



大家好,我是小五🧐
之前,主要是针对字符串进行一系列的操作。在此基础上我又扩展了几倍,全文较长,建议先收藏。
今天我们重新盘点66个Pandas函数合集,包括数据预览、数值数据操作、文本数据操作、行/列操作等等,涉及” 数据清洗“的方方面面。
Pandas 是基于NumPy的一种工具,该工具是为解决数据分析任务而创建的。它提供了大量能使我们快速便捷地处理数据的函数和方法。
数据预览
对于探索性数据分析来说,做数据分析前需要先看一下数据的总体概况。 info()方法用来查看数据集信息, describe()方法将返回描述性统计信息,这两个函数大家应该都很熟悉了。
describe方法默认只给出数值型变量的常用统计量,要想对DataFrame中的每个变量进行汇总统计,可以将其中的参数include设为all。
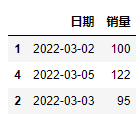
head()方法和 tail() 方法则是分别显示数据集的前n和后n行数据。如果想要随机看N行的数据,可以使用 sample()方法。
df.sample(3)
输出:
如果要检查数据中各列的数据类型,可以使用 .dtypes;如果想要值查看所有的列名,可以使用 .columns。
df.columns
输出:
Index(['日期', '销量'], dtype='object')
前面介绍的函数主要是读取数据集的数据信息,想要获得数据集的大小(长宽),可以使用 .shape方法。
df.shape
输出:
(5, 2)
另外, len()可以查看某列的行数, count()则可以查看该列值的有效个数,不包含无效值(Nan)。
缺失值与重复值
Pandas清洗数据时,判断缺失值一般采用 isnull()方法。此外, isnull().any()会判断哪些”列”存在缺失值, isnull().sum()用于将列中为空的个数统计出来。
df.isnull().any()
输出:
日期 False
销量 True
dtype: bool
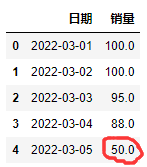
发现”销量”这列存在缺失值后,处理办法要么删除 dropna() ,要么填充 fillna()。
df.fillna(50)
输出:
Pandas清洗数据时,判断重复值一般采用 duplicated()方法。如果想要直接删除重复值,可以使用 drop_duplicates() 方法。此处较为常见,不再过多演示。
数值数据操作
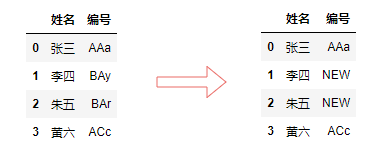
我们在处理数据的时候,会遇到批量替换的情况, replace()是很好的解决方法。它既支持替换全部或者某一行,也支持替换指定的某个或指定的多个数值(用字典的形式),还可以使用 正则表达式替换。
df["编号"].replace(r'BA.$', value='NEW', regex=True, inplace = True)
输出:
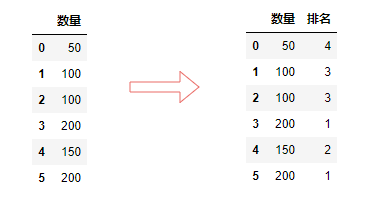
在Pandas模块中, 调⽤ rank()⽅法可以实现数据排名。
df["排名"] = df.rank(method="dense").astype("int")
输出:
rank()⽅法中的method参数,它有5个常⽤选项,可以帮助我们实现不同情况下的排名。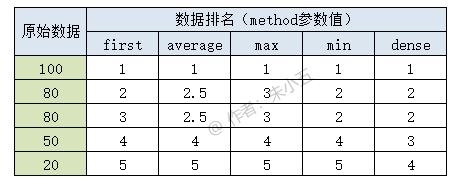
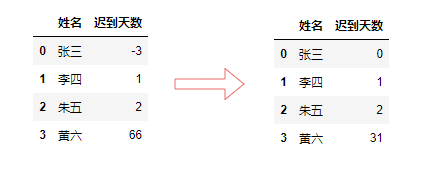
clip()方法,用于对超过或者低于某些数的数值进行截断[1],来保证数值在一定范围。比如每月的迟到天数一定是在0-31天之间。
df["迟到天数"] = df["迟到天数"].clip(0,31)
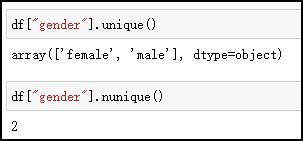
唯一值, unique()是以数组形式返回列的所有唯一值,而 nunique()返回的是唯一值的个数。
df["gender"].unique()
df["gender"].nunique()
输出:
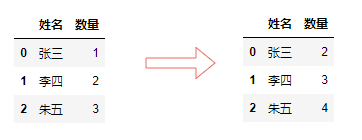
在数值数据操作中, apply()函数的功能是将一个自定义函数作用于DataFrame的行或者列; applymap()函数的功能是将自定义函数作用于DataFrame的所有元素。他们通常也与匿名函数lambda一起使用。
df["数量"].apply(lambda x: x+1)
输出:
文本数据操作
之前我们曾经介绍过。在对文本型的数据进行处理时,我们会大量应用字符串的函数,来实现对一列文本数据进行操作[2]。
函数方法用法释义cat字符串的拼接contains判断某个字符串是否包含给定字符startswith/endswith判断某个字符串是否以…开头/结尾get获取指定位置的字符串len计算字符串长度upper、lower英文大小写转换pad/center在字符串的左边、右边或左右两边添加给定字符repeat重复字符串几次slice_replace使用给定的字符串,替换指定的位置的字符split分割字符串,将一列扩展为多列strip、rstrip、lstrip去除空白符、换行符findall利用正则表达式,去字符串中匹配,返回查找结果的列表extract、extractall接受正则表达式,抽取匹配的字符串(一定要加上括号)
举例:
df.insert(2, "姓名",
df["姓"].str.cat(df["名"], sep=""))
输出:

df["手机号码"] = df["手机号码"].str.slice_replace(3,7,"*"*4)
输出:

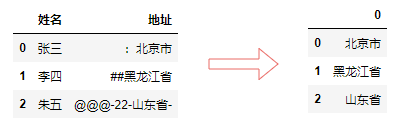
df["地址"].str.extract("([\u4e00-\u9fa5]+)")
输出:
行/列操作
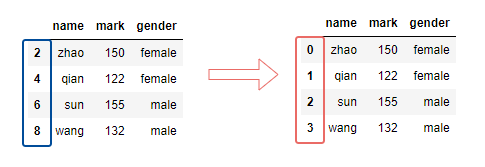
数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用 reset_index()重置索引。
df.reset_index(drop=True)
输出:
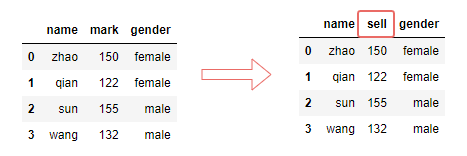
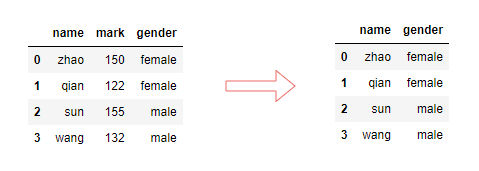
rename()重命名用于更改行列的标签,即行列的索引。可以传入一个字典或者一个函数。在数据预处理中,比较常用。
df.rename(columns={'mark': 'sell'}, inplace=True)
输出:
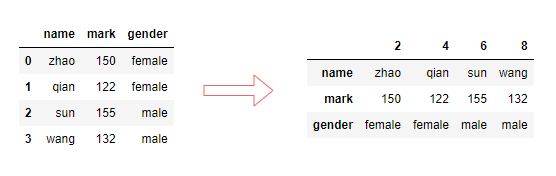
行列转置,我们可以使用T属性获得转置后的DataFrame。
df.T
输出:
删除行列,可以使用 drop()。
df.drop(columns=["mark"])
输出:
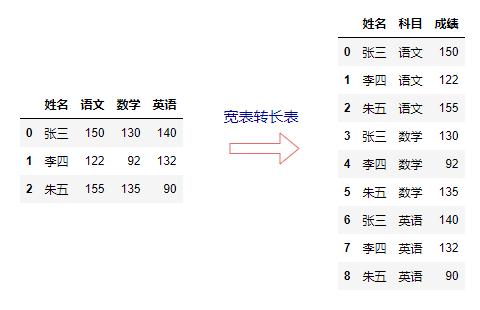
数据分析师在进行数据处理时经常会遇到长宽表互转的情况,这也是一道常见的数据分析面试题。
melt()方法可以将宽表转长表,即表格型数据转为树形数据。
df.melt(id_vars="姓名", var_name="科目", value_name="成绩")
输出:
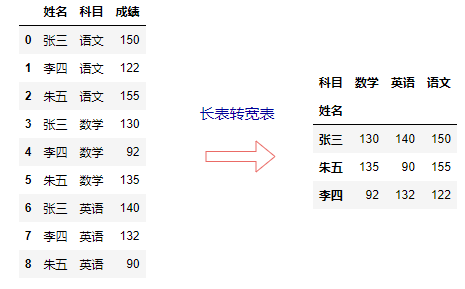
pivot()方法可以将长表转宽表,即树形数据转为表格型数据。
df.pivot(index='姓名', columns='科目', values='成绩')
输出:
pivot()其实就是用 set_index()创建层次化索引,再用 unstack()重塑
df1.set_index(['姓名','科目']).unstack('科目')

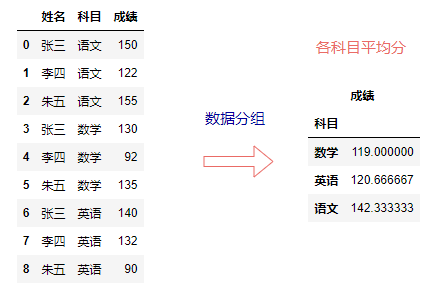
数据分组与数据透视表更是一个常见的需求, groupby()方法可以用于数据分组。
df.groupby("科目").mean()
由于 pivot_table()数据透视表的参数比较多,就不再使用案例来演示了,具体用法可参考下图。

数据筛选
如果是筛选行列的话,通常有以下几种方法:
有时我们需要按条件选择部分列、部分行,一般常用的方法有:
操作语法返回结果选择列 df[col]
Series按索引选择行 df.loc[label]
Series按数字索引选择行 df.iloc[loc]
Series使用切片选择行 df[:5]
DataFrame用表达式筛选行[3] df[bool_vec]
DataFrame
除此以外,还有很多方法/函数可以用于”数据筛选”。
如果想直接筛选包含特定字符的字符串,可以使用 contains()这个方法。
例如,筛选户籍地址列中包含”黑龙江”这个字符的所有行。
df[df["户籍地址"].str.contains("黑龙江")]
query()查询方法也可以用来筛选数据,比如查询”语文”成绩大于”数学”成绩的行记录。
df.query("语文 > 英语")
输出:

select_dtypes()方法可用于筛选某些数据类型的变量或列。举例,我们仅选择具有数据类型’int64’的列。
df.select_dtypes("int64")
输出:
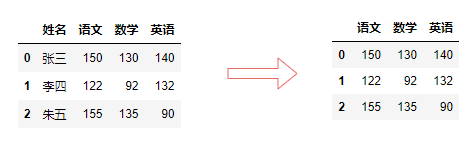
isin()接受一个列表,判断该列中元素是否在列表中。
name_list = ["张三", "李四"]
df[df["姓名"].isin(name_list)]
输出:

数值数据统计运算
在对数值型的数据进行统计运算时,除了有算术运算、比较预算还有各种常见的汇总统计运行函数,具体如下表所示。
函数方法用法释义count非NaN数据项计数sum求和mean平均值median中位数mode众数max最大值min最小值std标准差var方差quantile分位数skew返回偏态系数kurt返回峰态系数
举例:
df["语文"].max()
输出:
155
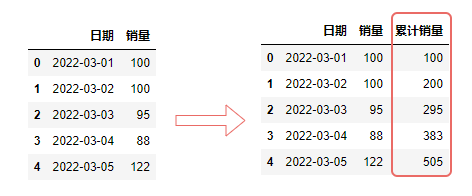
最后,再说一个比较常用的统计运算函数——累加 cumsum()。
df["累计销量"] = df["销量"].cumsum()
输出:
注: cumprod()方法是指连乘,用于与连加一样,但使用频率较少。
今天我们盘点了66个Pandas函数合集,但实际还有很多函数在本文中没有介绍,包括时间序列、数据表的拼接与连接等等。此外,那些类似 describe()这种大家非常熟悉的方法都省去了代码演示。如果大家有在工作生活中进行”数据清洗”非常有用的Pandas函数,也可以在评论区交流。
参考资料
[1]
小小明-Pandas的clip和replace正则替换: https://blog.csdn.net/as604049322/article/details/105985763
[2]
经常被人忽视的:Pandas文本型数据处理: https://mp.weixin.qq.com/s/Tdcb6jlyCc7XlQWZlvEd_w
[3]
深入浅出Pandas: 利用Python进行数据处理与分析

《深入浅出Pandas》这是一本全面覆盖了Pandas使用者的普遍需求和痛点的著作,基于实用、易学的原则,从功能、使用、原理等多个维度对Pandas做了全方位的详细讲解,既是初学者系统学习Pandas难得的入门书,又是有经验的Python工程师案头必不可少的查询手册。


点击这里,阅读更多数据文章!
Original: https://blog.csdn.net/zhuxiao5/article/details/123516304
Author: 朱小五是凹凸君呀
Title: 盘点66个Pandas函数,轻松搞定“数据清洗”!
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679327/
转载文章受原作者版权保护。转载请注明原作者出处!