

pandas
专 为 解 决 数 据 分 析 任 务 的 P y t h o n 库 \color{red}{专为解决数据分析任务的Python库}专为解决数据分析任务的P y t h o n 库提供高性能数据类型和分析工具,基于NumPy实现。
NumPy基础数据类型关注数据的结构表达维度:数据间关系Pandas扩展数据类型关注数据的应用表达数据与索引间关系
- 导入库
import pandas as pd
pandas库有两个数据类型:Series,DataFrame
Series
Series类型是由一组数据及与之相关的数据索引组成,有两个重要的属性
- .values属性:数据,np.array类型
- .index属性:索引,pd.indexes类型
Series创建
s = pd.Series(25,index=['a','b','c'])
y = pd.Series({'a':25,'b':25,'c':25})
yy = pd.Series({'a':9,'b':8,'c':7},index=['c','a','b','d'])
n = pd.Series(np.arange(5))
n1 = pd.Series(np.arange(5),index=np.arange(9,4,-1))
sindex = b.index
svalue = b.values
Series的切片
Series的切片会保存他的索引值
print('c' in b)
print(9 in b)
a = pd.Series([1,2,3],['c','b','e'])
print(a + b)
b['a']=15
b.name='Series'
Series是一个一维带”标签”的数组
DataFrame
DataFrame类型是由共用相同索引的一组列组成
DataFrame的特点:
- DataFrame是一个表格型的数据类型,每列值类型可以不同
- DataFrame既有行索引,也有列索引
- DataFrame常用于二维数据,但也可以表达多维数据
DataFrame的创建
方法一:pd.DataFrame(data=dict) data可以省略
dicts = {'one':[1,2,3,4],'two':[9,8,7,6]}
dict_df = pd.DataFrame(dicts)
方法二:pd.DataFrame.from_dict(data=dict) data可以省略
dicts = {'one':[1,2,3,4],'two':[9,8,7,6]}
dict_df = pd.DataFrame.from_dict(data=dicts)
方法三:pd.DataFrame(data) 直接写入字典类型的数据
dict_df = pd.DataFrame({'one':[1,2,3,4],'two':[9,8,7,6]})
dict_df = pd.DataFrame.from_dict({'one':[1,2,3,4],'two':[9,8,7,6]})
方法四:一维ndarray对象字典创建
dt = {'one':pd.Series([1,2,3,4]),
'two':pd.Series([9,8,7,6])}
ser_df = pd.DataFrame(dt)
方法五:二维ndarray对象字典创建
df =pd.DataFrame(np.arange(20).reshape(4,5))
DataFrame获取值
- 获取一列数值
dt = {'one':[1,2,3,4],'two':[9,8,7,6]}
dframe = pd.DataFrame(dt)
print(dframe['one'])


- 索引操作
dt = {'one':[1,2,3,4],'two':[9,8,7,6]}
dframe = pd.DataFrame(dt,index=['a','b','c','d'])
print(dframe.loc['a', 'two'])
print(dframe.loc['a'])
print(dframe.loc[:, 'one'])
print(dframe.loc['a':'b'])
print(dframe.loc[:, 'one':'two'])
print(dframe.iloc[0])
print(frame.iloc[:, 0])
print(frame.iloc[:2],)
print(frame.iloc[:, :2])
- DataFrame loc和iloc的区别
loc是通过标签进行选择(select by label)
iloc是通过位置进行选择(select by position)
DataFrame添加列
dt = {'one':[1,2,3,4],'two':[9,8,7,6]}
dframe = pd.DataFrame(dt)
new_column = ['No1','No2','No3','No4']
dframe.insert(1,'three',new_column)
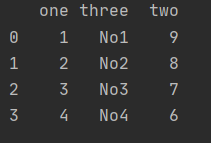
DataFrame默认是不允许添加重复的列的,如果想添加,需要修改allow_duplicates值,默认为False
dframe.insert(1,'three',new_column,allow_duplicates=True)

DataFrame添加行
dt = {'one':[1,2,3,4],'two':[9,8,7,6]}
dframe = pd.DataFrame(dt)
new_index = [5,5]
dframe.loc[4] = new_index
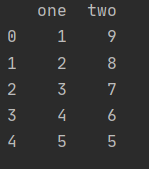
值得注意的是:loc实际是 改操作,如果loc[index]中的index存在,那么就会替换原本index上的值
DataFrame的重建索引
.reindex()参数说明index,columns自定义索引fill_value重新索引后,用于填充空位置的值method填充方法,ffill当前值向前填充,bfill向后填充limit最大填充量copy默认True,生成新的对象,False时,新旧相等不复制
s1 = pd.Series([7, -5, 3, 11], index=['bill', 'hope', 'mike', 'yana'])
print(s1.reindex(['mike', 'yana', 'lynn', 'vicky', 'hope']))
print(pd.Series(s1, index=['lynn', 'bill', 'mike']))
print(s1.reindex(['bill', 'yana', 'lynn', 'vicky'], fill_value=999))
print(s1.reindex(['d', 'e', 'a', 'z', 'j', 's'], method='ffill'))
print(s1.reindex(['d', 'e', 'a', 'z', 'j', 's'], method='bfill'))
- 关于ffill和bfill填充问题
有趣的是,如果有插入索引的问题,在索引填充时前向填充ffill会选取最后一个索引来进行填充;同理,后向填充bfill会选取最后一个索引后的值来进行填充,索引此时填充的即为NaN空值
Original: https://blog.csdn.net/flandreflor/article/details/111186356
Author: flandre翠花
Title: python数据分析————pandas库的数据结构Series和DataFrame的基本使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679481/
转载文章受原作者版权保护。转载请注明原作者出处!