

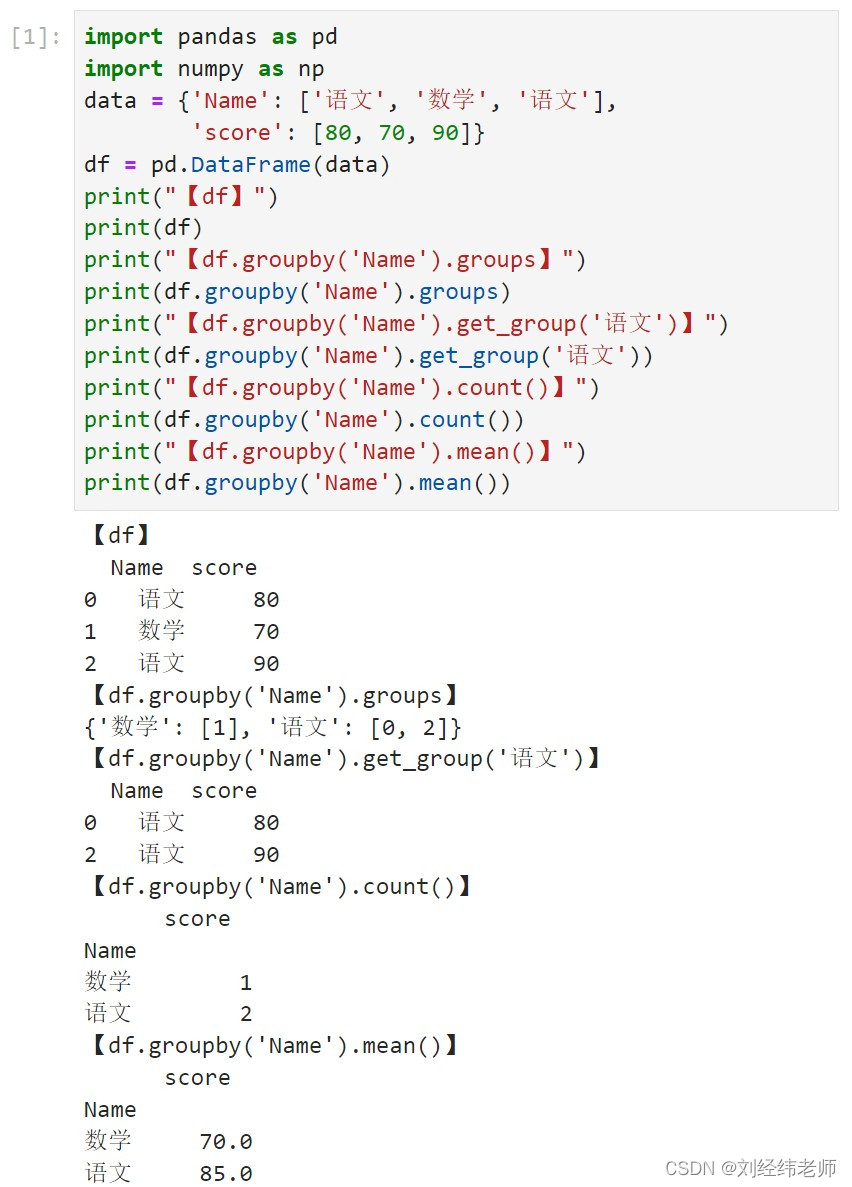
对下面代码理解错误的选项是?
import pandas as pd
import numpy as np
data = {'Name': ['语文', '数学', '语文'],
'score': [80, 70, 90]}
df = pd.DataFrame(data)
print("【df】")
print(df)
print("【df.groupby('Name').groups】")
print(df.groupby('Name').groups)
print("【df.groupby('Name').get_group('语文')】")
print(df.groupby('Name').get_group('语文'))
print("【df.groupby('Name').count()】")
print(df.groupby('Name').count())
print("【df.groupby('Name').mean()】")
print(df.groupby('Name').mean())
A选项:代码根据课程名(Name )属性对数据df分组。
B选项:直接输出groupby方法的结果不能看到分组结果。
C选项:代码根据课程名分组统计了成员成绩的标准差。
D选项:代码根据课程名分组统计了成员的个数。
正确答案是:C
问题解析:

[太阳]温馨期待
期待大家提出宝贵建议,互相交流,收获更大,助教:dmx
微博公开课# [握手] #IT研究所
欢迎大家转发,一起传播知识和正能量,帮助到更多人。期待大家提出宝贵改进建议,互相交流,收获更大。辛苦大家转发时注明出处(也是咱们公益编程交流群的入口网址),刘经纬老师共享知识相关文件下载地址为:https://liujingwei.cn
Original: https://blog.csdn.net/liujingwei8610/article/details/127046406
Author: 刘经纬老师
Title: Python中dataframe.groupby()根据数据属性对数据分组
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679813/
转载文章受原作者版权保护。转载请注明原作者出处!