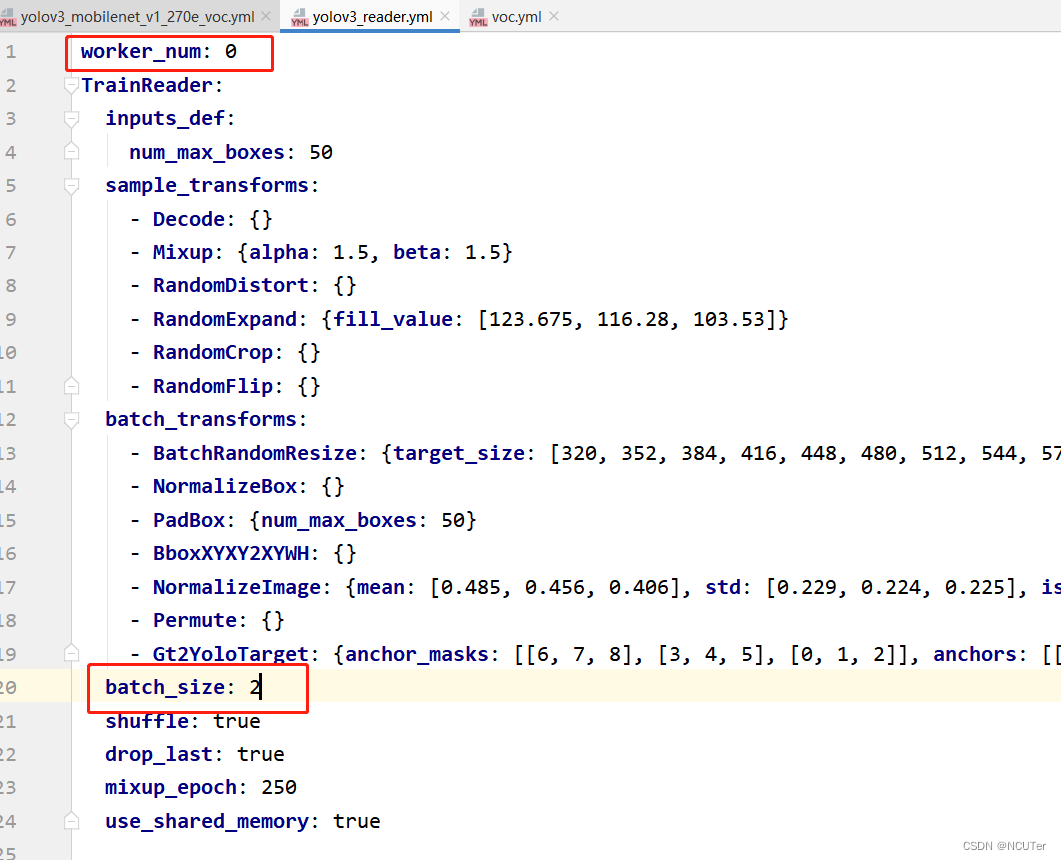
④’_base/yolov3_reader.yml’, 主要说明了读取后的预处理操作,比如resize、数据增强等等。
请保证PaddleDetection环境配置好之后按照如下图示修改即可:
voc.yml
runtime.yml
optimizer_270e.yml 和 yolov3_mobilenet_v1.yml 无需进行修改,默认即可!
yolov3_reader.yml
4.开始训练
PaddleDetection提供了单卡/多卡训练模式,满足用户多种训练需求
(1)单卡训练
export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_270e_voc.yml
python tools/train.py -c configs/yolov3_mobilenet_v1_270e_voc.yml --eval
首先指定CUDA的环境变量
其中 -c 后边代表指定配置文件的路径
(2)多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #windows和Mac下不需要执行该命令
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/yolov3/yolov3_darknet53_270e_voc.yml
(3)训练过程图示
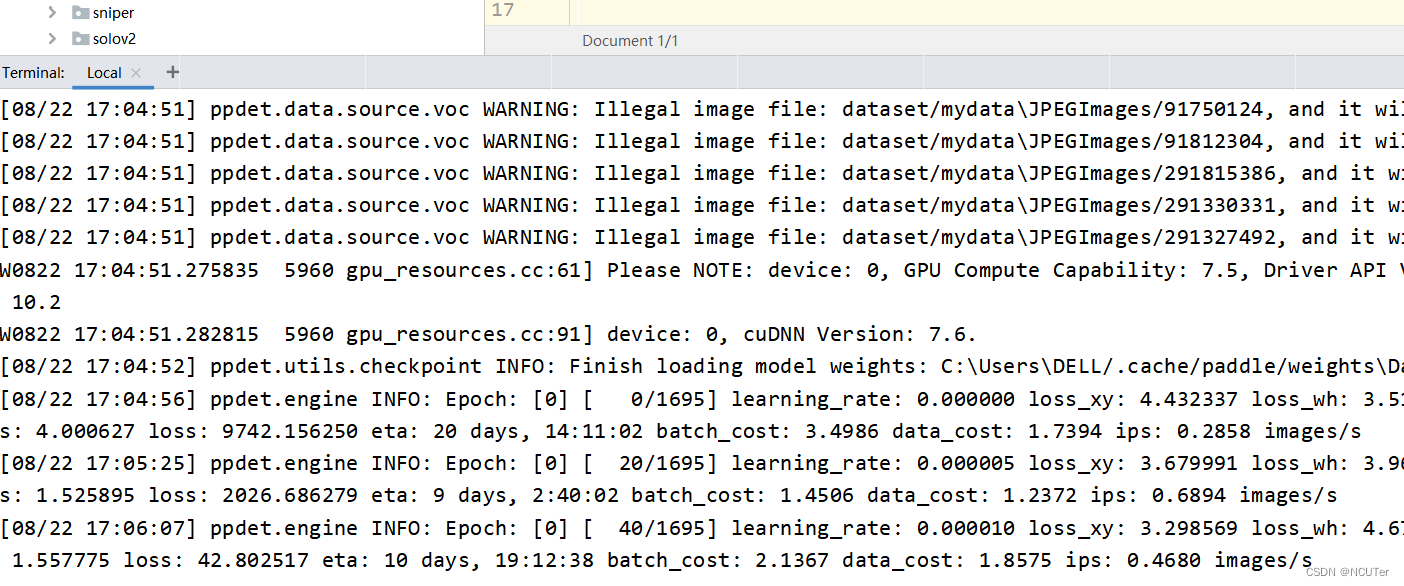
create_data_list:
import os
import random
import xml.etree.ElementTree
from tqdm import tqdm
打乱数据
def shuffle_data(data_list_path):
with open(data_list_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
random.shuffle(lines)
with open(data_list_path, 'w', encoding='utf-8') as f:
f.writelines(lines)
生成图像列表
def create(images_dir, annotations_dir, train_list_path, test_list_path, label_file):
f_train = open(train_list_path, 'w', encoding='utf-8')
f_test = open(test_list_path, 'w', encoding='utf-8')
f_label = open(label_file, 'w', encoding='utf-8')
label = set()
images = os.listdir(images_dir)
i = 0
for image in tqdm(images):
i += 1
annotation_path = os.path.join(annotations_dir, image[:-3] + 'xml').replace('\\', '/')
image_path = os.path.join(images_dir, image).replace('\\', '/')
if not os.path.exists(annotation_path):
continue
root = xml.etree.ElementTree.parse(annotation_path).getroot()
for object in root.findall('object'):
label.add(object.find('name').text)
if i % 20 == 0:
f_test.write("%s %s\n" % (image_path[image_path.find('/') + 1:], annotation_path[annotation_path.find('/') + 1:]))
else:
f_train.write("%s %s\n" % (image_path[image_path.find('/') + 1:], annotation_path[annotation_path.find('/') + 1:]))
for l in label:
f_label.write("%s\n" % l)
f_train.close()
f_test.close()
f_label.close()
# 打乱训练数据
shuffle_data(train_list_path)
print('create data list done!')
if __name__ == '__main__':
create('./JPEGImages', './Annotations', './trainval.txt', './test.txt', './label_list.txt')
Original: https://blog.csdn.net/weixin_50016546/article/details/126469095
Author: NCUTer
Title: 利用PaddleDetection 训练自定义VOC数据集进行目标检测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/680144/
转载文章受原作者版权保护。转载请注明原作者出处!