

文章内容是我自己学习pandas所做的一些笔记,知识点搭配案例,内容全面而详细。
目录
Series对象
●Pandas库中的一种数据结构,类似于一维数组
●由一组数据以及与这组数据有关的标签(索引)组成
●Series对象可以存储整数、浮点数、字符串、Python对象等多种数据类型的数据
●创建Series对象
pd.Series(data,index=index)
import pandas as pd
data=[‘语文’,’数学’,’英语’]
s=pd.Series(data=data,index=[‘张三’,’李四’,’王五’])
print(s)
张三 语文
李四 数学
王五 英语
dtype: object
●Series的索引
●位置索引
●索引范围[0,N-1]
●标签索引
●索引名称
●获取多个标签索引值使用[标签索引1,标签索…]
●切片索引
●[start:stop:step]
●获取Series的索弓|和值
●获取索引s.index
●获取值s.values
这是一个Series对象s
张三 语文
李四 数学
王五 英语
dtype: object
●位置索引
print(s[1]) >>>数学
●标签索引
print(s[‘李四’]) >>>数学
print(s[[‘张三’,’王五’]])
张三 语文
王五 英语
dtype: object
●切片索引
位置索引切片 含头不含尾
print(s[0:2])
张三 语文
李四 数学
dtype: object
标签索引切片 含头含尾
print(s[‘张三’:’王五’])
张三 语文
李四 数学
王五 英语
dtype: object
●Series的索弓|和值
s.values
[‘语文’ ‘数学’ ‘英语’]
s.index
Index([‘张三’, ‘李四’, ‘王五’], dtype=’object’)
DataFrame对象
●DataFrame对象是Pandas库中的一种数据结构,类似于二维数组,由行列构成
●与Series一样支持多种数据类型
●创建DataFrame对象
●pd.DataFrame(data,index,columns,dtype)
import pandas as pd
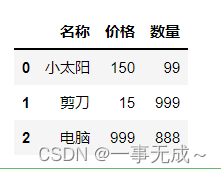
data=[[‘小太阳’,150,99],[‘剪刀’,15,999],[‘电脑’,999,888]]
columns=[‘名称’,’价格’,’数量’]
s=pd.DataFrame(data=data,columns=columns)
s
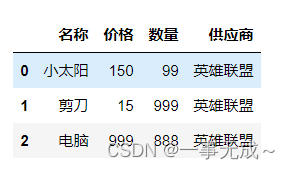
data={
‘名称’:[‘小太阳’,’剪刀’,’电脑’],
‘价格’:[150,15,999],
‘数量’:[99,999,888],
‘供应商’:’英雄联盟’
}
s=pd.DataFrame(data=data)
s
DataFrame对象的一些重要属性
1 values 查看所有元素的值
2 dtypes 查看所有元素的类型
3 index 查看所有行名、重命名行名
4 columns 查看所有列名、重命名列名
5 T 行列数据转换
6 head 查看前N条数据,默认5条
7 tail 查看后N条数据,默认5条
8 shape 查看行数和列数shape[0]表示行,shape[1]表示列
data={
'名称':['小太阳','剪刀','电脑'],
'价格':[150,15,999],
'数量':[99,999,888],
'供应商':'英雄联盟'
}
s=pd.DataFrame(data=data)
1 s.values

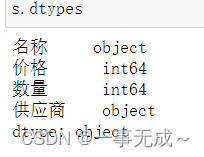
2 s.dtypes
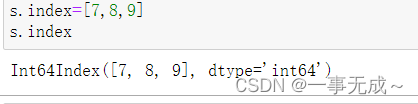
3 s.index
4 s.columns

5 s.T
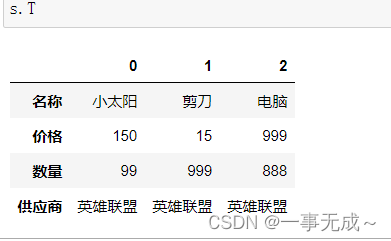
8 s.shape s.shape[0] s.shape[1]
(3,4) 3 4
DataFrame对象的一些重要方法
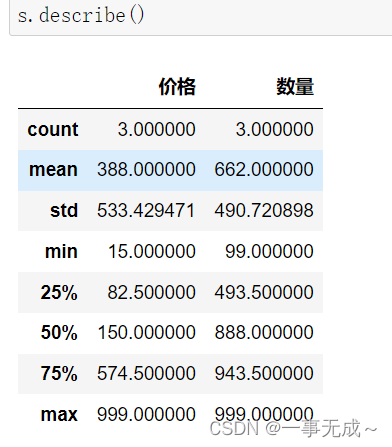
1 describe() 查看每列的统计汇总信息,DataFrame类型
2 count() 返回每一列的非空值的个数
3 sum() 返回每一列的和,无法计算返回空值
4 max() 返回每一列的最大值
5 min() 返回每一列的最小值
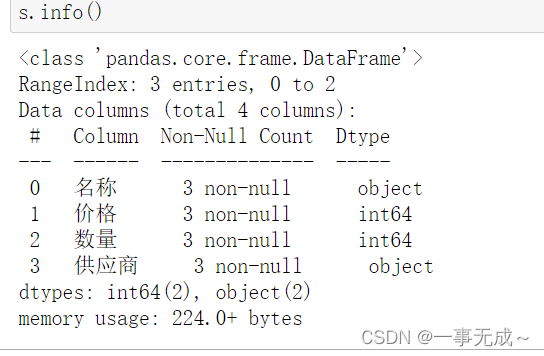
6 info() 查看索引、数据类型和内存信息



导入外部数据
导入.xIs或.xIsx文件
●导入.xIs或.xIsx文件
●pd.read excel(io,sheet name,header)
●常用参数说明
●io:表示.xIs或.xIsx文件路径或类文件对象
●sheet_name:表示工作表,用法如下
●header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None
sheet_ name=0 第一个Sheet页中的数据作为DataFrame对象
sheet_ name=1 第二个Sheet页中的数据作为DataFrame对象
sheet_ name= ‘Sheet1’ 名称为’Sheet1 ‘的Sheet页中的数据作为DataFrame对象
sheet name=[0,1,’Sheet3’] 第一 个第二个和名称为Sheet3的Sheet页中的数据作为DataFrame象
sheet_ name=None 读取所有工作表
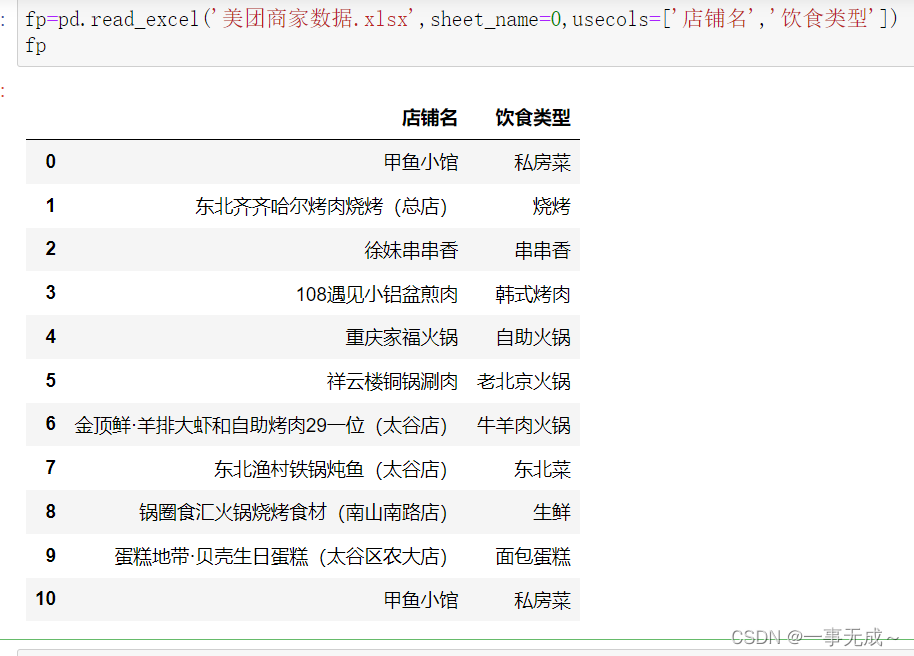
fp=pd.read_excel(‘美团商家数据.xlsx’,sheet_name=0,usecols=[‘店铺名’,’饮食类型’])
或fp=pd.read_excel(‘美团商家数据.xlsx’,sheet_name=0,usecols=[0,1])
导入csv文件
● pd.read_ csv(filepath or_ buffer ,sep=’,’,header,encoding= None)
● 常用参数说明
● filepath_ or _buffer:字符串、文件路径,也可以是URL链接
● sep:字符串、分隔符
● header:指定作为列名的行,默认值为0,即取第一行的值为列名。数据为除列名以外的数据,若数据不包含列表,则设置header= None
● encoding:字符串, 默认值为None,文件的编码格式
fp=pd.read_csv(r'C:\Users\xiaoxin15\Desktop\美食商家数据.csv',sep=',',encoding='gbk')
gbk对应ANSI
print(fp.head(5))
导入html网页数据

只可以读取含有table标签的网页
import pandas as pd
url=’http://www.espn.com/nba/salaries’
df=pd.concat(pd.read_html(url,header=0))
print(df)

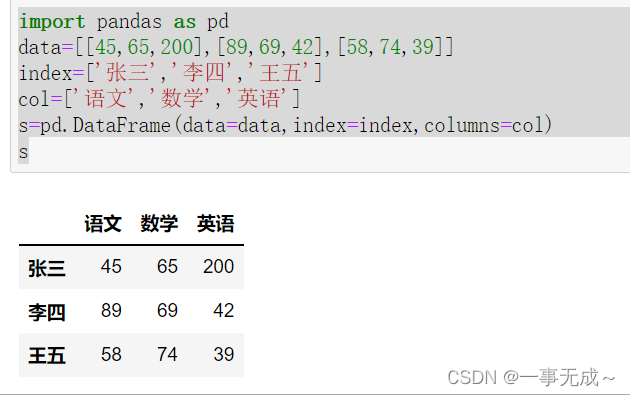
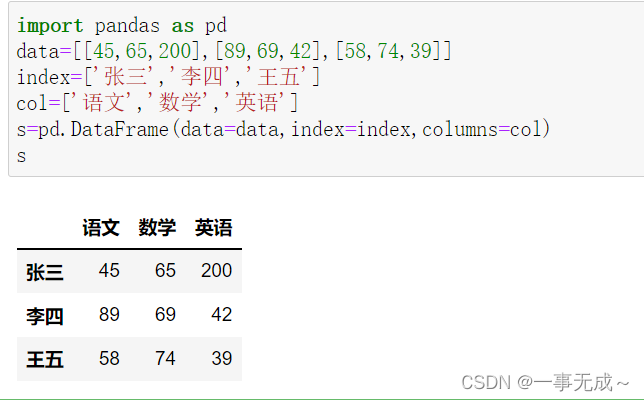
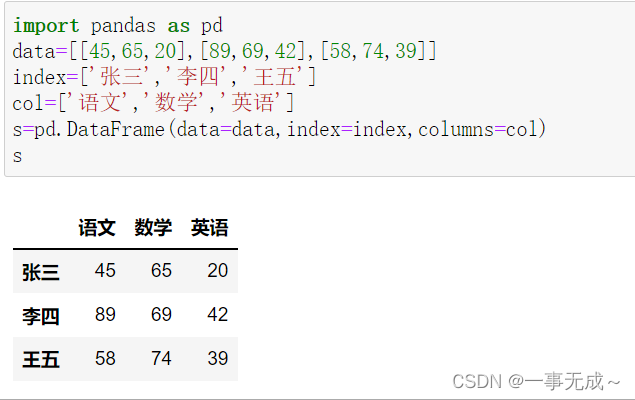
数据提取loc和iloc的使用
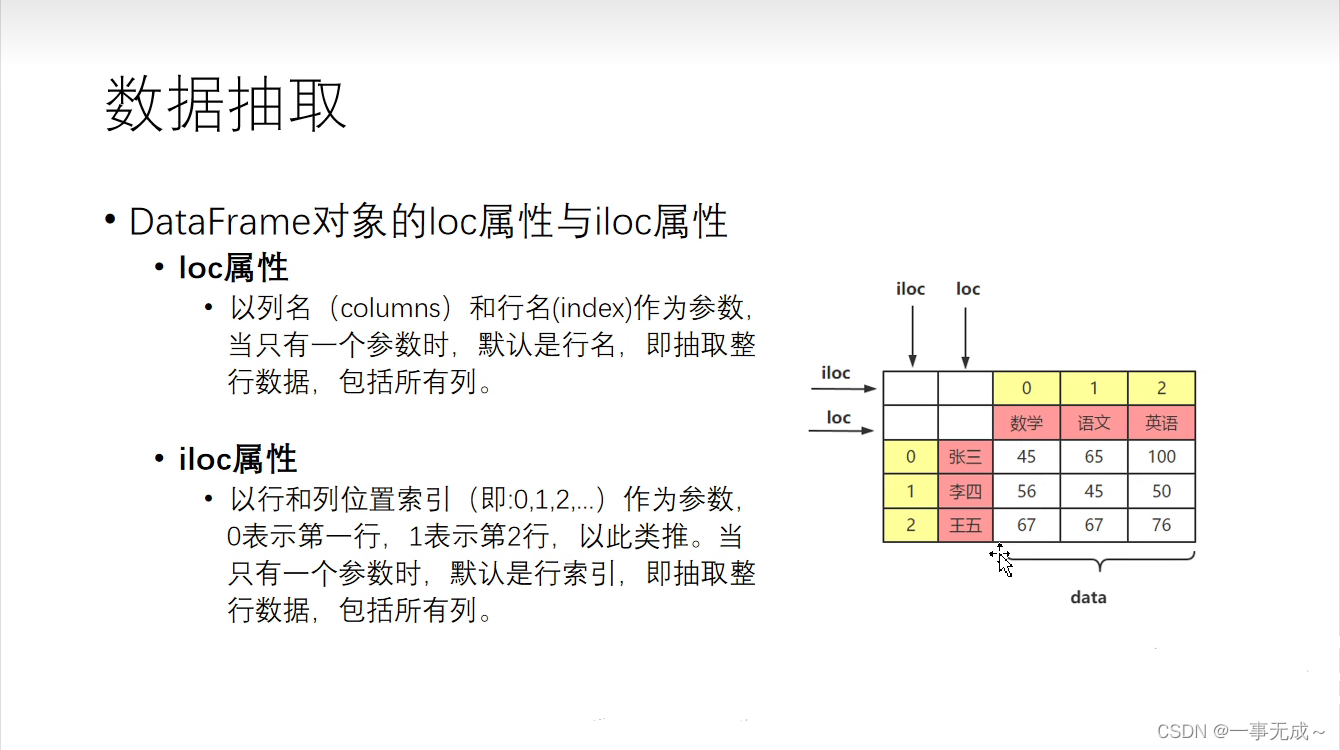
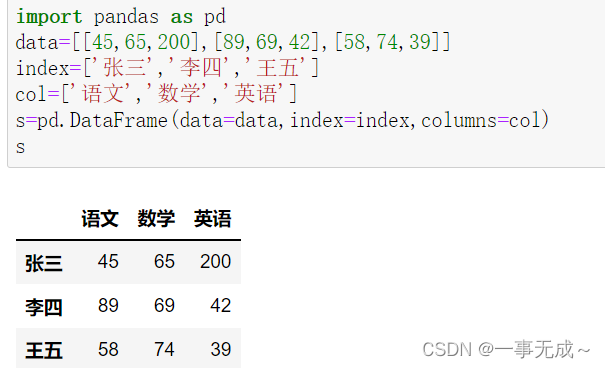
import pandas as pd
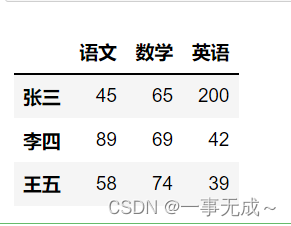
data=[[45,65,200],[89,69,42],[58,74,39]]
index=[‘张三’,’李四’,’王五’]
col=[‘语文’,’数学’,’英语’]
s=pd.DataFrame(data=data,index=index,columns=col)
s
数据提取按行
(‘—————————————————————-数据提取 根据标签’)
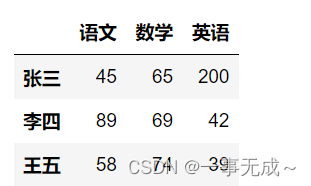
s.loc[‘张三’]
(‘—————————————————————-数据提取 根据序列’)
s.iloc[0]
(‘—————————————————————-数据提取 提取多行’)
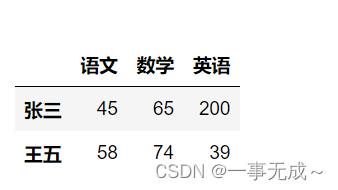
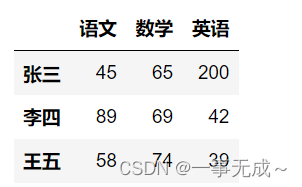
s.loc[[‘张三’,’王五’]]
或
s.iloc[[0,2]]
(‘—————————————————————-切片’)
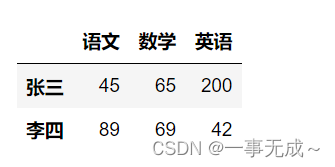
s.loc[‘张三’:’王五’]
s.iloc[0:2]含头不含尾
s.iloc[::]#start:stop:step

数据提取按列
print(‘———————————————-直接使用列名’)
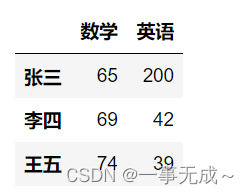
s[[‘数学’,’英语’]]
print(‘———————————————使用loc iloc’) :逗号左边表示行 逗号右边表示列
s.loc[:,[‘数学’,’英语’]]
s.iloc[:,[1,2]]
print(‘—————-提取连续数据’)
s.loc[:,’语文’:]
或
s.iloc[:,0:]
或
s.iloc[:,[0,1,2]]
提取区域数据
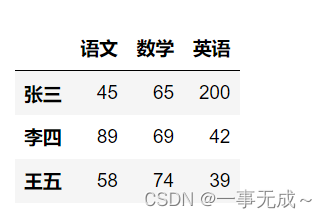
s.loc[‘张三’,’语文’]
s.iloc[0,0]
45
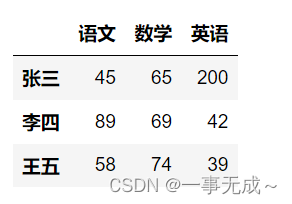
s.loc[[‘张三’,’王五’],[‘语文’,’数学’]]
s.iloc[[0,2],[0,1]]

s.iloc[0:2,0:2] #,左边行切片,右边列切片
s.loc[‘张三’:’王五’,’语文’:’英语’]
筛选指定条件数据
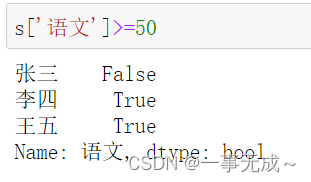
单个条件
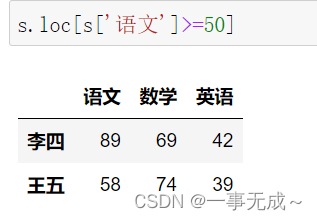
s[‘语文’]>=50
s.loc[s[‘语文’]>=50]
多个条件
s.loc[(s[‘语文’]>=50) & (s[‘数学’]>=70)]

数据的增加修改和删除
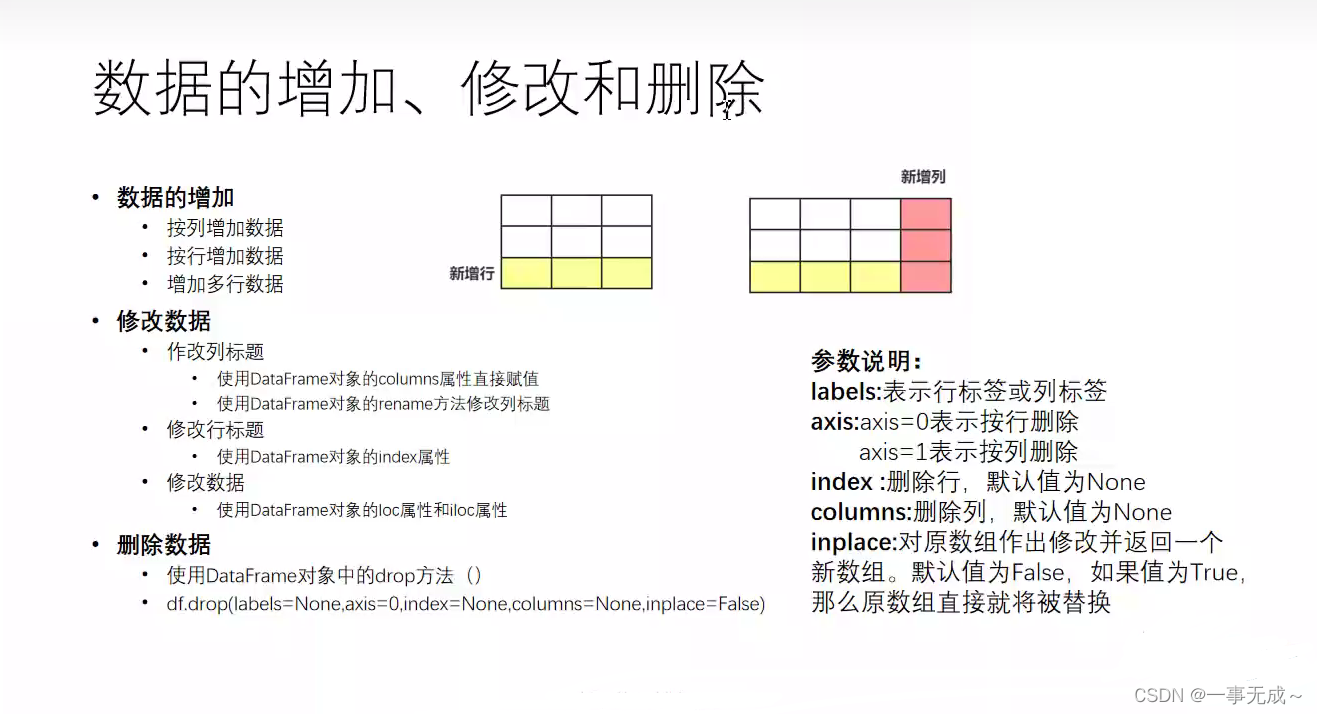
数据增加
按行
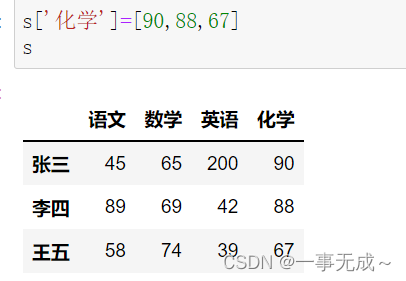
print(‘————————————–直接赋值’)
s[‘化学’]=[90,88,67]
s
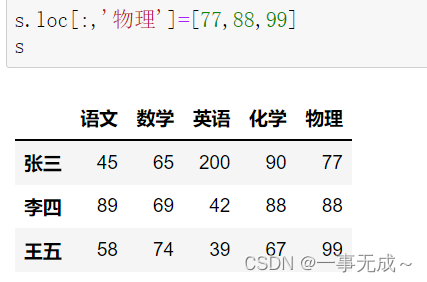
print(‘————————————–采用loc属性在最后一列增加’)
s.loc[:,’物理’]=[77,88,99]
s
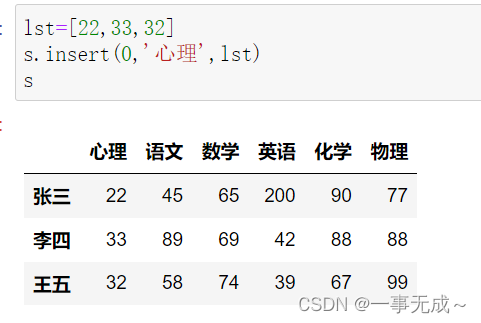
print(‘————————————–在指定索引位置添加一列’)
lst=[22,33,32]
s.insert(0,’心理’,lst)
s
按列
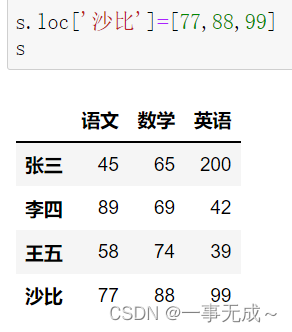
print(‘————————————–采用loc属性’)
s.loc[‘沙比’]=[77,88,99]
print(‘————————————–添加多行’)
d=pd.DataFrame( data={‘语文’:[78,79],’数学’:[74,71],’英语’:[45,46]}, index=[‘小虎’,’小红’] ) s=pd.concat([s,d])
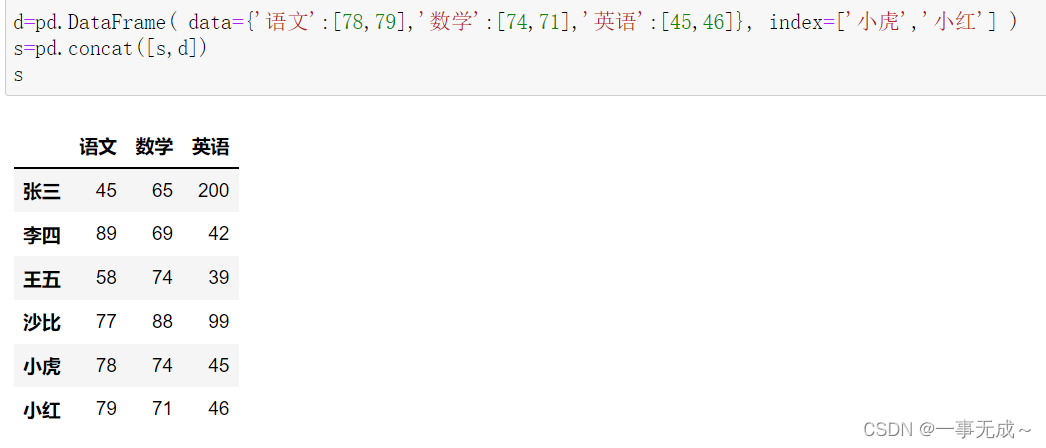
数据修改(内容和索引的修改)
print(‘———————————————————修改列索引’)
print(‘—————1 直接使用 columns属性’)
s.columns=[‘chinese’,’math’,’english’]

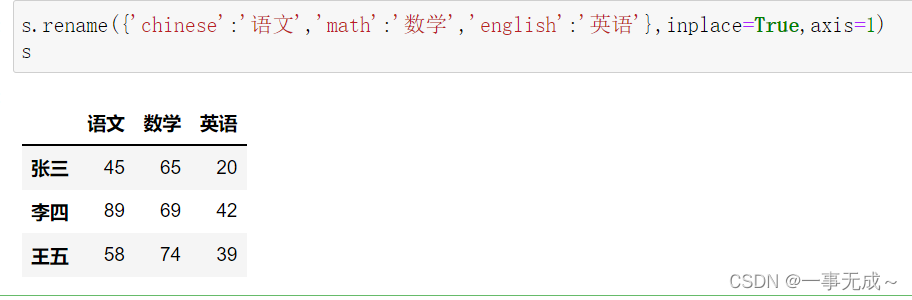
print(‘—————2 使用 rename方法’)
s.rename({‘chinese’:’语文’,’math’:’数学’,’english’:’英语’},inplace=True,axis=1)
print(‘———————————————————修改行索引’)
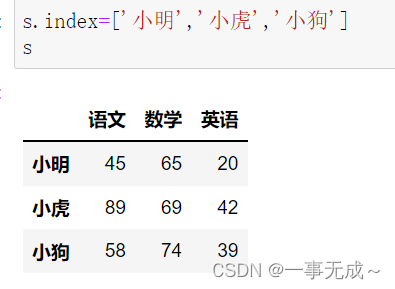
print(‘—————1 直接使用 index属性’)
s.index=[‘小明’,’小虎’,’小狗’]
print(‘—————2 使用 rename方法’)
s.rename({‘小明’:’张三’,’小虎’:’李四’,’小狗’:’王五’},inplace=True,axis=0)

数据内容的修改
print(‘———————————————————-修改数据内容’)
print(‘————————-修改一整行’)
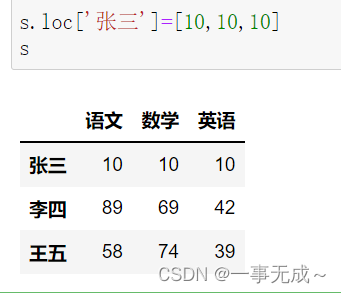
s.loc[‘张三’]=[10,10,10] / s.iloc[0,:]=[10,10,10]
print(‘————————-修改一整列’)
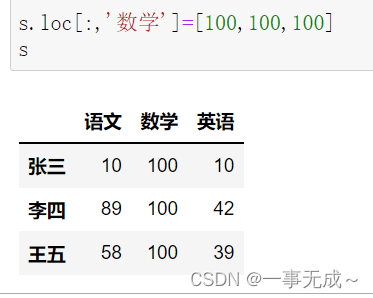
s[‘数学’]=[100,100,100] s.loc[:,’数学’]=[100,100,100]
print(‘————————-修改某一处’)
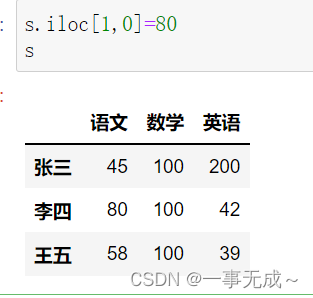
s.loc[‘李四’,’语文’]=80或s.iloc[1,0]=80
删除数据drop()
print(‘——————————————————————删除列数据’)
s.drop([‘语文’],axis=1,inplace=True)
s.drop(columns=’英语’,inplace=True)
s.drop(labels=’数学’,axis=1,inplace=True)



print(‘————————————————————删除行数据’)
s.drop([‘张三’],axis=0,inplace=True)
s.drop(index=’李四’,inplace=True)
s.drop(labels=’王五’,axis=0,inplace=True)
条件删除print(‘————————————————————条件删除’)
s.drop(s[s[‘语文’]
Original: https://blog.csdn.net/weixin_54824895/article/details/126089167
Author: 一事无成~
Title: Pandas详细总结(20000字 完结)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678789/
转载文章受原作者版权保护。转载请注明原作者出处!