

- Pandas的基础
1.1 Pandas的介绍
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
1.2 为什么使用Pandas
- 增强图表可读性
- 便捷的数据处理能力
- 读取文件方便
-
封装了Matplotlib、Numpy的画图和计算
-
Pandas数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。 其中Series是一维数据结构,DataFrame是二维的表格型数据结构,MultiIndex是三维的数据结构。
SeriesDataFrameMultiIndexSeries是一维数据结构DataFrame是二维的表格型数据结构MultiIndex是三维的数据结构
2.1 Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两 部分构成。
1. Series的创建
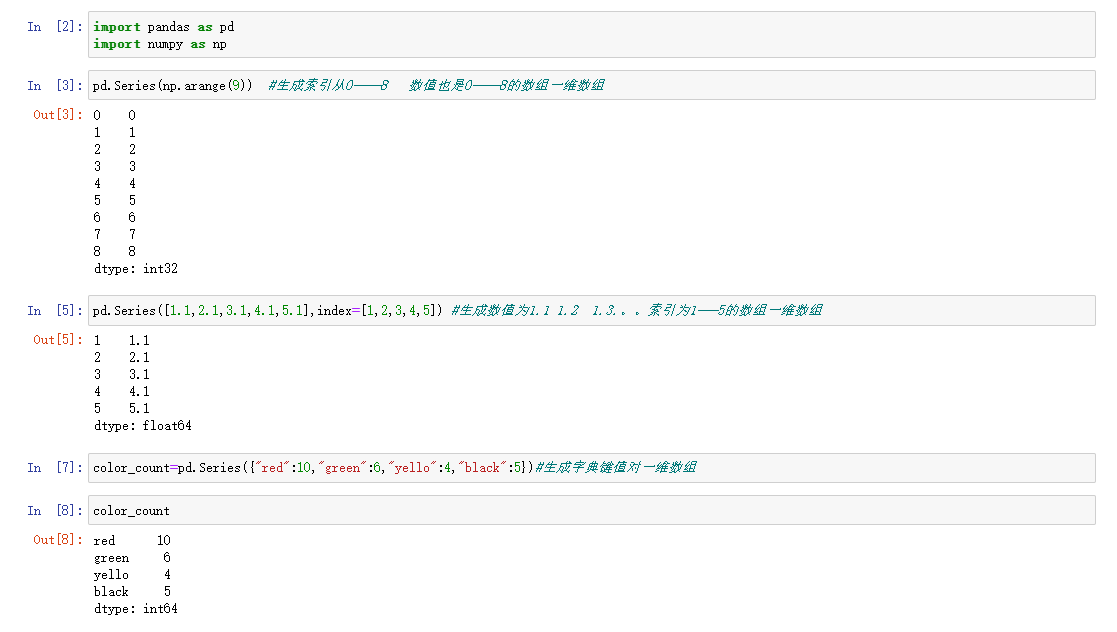

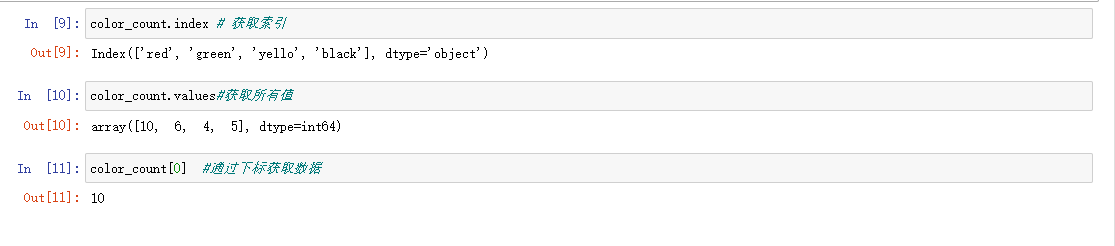
; 2. serise的属性
2.2 DataFrame
1 DataFrame的创建
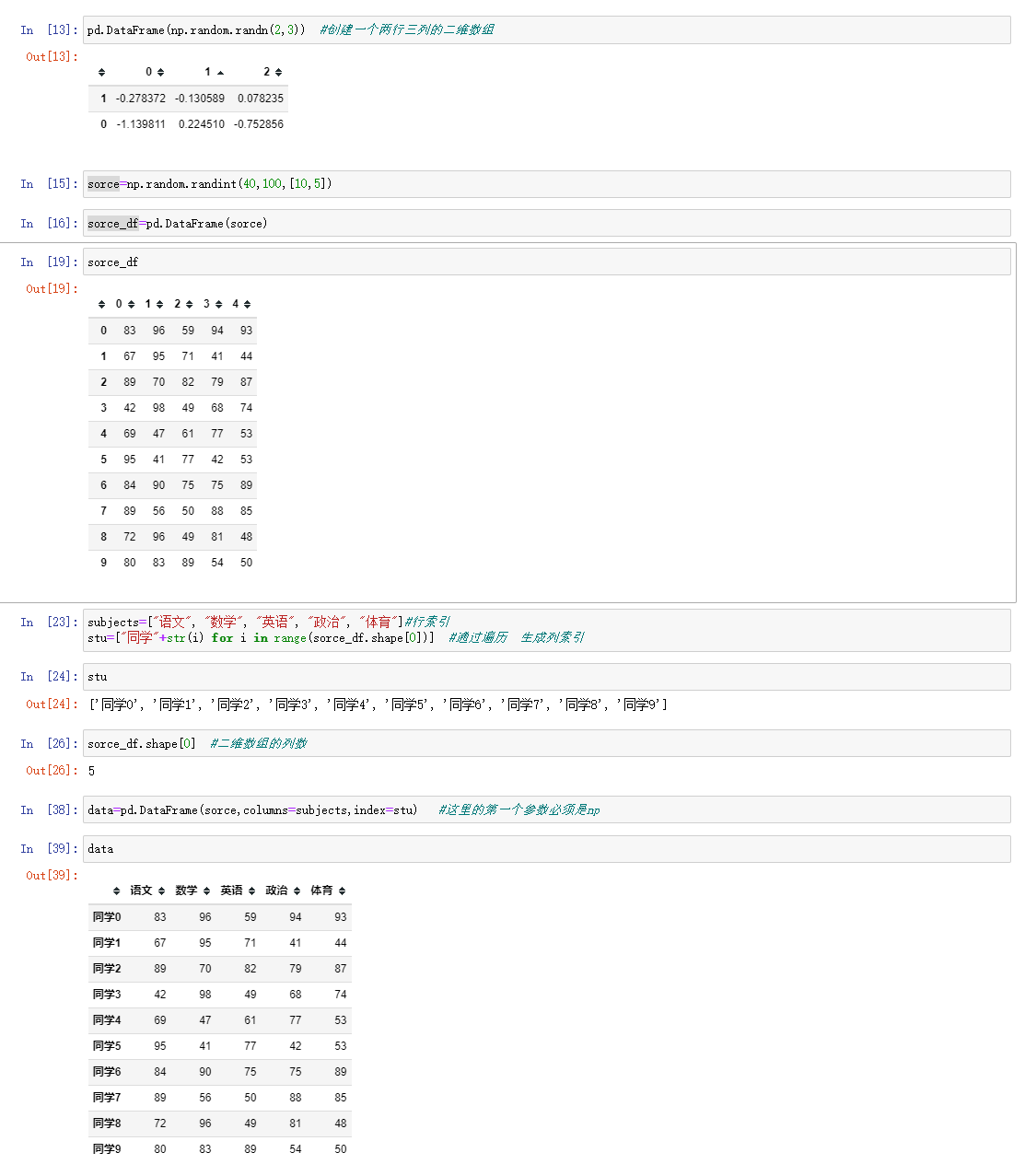
; 2 DataFeam的属性
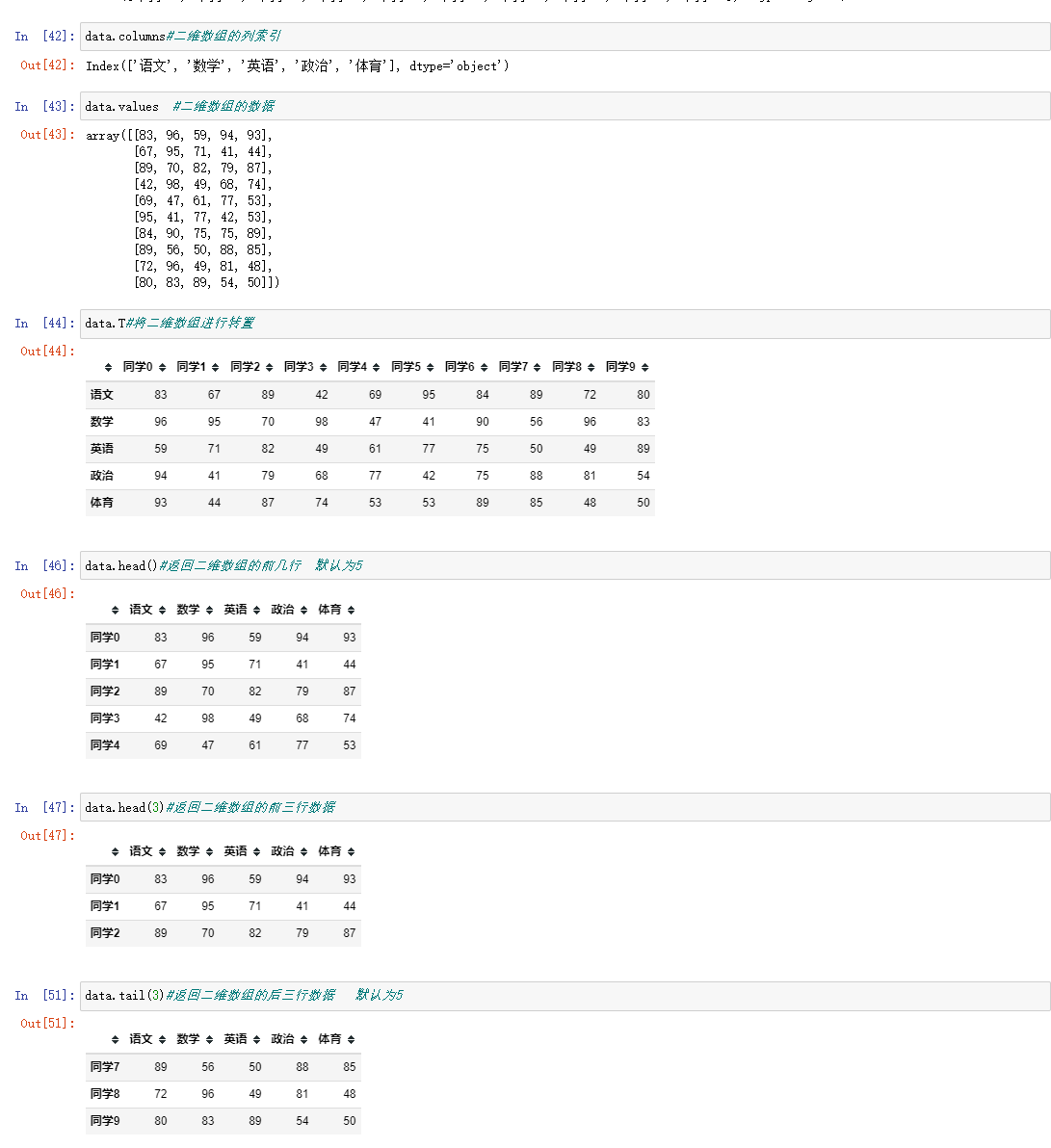
3. DataFrame索引值的设置
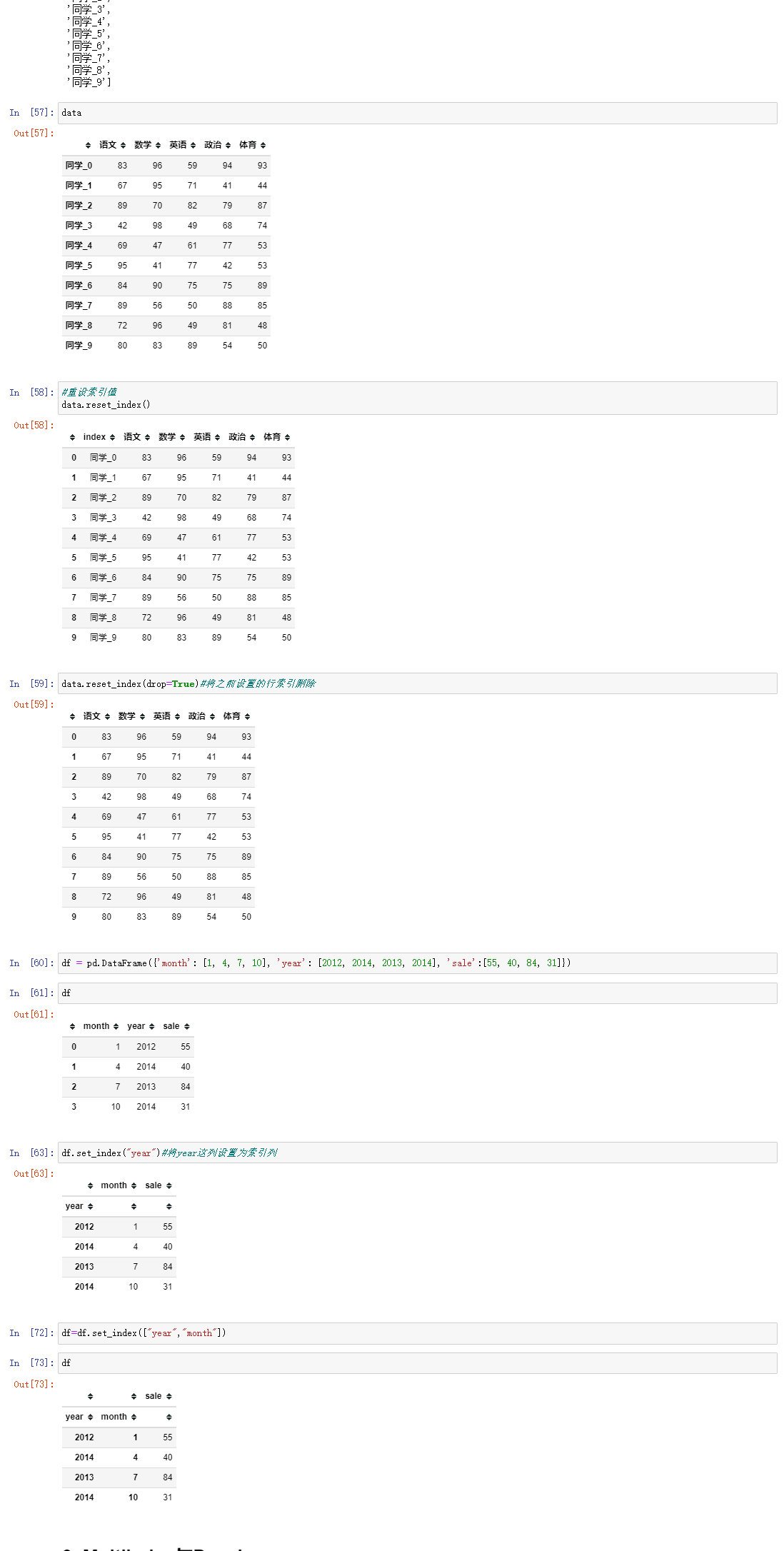
; 2.3 MultiIndex与Panel
1. MultiIndex
MultiIndex是三维的数据结构; 多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
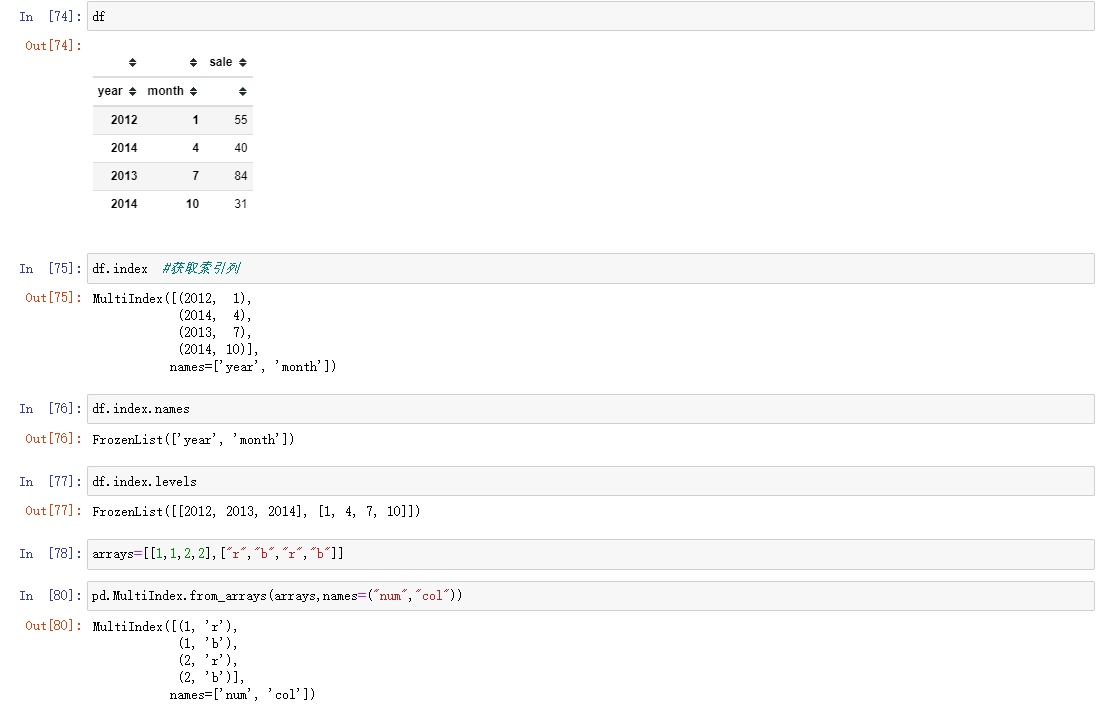
; 2. Panel
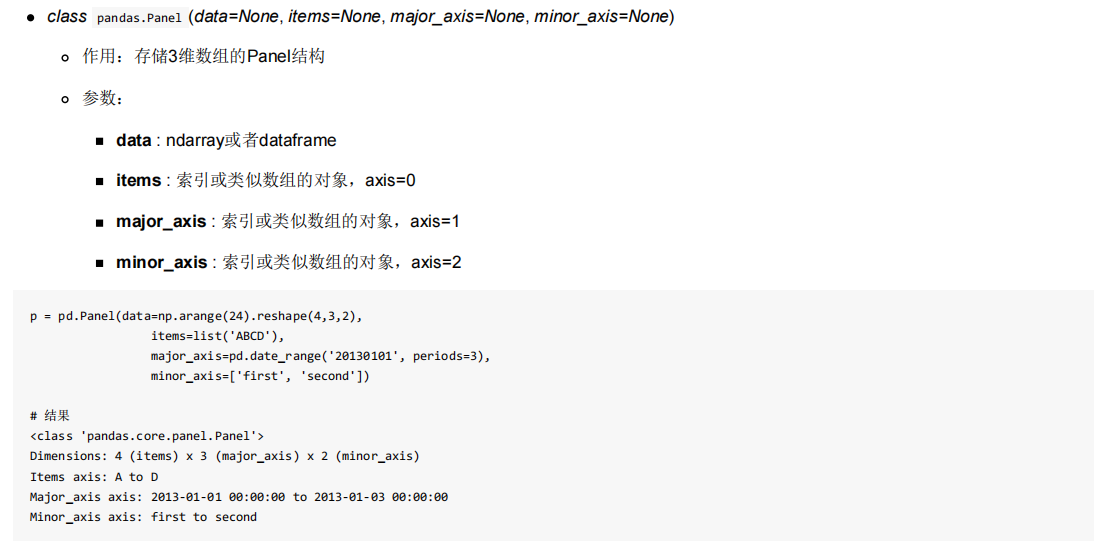
3.基本数据操作
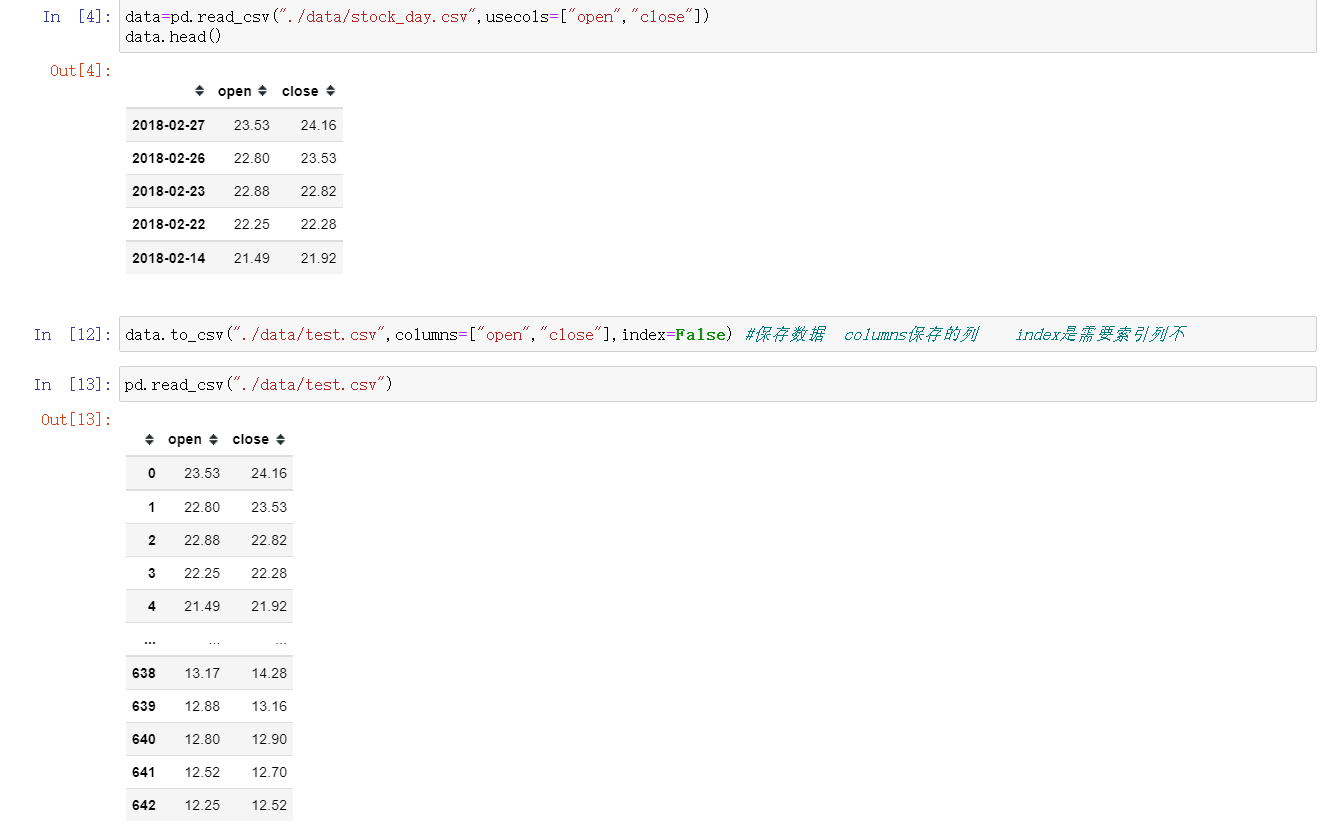
- 读取文件
data=pd.read_csv("./data/stock_day.csv") - 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
3.1 索引操作
- 默认的索引操作必须事先列后行
- 使用loc:只能指定行列索引的名字
- 使用iloc可以通过索引的下标去获取
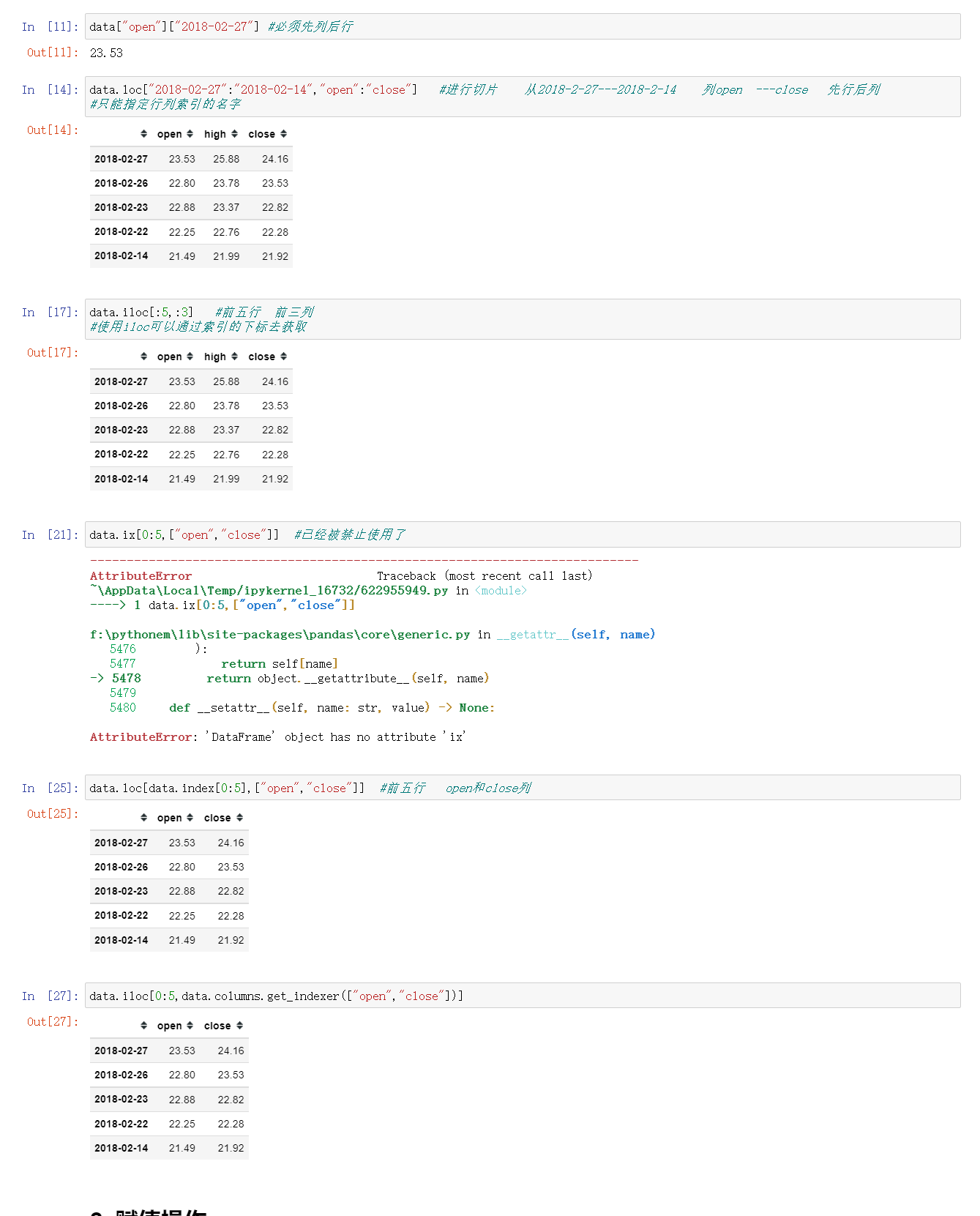
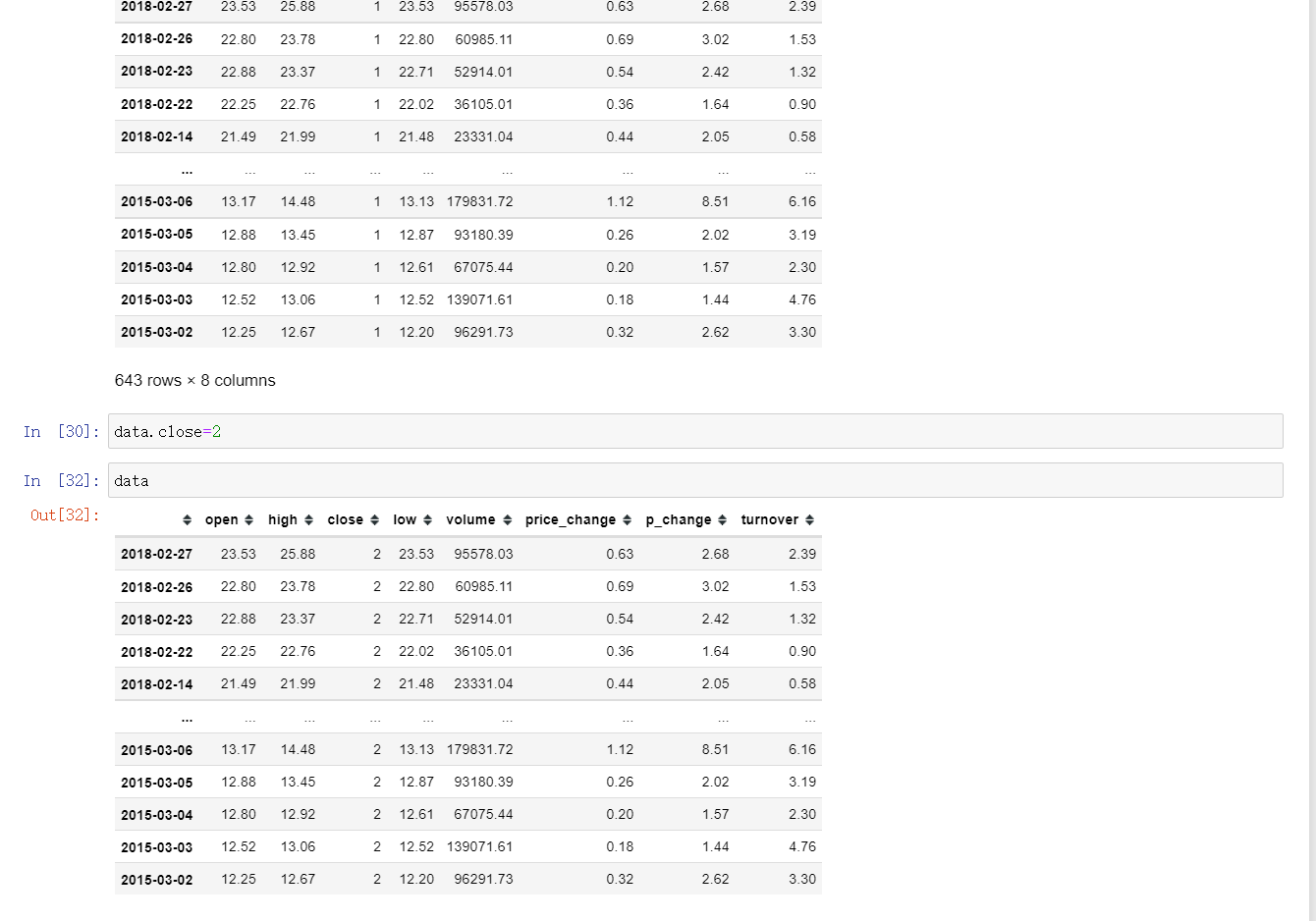
; 3.2 赋值操作
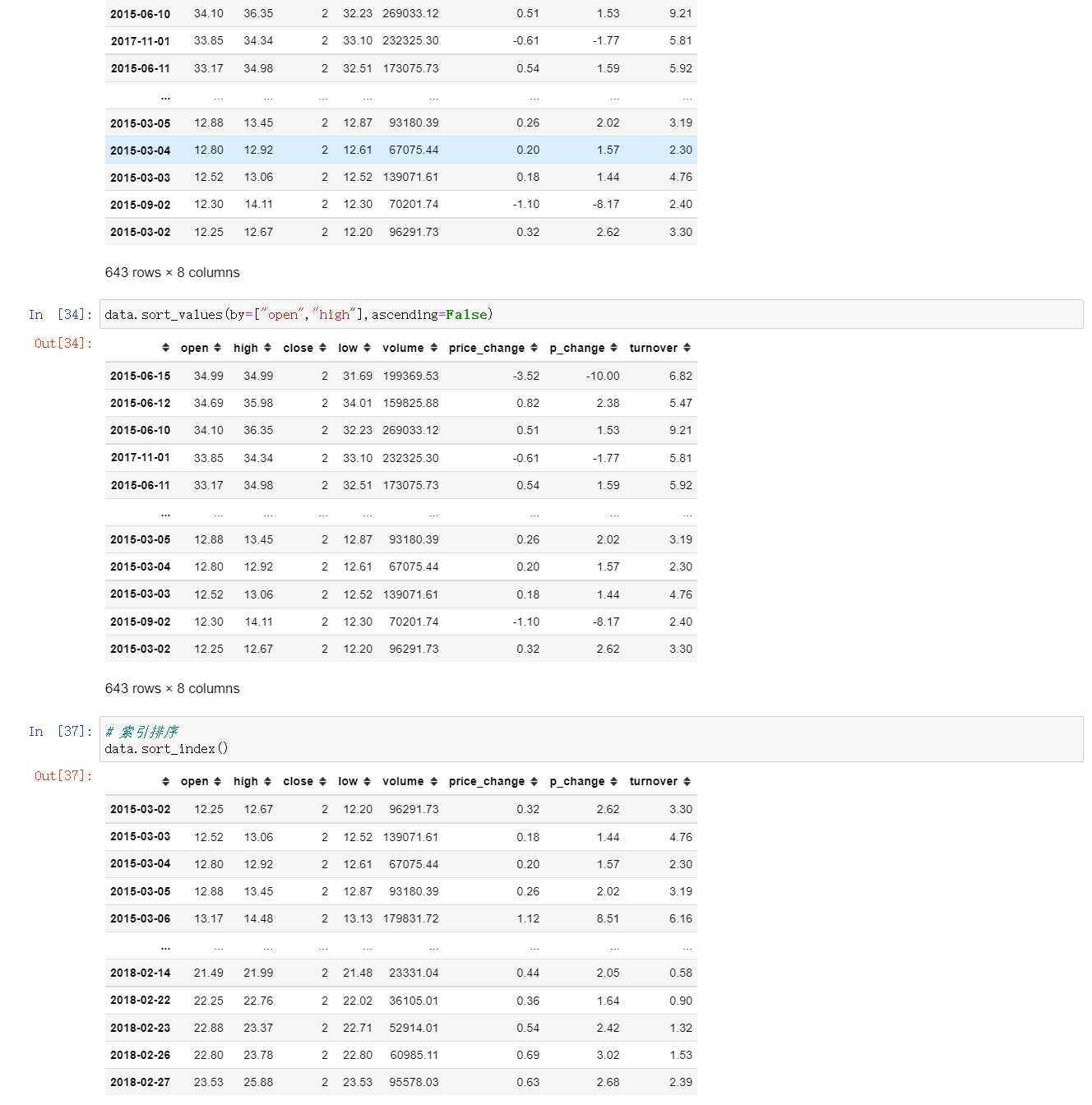
3.3 排序
1. DataFrame排序
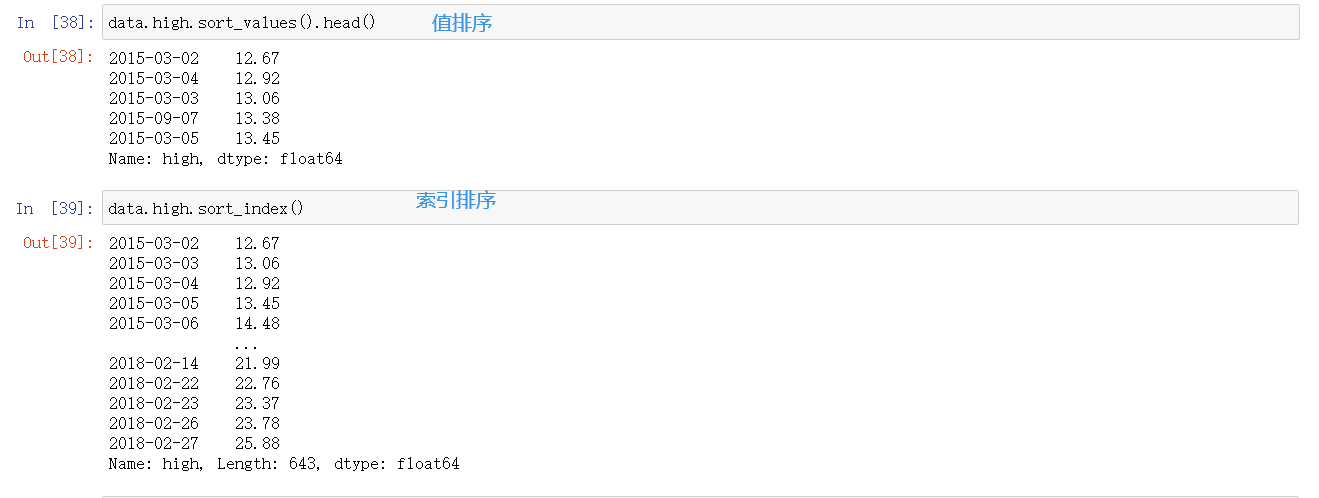
; 2. series排序
3.4. 总结

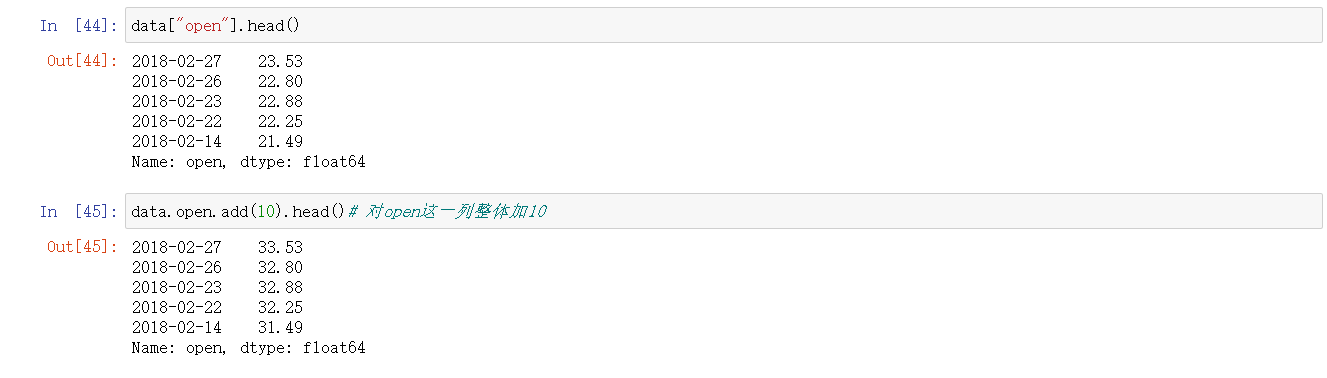
; 4. DataFrame运算
4.1 算术运算
; 4.2 逻辑运算
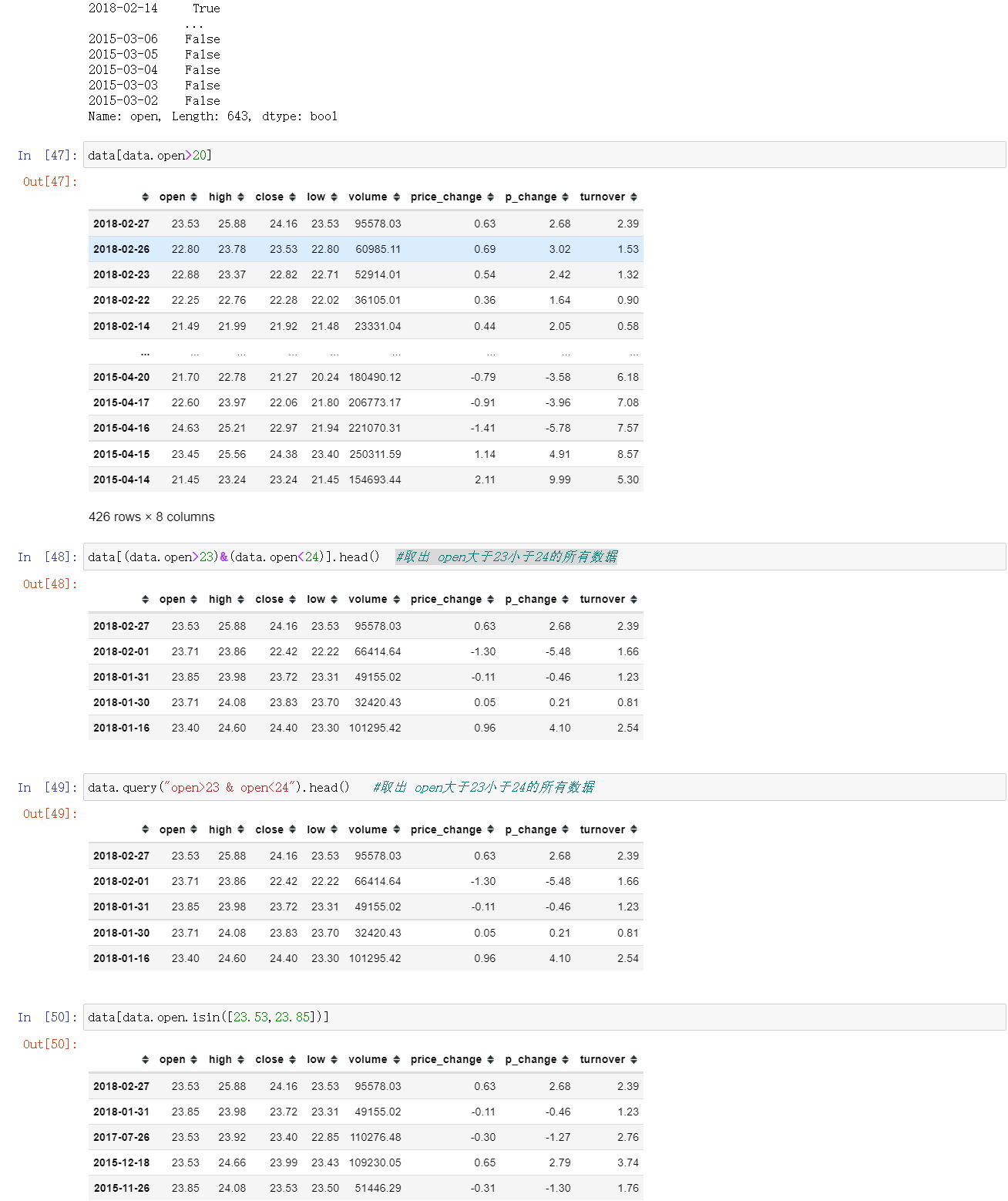
4.3 统计运算
- Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)结果:
- 对于单个函数去进行统计的时候,坐标轴还是按照默认列”columns” (axis=0, default),如果要对行”index” 需要指定(axis=1)
- 方差 data.var(0) 标准差 data.std(0)
- median():中位数
- 求出最大值的位置idxmax()、求出最小值的位置idxmin()


; 4.4 自定义运算
apply(func, axis=0) func:自定义函数 axis=0:默认是列,axis=1为行进行运算

- Pandas画图
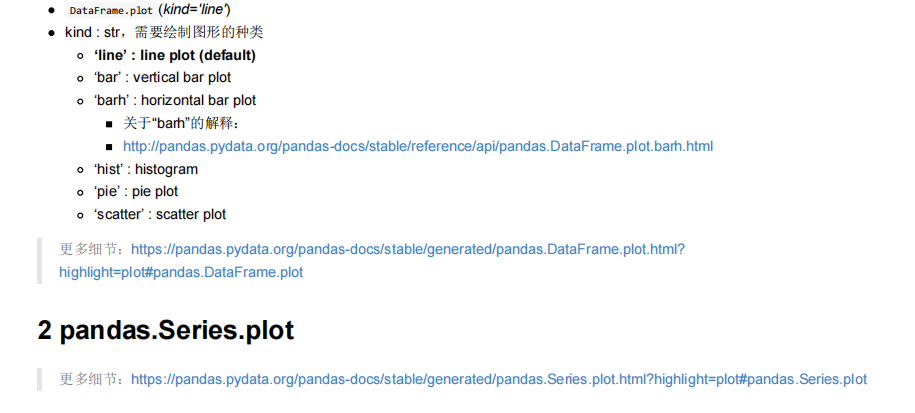
更多细节
pandas.Series.plot
; 6. 读取文件
6.1 csv


; 6.2 hdf5

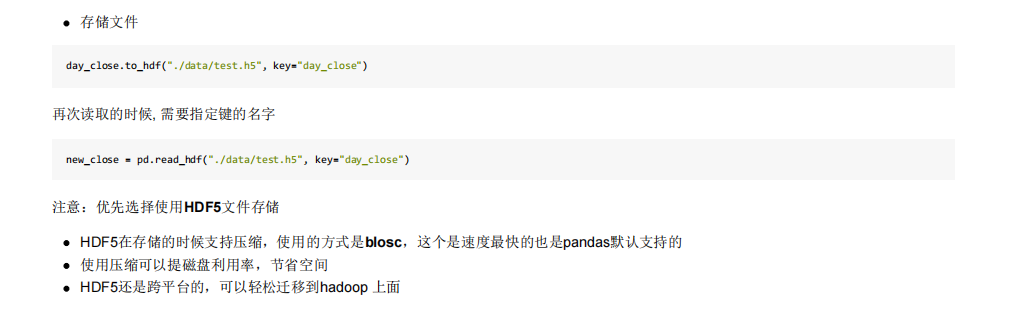
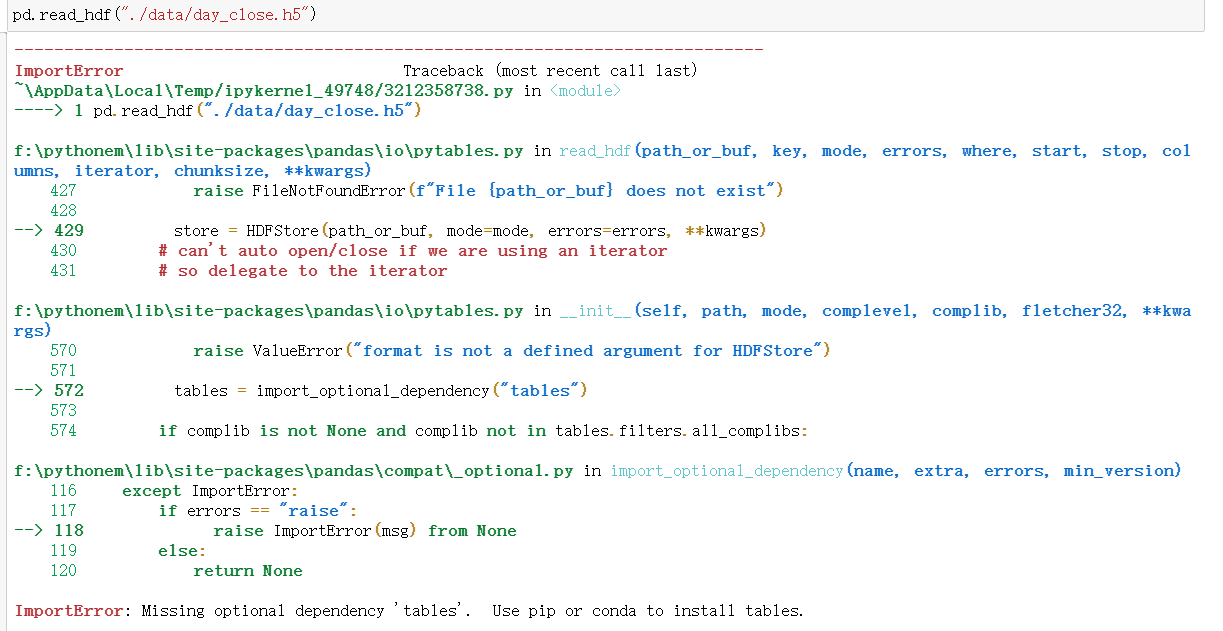

我这里遇到错误了 还没解决
后面解决
6.2 JSON
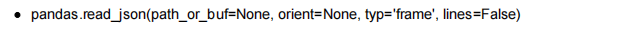

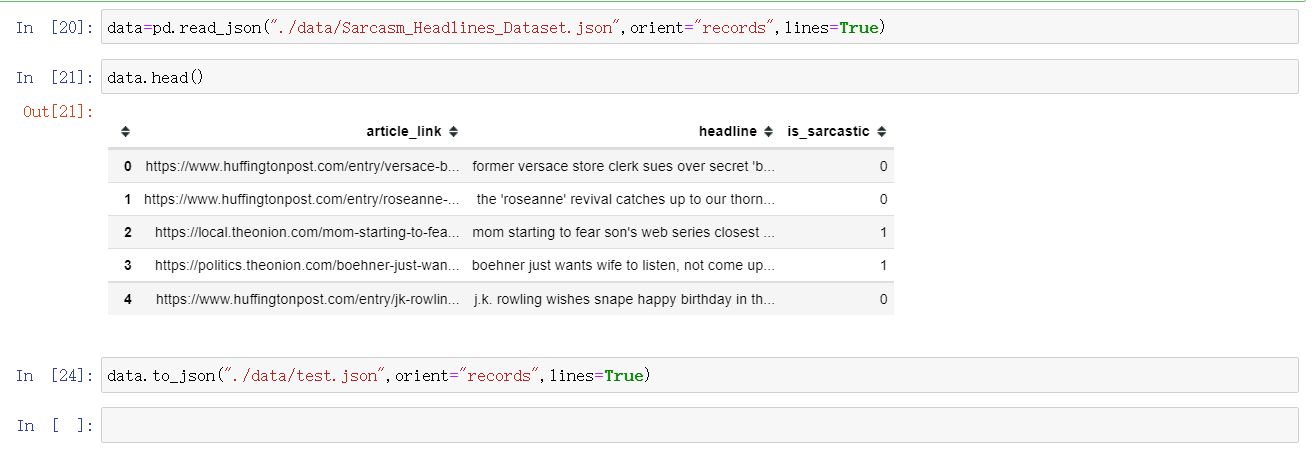
; 7. 高级数据处理
7.1 缺失值处理
- 应用isnull判断是否有缺失数据NaN
- 应用fillna实现缺失值的填充
- 应用dropna实现缺失值的删除
- 应用replace实现数据的替换

; 1. 缺失值是Nan

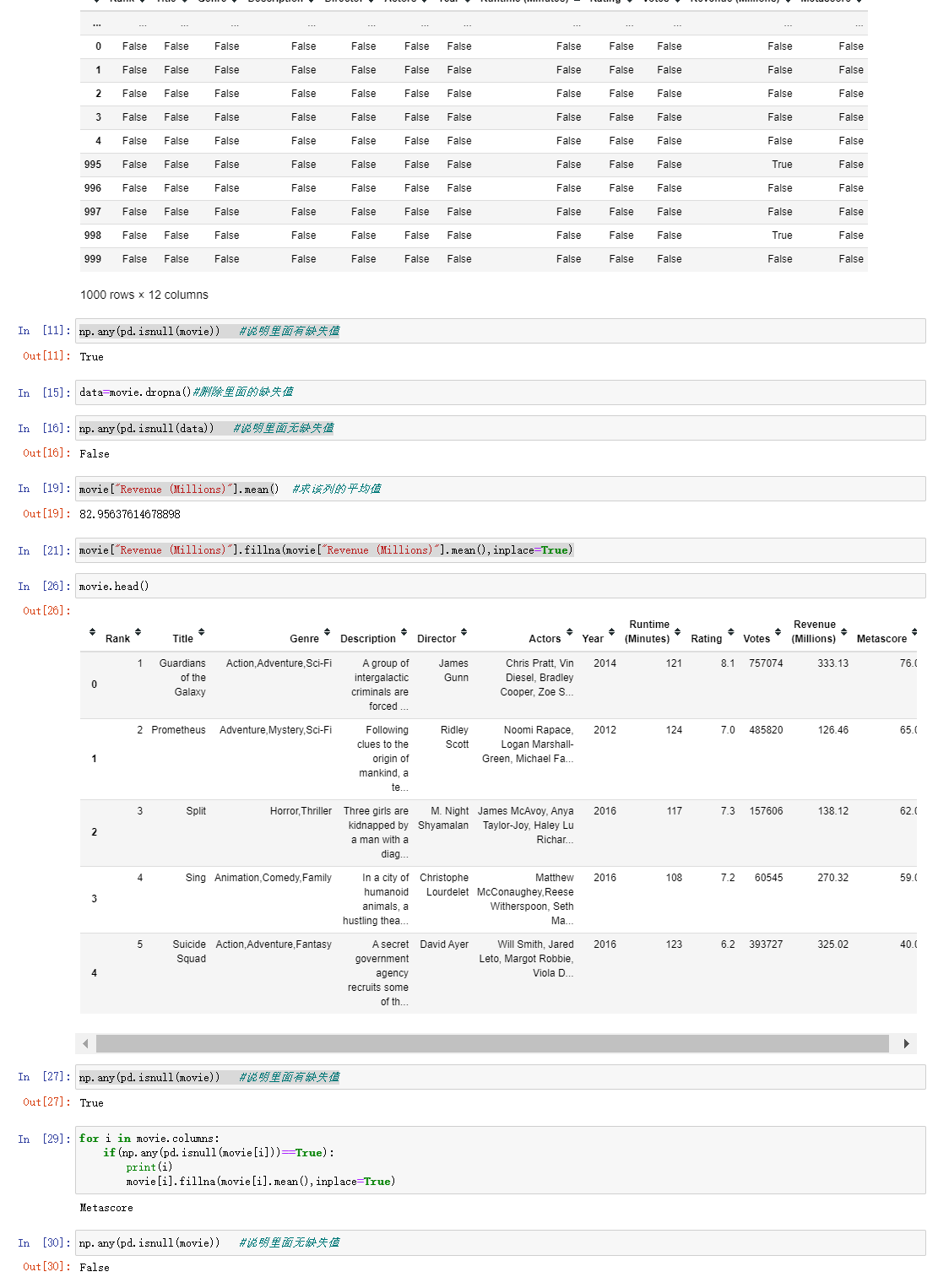
- movie.dropna() 不修改原数据
2. 缺失值是其他符号

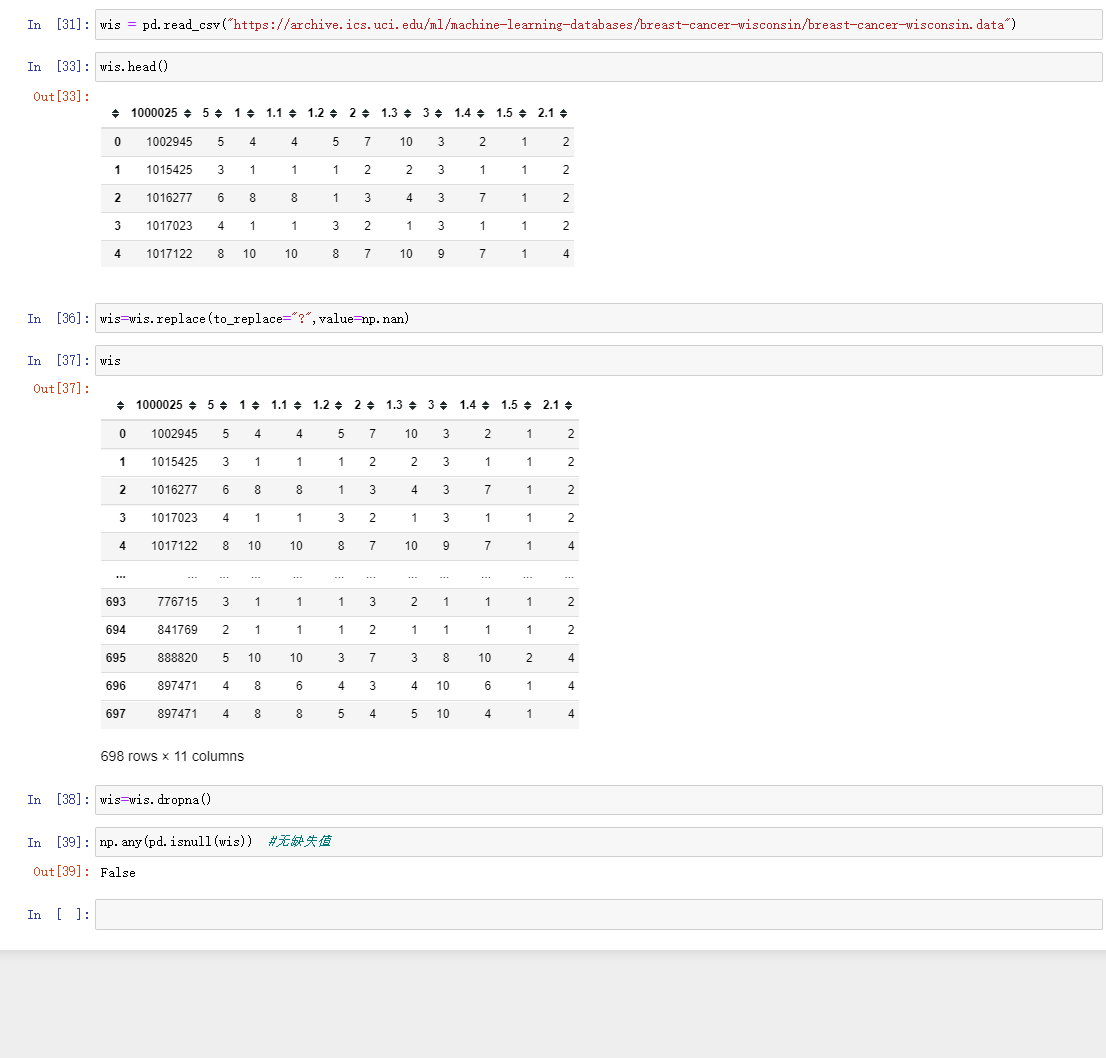
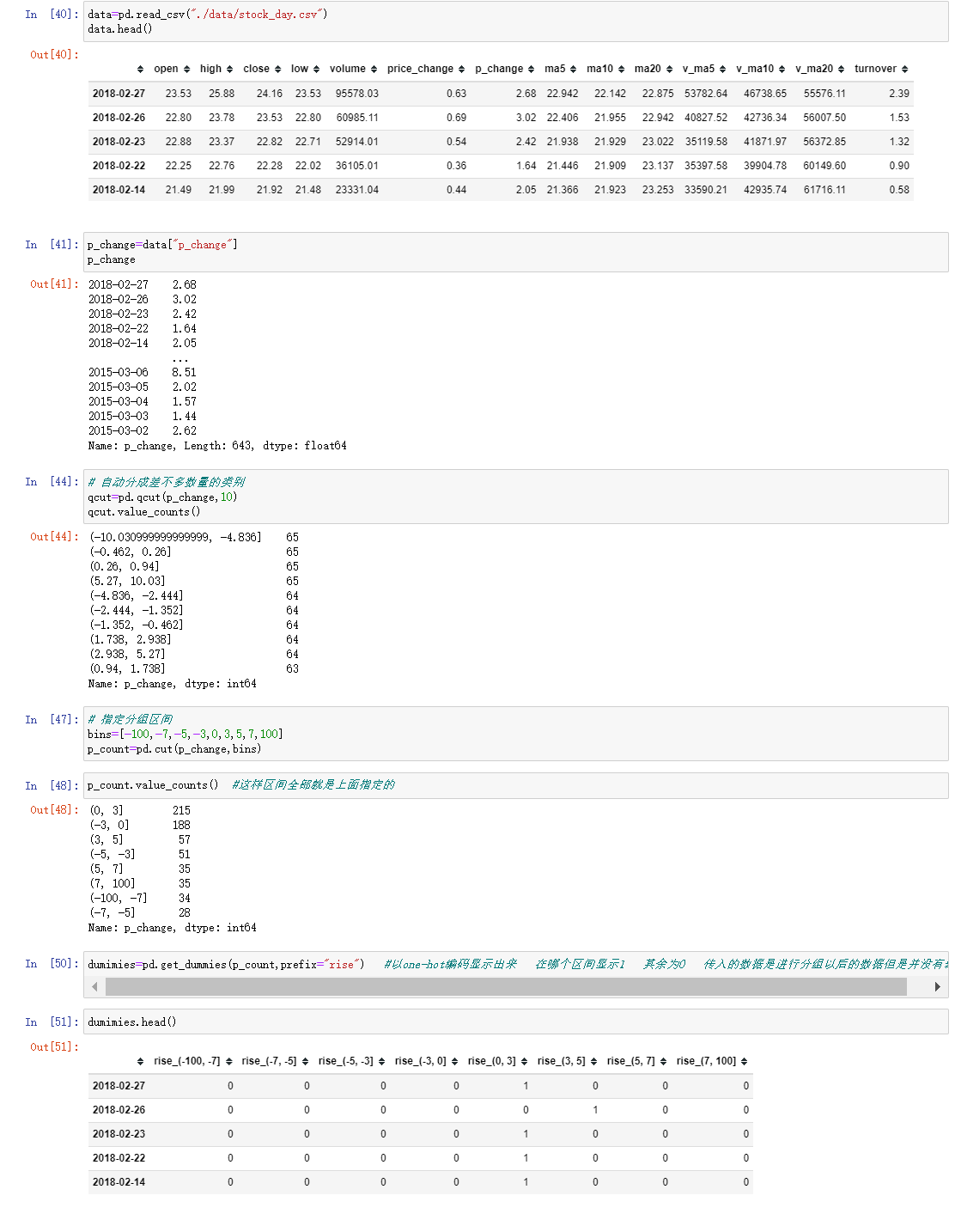
; 7.2 数据离散化
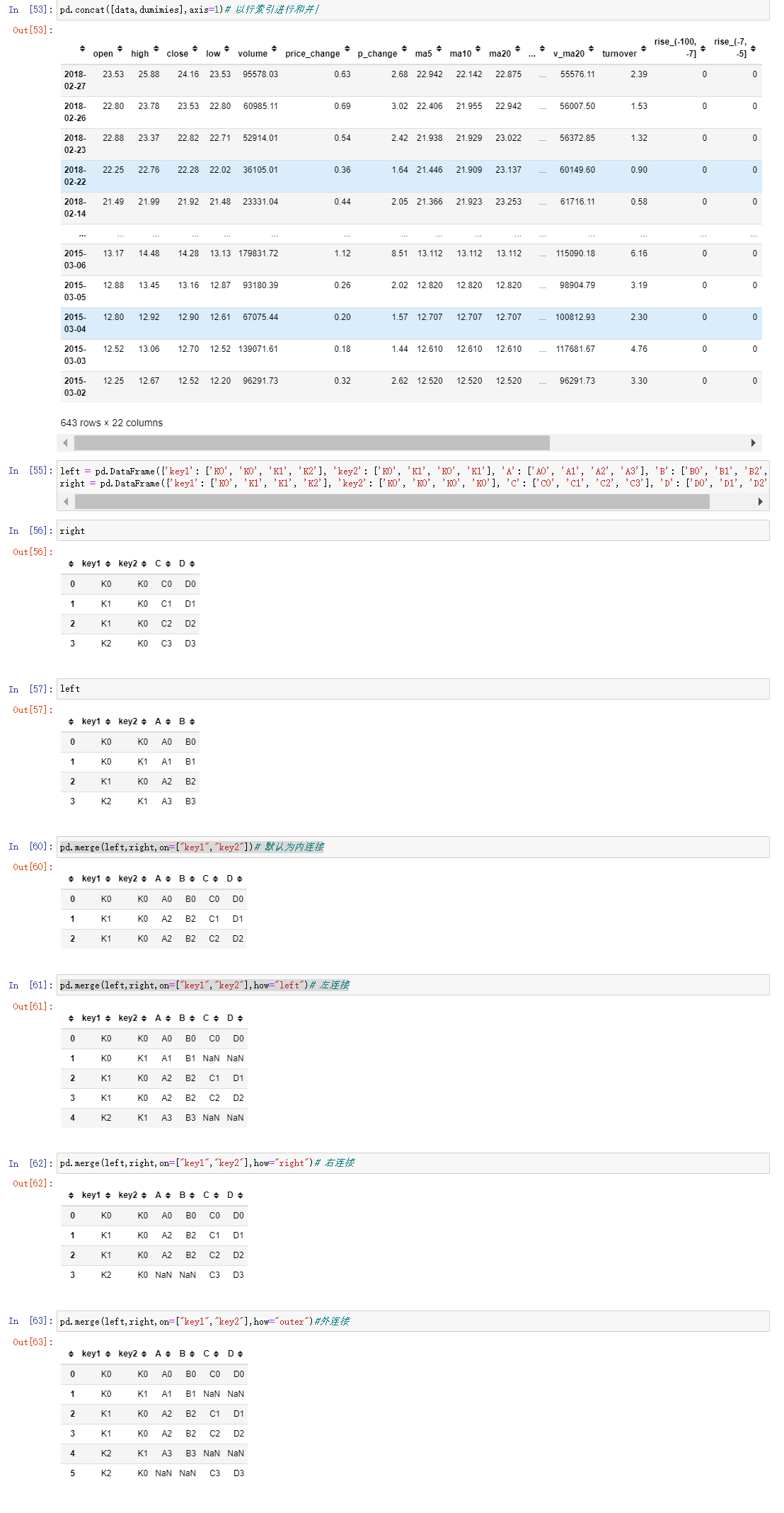
7.3 合并
; 7.4 交叉表和透视表
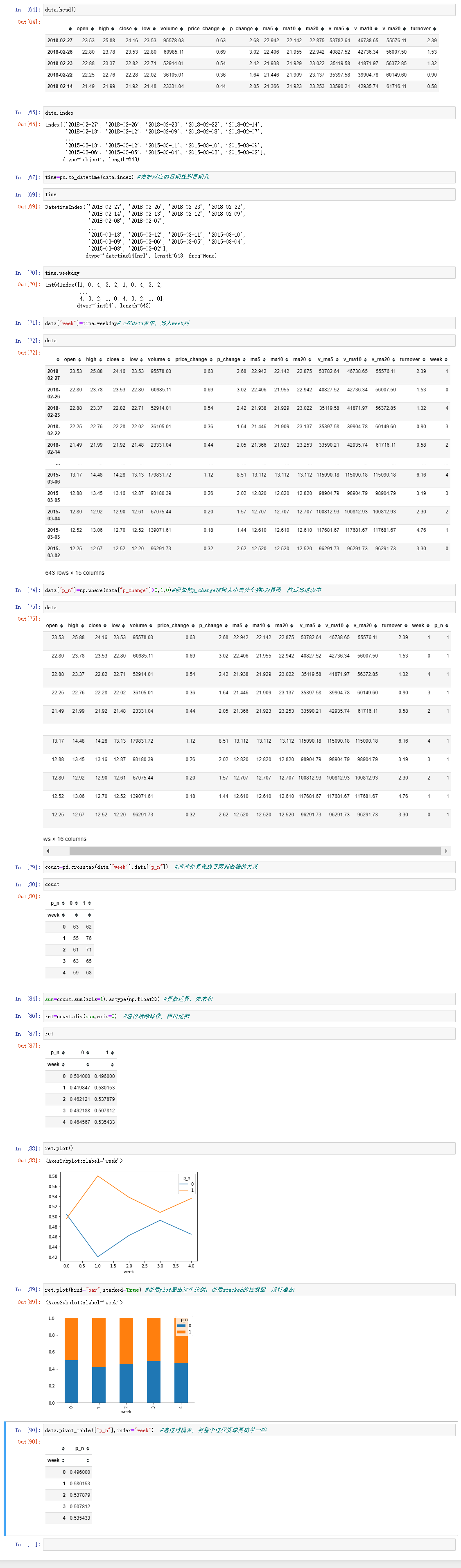
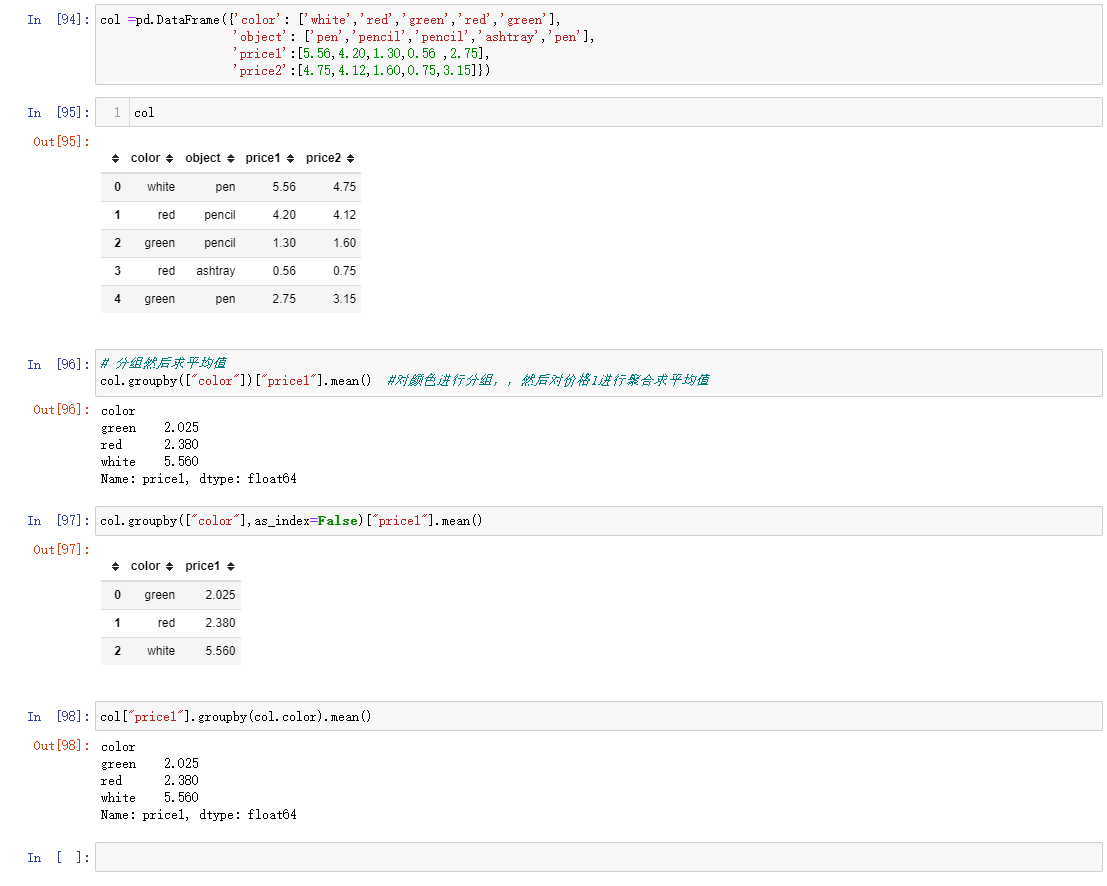
7.5 分组与聚合
Original: https://blog.csdn.net/qq_39759664/article/details/118500969
Author: 小玩偶啊
Title: Pandas的基本使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679662/
转载文章受原作者版权保护。转载请注明原作者出处!