

我做的是从阿里天池下载的淘宝用户行为分析的数据集的数据分析项目。
下面使用的是anaconda jupyter Notebook 编辑器
第一次处理数据的时候没有什么异常,但当我在发现数据有点小异常,重新整理数据的时候就发现时间戳从2017年变成了1970年….
说实话。。。我蒙了。一开始以为是数据的问题,还重新去官网下载了一遍数据集。结果最后发现是时间戳数据类型有问题!
这是第一次处理的数据集:

然后修改时间戳
还挺正常…
这是第二次处理的数据集:
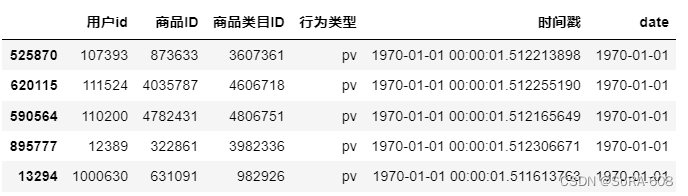
漂亮!出现问题了!对用户id随机抽样还全部都是1970年的同一个时间段!仔细研究了一下发现是时间戳的问题。
下面是解决办法:
首先用以下代码查看你的前五行数据的数据类型
df.head().info()
正常情况下,时间戳为object也就是字符串类型

之后再用
df['时间戳']=pd.to_datetime(df['时间戳'],unit='s')
才能转化为
有日期显示的时间戳类型
若你的时间戳类型为在转之前就是datetime类型,说明你在这之前就已经转换过或者你又重新执行了一次
若你的时间戳类型为int64类型,那么把它转化为字符串类型后再转化为datetime类型即可
df['时间戳']=df['时间戳'].astype('str')
若不能解答你的问题,这里附上两个答主的回答:
Original: https://blog.csdn.net/m0_57376367/article/details/125691174
Author: SoRA数据家
Title: 用python做数据分析时使用pd.to_datetime函数时间戳从1970年开始的情况
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678899/
转载文章受原作者版权保护。转载请注明原作者出处!