

多层索引那些事(上)
又和大家见面了,不知道之前的内容大家笑话的怎么样了。这一期就和大家聊聊多层索引的那些事。
多层索引简介
多层索引是Pandas中一个比较核心的概念,允许在一个轴向上拥有多个索引层级,这样的设定会更加方便处理复杂的数据。因此,灵活的处理多层索引也是数据分析的必修课。
那么什么是多层索引呢?献给大家看个例子:
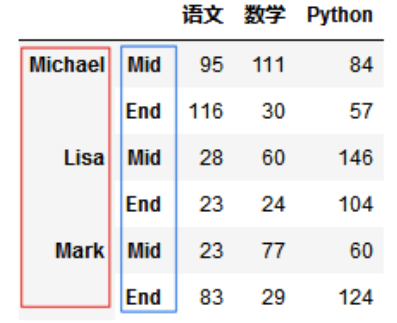

两层行索引;
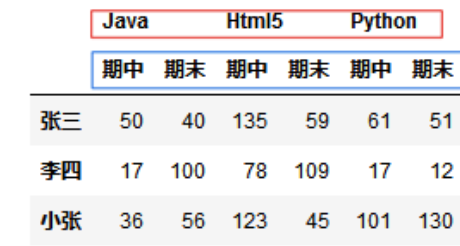
两层列索引。
看过前几篇文章的同学可能会有疑惑:这和使用groupby分组之后生成的内容很像啊!使用上节课的数据进行groupby分类,再使用.size()方法并输出,看看效果:
import pandas as pd
dic = {'ID':[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1011],
'name':['张三','李四','王五','赵六','孙七','周八','吴九','郑十','张三','王五','郑十'],
'age':[18,19,20,20,22,22,18,19,19,23,20],
'class':['大一','大二','大三','大三','研一','研一','大一','大二','大一','大三','大二'],
'high':[150.00,167.00,180.00,160.00,165.00,168.00,172.00,178.00,175.00,177.00,177.50],
'gender':['男','女','男','女','男','男','女','男','男','男','男'],
'hobby':['小提琴','围棋','象棋','羽毛球','游泳','看小说','刷抖音','王者','钢琴','篮球','竖笛']}
df=pd.DataFrame(data = dic,
index = ['a','b','c','d','e','f','g','h','i','j','k'])
print(df.groupby(['class','gender']).size())

很像对不对?但是这段代码的输出结果多少和我们之前的图片例子有所不同。不过别急,学完这节课我们就可以把这些都联系起来了。
那没接下来我们开启今天的征程:学会如何处理多层索引的问题。
多层索引的创建
我们先从创建开始,DataFrame和Series都是允许多层索引出现的,我们想要让一组数据带有两个或者更多的索引,只需要按如下代码进行操作:
import pandas as pd
s = pd.Series([1,2,3,4,5,6],index=[['张三','张三','李四','李四','王五','王五'],
['期中','期末','期中','期末','期中','期末']])
print(s)
import numpy as np
data = np.random.randint(50,100,size=(6,3))
df = pd.DataFrame(data,index=[['张三','张三','李四','李四','王五','王五'],
['期中','期末','期中','期末','期中','期末']],
columns=['Java','Web','Python'])
print(df)
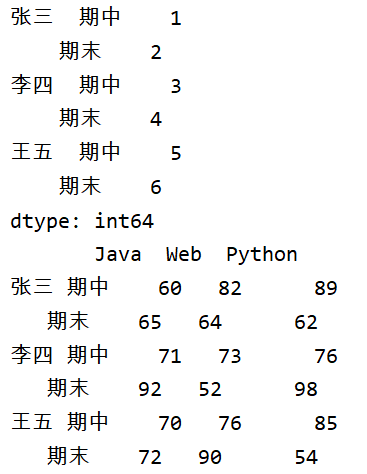
仔细观察我们对行索引的定义:

从图中数据可以看出,张三那一列是数据的第一层索引,期中那一列是数据的第二层索引,而第二层索引值是和数据一一对应的。不难看出,无论是Series还是DataFrame类型,我们在创建多层索引的时候,名字和考试阶段必须一一对应才行,这无形之中会增加我们的工作量,并且会增加出错误的可能。
Pandas为了解决这个问题,提供了一个创建多层索引的构造方法:pd.MultiIndex.from_product()。我们只需要提供一个装载了去重后索引名的列表就可以创建多层索引了:
import pandas as pd
import numpy as np
data = np.random.randint(50,100,size=(6,3))
names = ['张三','李四','王五']
exam = ['期中','期末']
index = pd.MultiIndex.from_product([names,exam])
df = pd.DataFrame(data,index=index,columns=['Java','Web','Python'])
print(df)
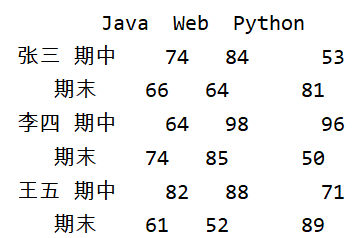
让我们调换一下name和exam在p.MultiIndex.from_product()方法中的位置,在观察一下结果:
index=pd.MultiIndex.from_product([exam,names])
df = pd.DataFrame(data,index,columns=['Java','Web','Python'])
print(df)
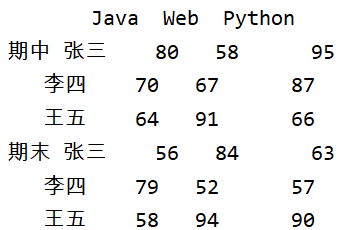
from_product([exam,names])会将列表中第一个元素作为最外层索引,依次类推;列表中元素值的对应关系,如下图:
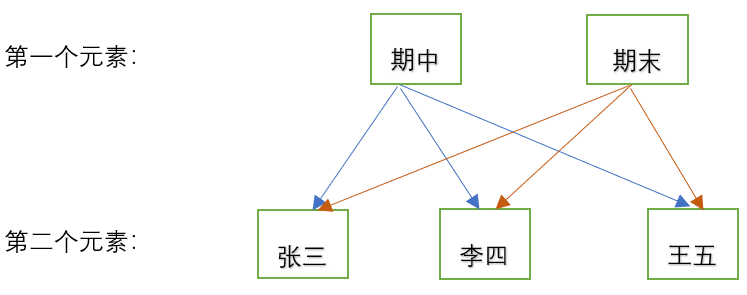
以此类推。有了图,就清晰了很多。接下来我们回收开头的问题:groupby分组之后生成的内容和多层索引又该如何联系起来呢?
使用groupby进行分类,对结果使用.size()方法只完成了分类,输出了每种分类对应的行数。想要把表格完整的输出,我们还需要构建新的DataFrame,代码示意如下:
import pandas as pd
dic = {'ID':[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1011],
'name':['张三','李四','王五','赵六','孙七','周八','吴九','郑十','张三','王五','郑十'],
'age':[18,19,20,20,22,22,18,19,19,23,20],
'class':['大一','大二','大三','大三','研一','研一','大一','大二','大一','大三','大二'],
'high':[150.00,167.00,180.00,160.00,165.00,168.00,172.00,178.00,175.00,177.00,177.50],
'gender':['男','女','男','女','男','男','女','男','男','男','男'],
'hobby':['小提琴','围棋','象棋','羽毛球','游泳','看小说','刷抖音','王者','钢琴','篮球','竖笛']}
df=pd.DataFrame(data = dic,
index = ['a','b','c','d','e','f','g','h','i','j','k'])
gro=df.groupby(['class','gender'])
a=[]
for i,j in gro:
a.append(j)
new_df=a[0]
for i in range(1,len(a)):
new_df=pd.concat([new_df,a[i]], axis=0, join='outer')
print(new_df)
来看看输出:
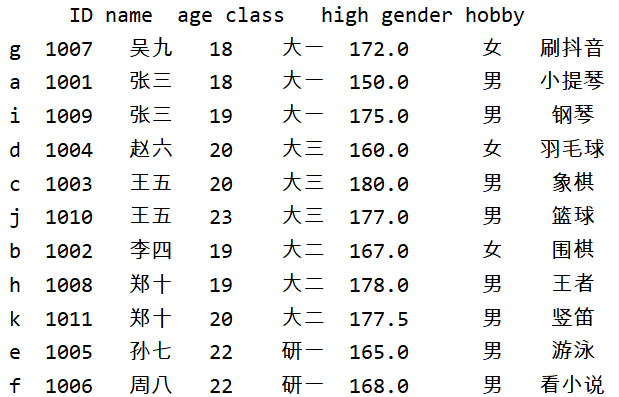
确实是我们想要的排序结果,但是打印出来的内容距离我们的期待还有一定差距。我们再使用一下.set_index()方法,重新定义一下行索引:
new_df=new_df.set_index(['class','gender']
print(new_df.set_index(['class','gender']))
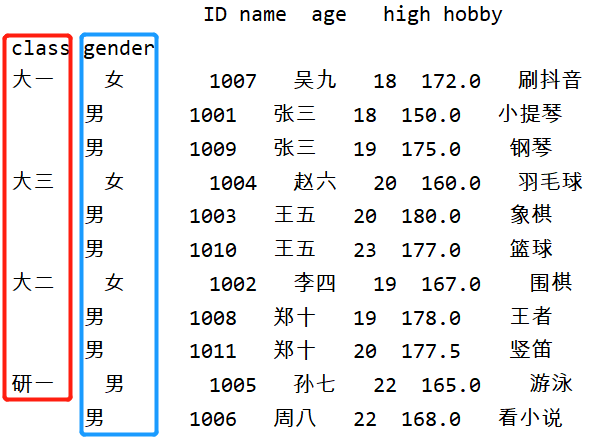
这样看起来是不是就一样了?当然,如果我们也可以把这个表格的行列索引互相调换,只要使用.T就可以了:
pd.set_option('display.max_columns',None)
pd.set_option('max_colwidth',100)
pd.set_option('display.width',1000)
print(new_df.set_index(['class','gender']).T)

需要注意的一点是,使用set_index方法后,前两列已经是行索引。
这篇文章介绍的内容有些多,因此多层索引的取值和排序问题留到下节再给大家介绍。大家先要先仔细学好多层索引的构建~
Original: https://blog.csdn.net/weixin_54929649/article/details/122360314
Author: 有理想的打工人
Title: 数据分析:数据处理篇5(1)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679129/
转载文章受原作者版权保护。转载请注明原作者出处!