

记录使用plotly和pandas实现对数据的处理和绘制,如果要说的高级一点,那可以说是数据可视化
plotly是一个图表绘制的三方库,而pandas 则是专业对数据进行处理的三方库,使用pandas处理得到的数据,再配合使用plotly 则可以很好的实现数据的处理和展示。
常规的数据量小的图,可以用Excel 简单完成,但是数据量庞大一点,Excel就支撑不住了,例如数据量达到数万条的情况下,再使用Excel 进行绘图,不仅生成图时耗时会很久,同时Excel会陷入卡顿,使用体验是非常的不爽。
基于这种需求,我们可以采用pandas+plotly去替代实现,pandas做数据的提取,处理;plotly则将处理好的数据绘制成想要的图表
plotly有两种模式,一种是在线绘制,需要账户,可以将绘图保存在云端,一种是离线绘制,也就是本地绘制,保存在本地。保存在哪里不重要,重要的是怎么实现,怎么理解实现。
数据
先来份数据,从网易财经捞份股票数据,数据规整,省去数据缺失处理的麻烦, 部分数据如下:

; 单个维度分析
首先,先来分析一个简单的数据,分析所有时间内开盘价的波动情况。分析实现的思路:
需要的数据两列,一列是时间,另一列是开盘价,取出数据中的【时间】列作为横坐标,【开盘价】作为作为纵坐标,调用对应的模型画出图即可
import plotly.offline as py
import pandas as pd
import plotly.graph_objects as go
file_path='test_data.csv'
df=pd.read_csv(file_path)
time_column=df['日期']
opening_price=df['开盘价']
trace=go.Scatter(x=time_column,y=opening_price,mode="lines",name='开盘价')
layout=go.Layout(title='开盘价分析',xaxis={'title':'Time','tickangle':60},yaxis={'title': '开盘价'})
fig=go.Figure(trace,layout)
py.plot(fig)
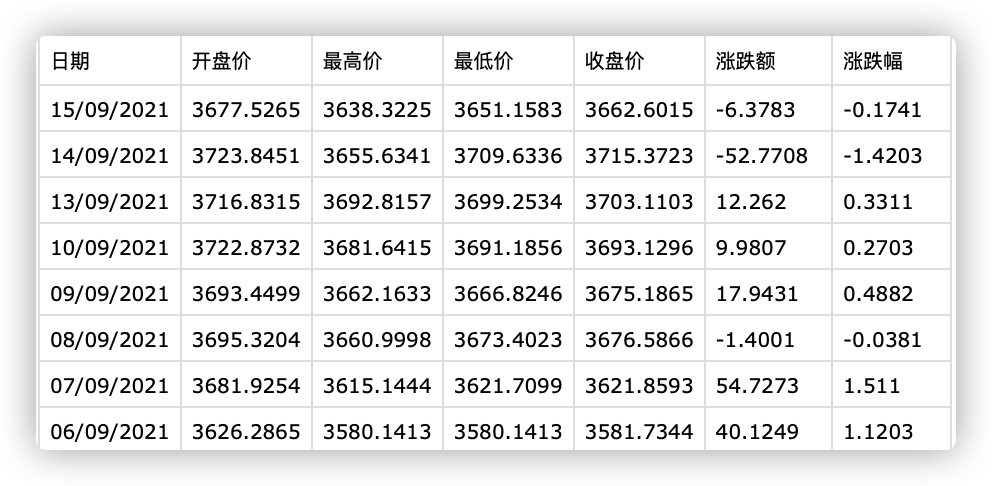
生成的对应的折线图:
可以明显看到开盘价使用折线图能够很好的展示价格的波动情况
按照这个思路,我们想要将所有的数据都展示出来,只需要加个循环,将数据循环读取并画出来即可
; 多个维度分析
import plotly.offline as py
import pandas as pd
import plotly.graph_objects as go
file_path='test_data.csv'
df=pd.read_csv(file_path)
column_head_list=df.columns.values
time_column=df['日期']
trace_list=[]
for i in range(1,len(column_head_list)):
data_column = df[column_head_list[i]]
trace = go.Scatter(x=time_column, y=data_column, mode="lines", name=column_head_list[i])
trace_list.append(trace)
layout=go.Layout(title='财经数据分析',xaxis={'title':'Time','tickangle':60},yaxis={'title': '价格'})
fig=go.Figure(trace_list,layout)
py.plot(fig)
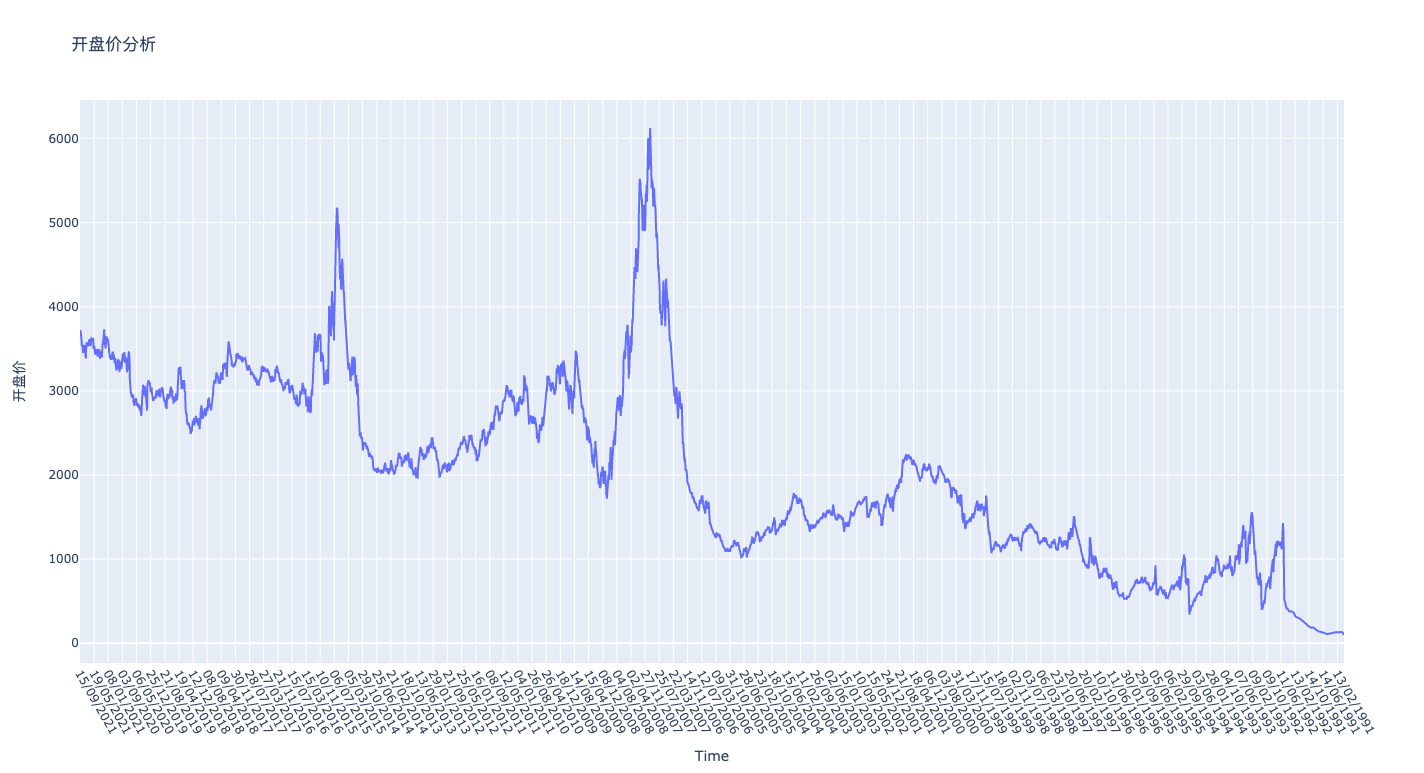
多维度结果
根据这个思路,可以得到相应的画图结果:
可以看到已经按照我们的要求实现所有数据列的绘制, X 轴显示时间,Y轴显示价格,右边显示图例标识不同的线的颜色代表的数据,大体上看上去没什么问题。
但是仔细查看源数据,我们发现数据的最后两列分别为涨跌额和涨跌幅,这两列和前几列价格数据差很大。涨跌额数据中存在大量的负数,而涨跌幅则是百分比,尤其是涨跌幅,和价格数据相差很大,不是一个量级,无法很好的体现数据的波动情况。
于是我们可以猜想,是否可以将各列数据分开来画图,在同一张画布上一次性将所有的数据分开绘制,能够更加直观的提现涨跌幅的数据波动情况
实现思路:
1.每个图都以时间列作为横坐标,对应列数据作为纵坐标
2.子图创建个数和列数一致
3.子图之前的间隔恒定
于是可以引入子图make_subplots作为一种实现方式:
; 多维度子图分析
import plotly.offline as py
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
file_path = 'test_data.csv'
df = pd.read_csv(file_path)
column_head_list = df.columns.values
fig = make_subplots(rows=len(column_head_list) - 1, cols=1)
for j in range(1, len(column_head_list)):
column_head = column_head_list[j]
trance = go.Scatter(x=df['日期'], y=df[column_head], mode="lines", name=column_head)
fig.append_trace(trance, j, 1)
fig.update_layout(width=1500, height=((len(column_head_list)-1))*600)
py.plot(fig)
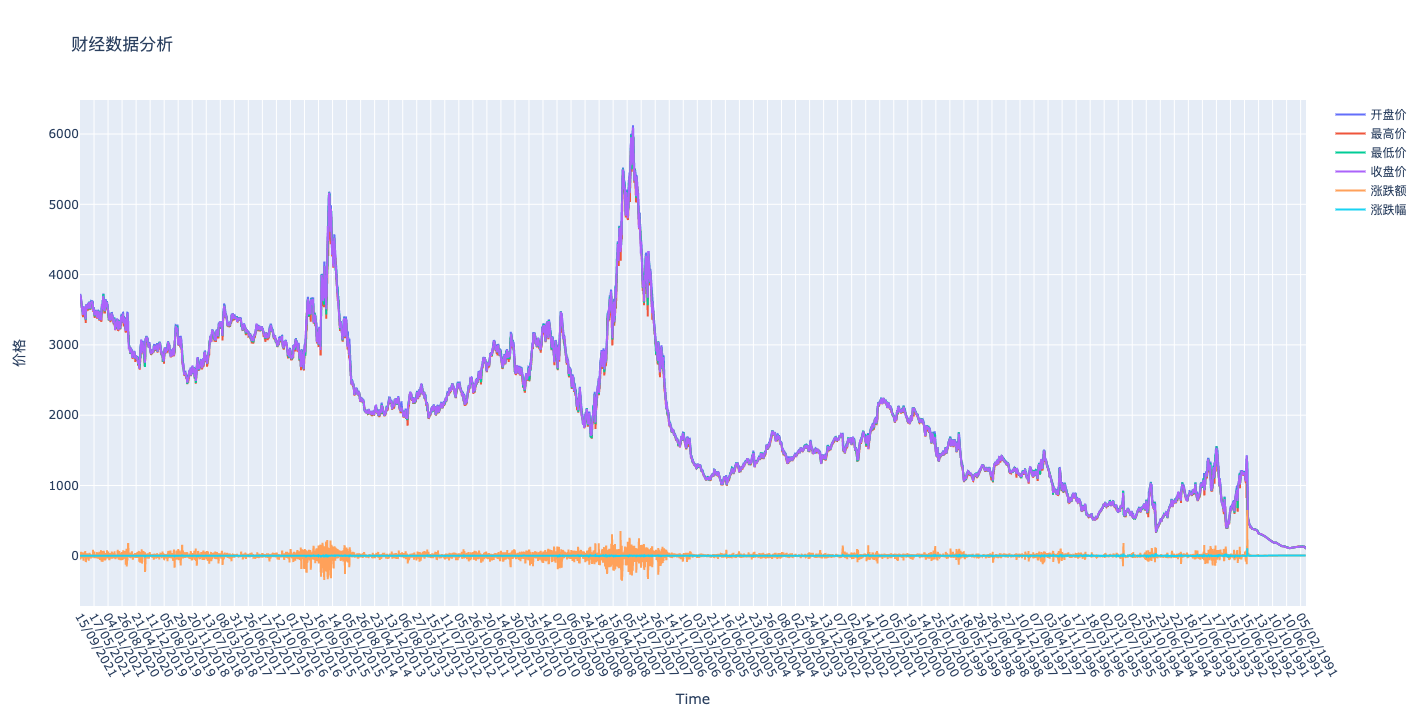
多维度子图展示
具体实现效果如下
可以看到,我们将不同维度的数据,展示在各个图上,可以直观的看到涨跌幅相较于价格的变化趋势。
; 多个文件分列展示在同一画布
在前面的基础上,增加一个使用场景:如果存在多个文件想要展示在同一个画布上的需求,可以做简单分析
如果有两个文件,可以分别将两个文件规划在两列,实现思路:
1.循环读取两个文件,存储为两个对象
2.两个文件的列数不一致的情况,取出列数中大的一个,作为子图的行数(因为子图行数是按照文件的列数去画的,取大的一个,使得另一个列数少的能够全部展示完,没有数据,则不做渲染)
3.分别将两个文件,规划在两列
import plotly.offline as py
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import os
files = ''
root = ''
for root, dir, files in os.walk('csv_file'):
print('all file name:', files)
df_list = []
column_list = []
for file in files:
file_name = root + '/' + file
df = pd.read_csv(file_name)
df_list.append(df)
column_num = len(df.columns.values)
column_list.append(column_num)
max_num = max(column_list)
fig = make_subplots(rows=max_num - 1, cols=len(files))
for i in range(len(df_list)):
df = df_list[i]
column_head_list = df.columns.values
for j in range(1, len(column_head_list)):
column_head = column_head_list[j]
trance = go.Scatter(x=df['日期'], y=df[column_head], mode="lines", name=column_head)
fig.append_trace(trance, j, i + 1)
fig.update_layout(width=1300, height=((len(column_head_list) - 1)) * 600)
py.plot(fig)
多文件子图展示
根据以上的思路,画出的图展示如下:
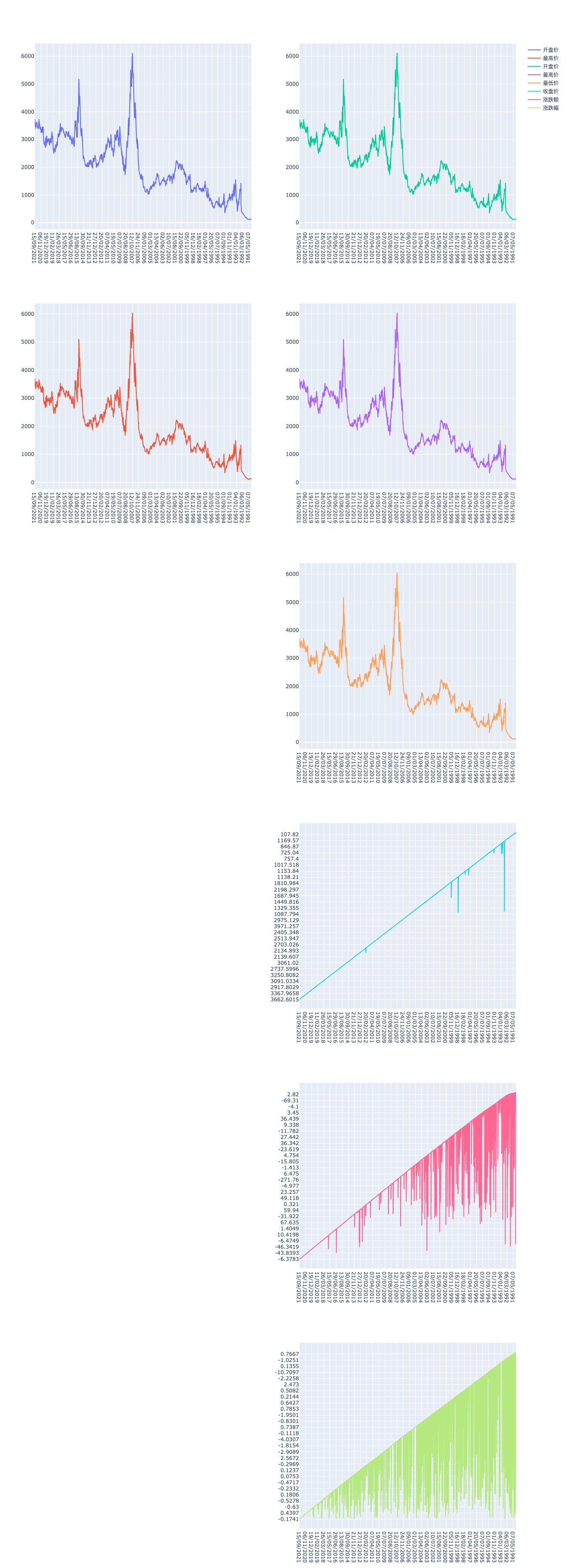
为了方便对比效果,没有让两个文件的列数一致
第一个文件只有两列,第二个文件则是所有数据,可以看到,我们取的列数较大的一个文件,也就是右边文件的列数,作为子图的行数,右边文件的子图全部展示,左边文件没有的列,则没有渲染,实际使用中也会比较灵活。
两个文件的情况还可以接受,文件过多则不建议使用这种方式,太多的列挤在一起,每个图个比例相应的被缩小,不是很利于观察。反之,我们可以将每个文件分别画在一个画布上,实现的方式和这个大同小异了。
欢迎来交流,有问题可以私信
更多的类型的图:https://plotly0icopy0site.4×5.top/
如果对你有帮助,可以请博主咖啡哟~~ ☕️

Original: https://blog.csdn.net/weixin_43643587/article/details/120353275
Author: Richard.sysout
Title: pandas+plotly实现数据图表的绘制和多维度下多个子图的展示
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678901/
转载文章受原作者版权保护。转载请注明原作者出处!