

目录
前言
遇到了批量合并根目录下大量不同格式文件并进行简单处理的需求,在网上没有搜到完全相同的处理,谨在此分享自己不成熟的代码,请大佬们批评指正。
一、代码展示
import os
import pandas as pd
import numpy as np
path =r"文件路径"
#文件所在的根目录
file_name = []
frames = []
print('以下文件未进行合并:\n')
for root,dirs,files in os.walk(path):
#遍历根目录下的每一个文件
for file in files:
if file[-3:]== 'xls' or file[-4:]== 'xlsx':
file_name.append(file)
df = pd.read_excel(os.path.join(root,file),skiprows = 0)
#将excel导入数据库,如需跳过行在skiprows中体现
df['数据批次'] = file[:-5]
#为数据库增加以文件名命名的数据批次列
frames.append(df)
else:
print(file,'未合并')
continue
print("-"*50)
print("已合并的文件为{}".format(file_name))
df1 = pd.concat(frames,sort=True,ignore_index=True)#重新设置索引
print("-"*50)
print("合并后数据的前五行:\n" ,df1.head())
print("-"*50)
print("合并后数据的行数和列数:",df1.shape)
print("-"*50)
df1.to_excel(r"文件保存路径")
print('——————合并完成——————')
二、主要函数
1.os.walk()
遍历根目录下的所有文件,输出文件名。格式如下:
os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]])
- top — 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
- topdown –可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
- onerror — 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks — 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
os.walk() 可以用于遍历多层文件夹下的所有文件,与 os.listdir(path) 只能用于一层文件列表不同。
与 os.path.isdir() 和 os.path.isfile() 结合使用,可分别输出根目录下文件夹名称列表和文件名称列表。
2.pd.concat()
pandas中著名的数据合并函数之一,格式如下:
pd.concat(
objs,
axis=0,
ignore_index=False,
join='outer',
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True
sort=sort,
)
主要参数:
- objs — 表达方式为[df1,df2,df3…]
- axis — 默认axis = 0,指拼接方式为横向或纵向,axis = 1时不会合并相同列。
- join — 默认’outer’,意为两者取并集,’inner’意为两者取交集。
- ignore_index — 是否统一重设索引,默认为False
- keys — 为每个合并项添加数据来源,但此项表达形式与数据列不同,如下图所示:
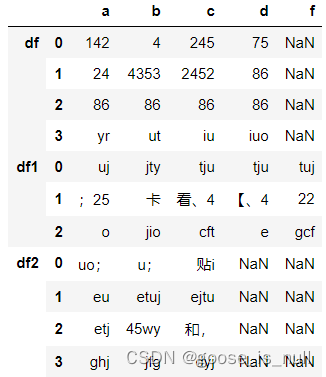

与 pd.merge() 作为区分的是, pd.concat()功能侧重于合并,可以对多个数据源进行操作,而pd.merge() 侧重于比对,按照一列中的关键字进行拼接,因此只能用于两个数据源之间
Original: https://blog.csdn.net/qq_45614048/article/details/125608624
Author: goose_is_null
Title: python合并根目录下所有表格文件并增加文件名索引
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678841/
转载文章受原作者版权保护。转载请注明原作者出处!