

大家好,又是新的一周。大家一般会用 Pandas模块来对数据集进行进一步的分析与挖掘关键信息,但是当我们遇到数据集特别特别大的时候,内存就会爆掉,今天小编就来分享几个技巧,来帮助你避免遇到上述提到的这个情况。
read_csv() 方法当中的 chunksize 参数
read_csv()方法当中的 chunksize参数顾名思义就是对于超大 csv文件,我们可以分块来进行读取,例如文件当中有7000万行的数据,我们将 chunksize参数设置为100万,每次分100万来分批读取,代码如下
# read the large csv file with specified chunksize
df_chunk = pd.read_csv(r'data.csv', chunksize=1000000)
这时我们得到的 df_chunk并非是一个 DataFrame对象,而是一个可迭代的对象。接下来我们使用 for循环并且将自己创立数据预处理的函数方法作用于每块的DataFrame数据集上面,代码如下
chunk_list = [] # 创建一个列表chunk_list
# for循环遍历df_chunk当中的每一个DataFrame对象
for chunk in df_chunk:
# 将自己创建的数据预处理的方法作用于每个DataFrame对象上
chunk_filter = chunk_preprocessing(chunk)
# 将处理过后的结果append到上面建立的空列表当中
chunk_list.append(chunk_filter)
# 然后将列表concat到一块儿
df_concat = pd.concat(chunk_list)
将不重要的列都去除掉
当然我们还可以进一步将不重要的列都给去除掉,例如某一列当中存在较大比例的空值,那么我们就可以将该列去除掉,代码如下
# Filter out unimportant columns
df = df[['col_1','col_2', 'col_3', 'col_4', 'col_5', 'col_6','col_7', 'col_8', 'col_9', 'col_10']]
当然我们要去除掉空值可以调用 df.dropna()方法,一般也可以提高数据的准确性以及减少内存的消耗
转变数据格式
最后我们可以通过改变数据类型来压缩内存空间,一般情况下, Pandas模块会给数据列自动设置默认的数据类型,很多数据类型里面还有 子类型,而这些子类型可以用 更加少的字节数来表示,下表给出了各子类型所占的字节数
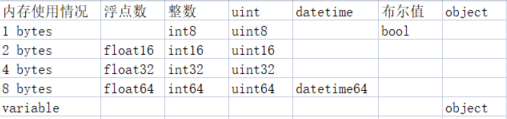

对于内存当中的数据,我们可以这么来理解,内存相当于是仓库,而数据则相当于是货物,货物在入仓库之前呢需要将其装入箱子当中,现在有着大、中、小三种箱子,

现在Pandas在读取数据的时候是将这些数据 无论其类型,都是 装到大箱子当中去,因此会在很快的时间里仓库也就是内存 就满了。
因此我们优化的思路就在于是 遍历每一列,然后找出该列的最大值与最小值,我们将这些最大最小值与子类型当中的最大最小值去做比较,挑选字节数最小的子类型。
我们举个例子, Pandas默认是 int64类型的某一列最大值与最小值分别是0和100,而 int8类型是可以存储数值在-128~127之间的,因此我们可以将该列从 int64类型转换成 int8类型,也就同时节省了不少内存的空间。
我们将上面的思路整理成代码,就是如下所示
def reduce_mem_usage(df):
""" 遍历DataFrame数据集中的每列数据集
并且更改它们的数据类型
"""
start_memory = df.memory_usage().sum() / 1024**2
print('DataFrame所占用的数据集有: {:.2f} MB'.format(start_memory))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
col_min = df[col].min()
col_max = df[col].max()
if str(col_type)[:3] == 'int':
if col_min > np.iinfo(np.int8).min and col_max np.iinfo(np.int16).min and col_max np.iinfo(np.int32).min and col_max np.iinfo(np.int64).min and col_max np.finfo(np.float16).min and col_max np.finfo(np.float32).min and col_max
大家可以将小编写的这个函数方法拿去尝试一番,看一下效果如何?!
NO. 1
往期推荐
Historical articles
分享、收藏、点赞、在看安排一下?




Original: https://blog.csdn.net/weixin_43373042/article/details/121917900
Author: 欣一2002
Title: 2000字详解 当Pandas遇上超大规模的数据集该如何处理呢?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679010/
转载文章受原作者版权保护。转载请注明原作者出处!