

最近分析了一个儿童视力数据,记录一下。有需要数据的小伙伴可以去下载。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
import os
import seaborn as sns
import scipy.stats as ss
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
res_dir = "E:\同事\眼科\\use\整理\\res_dir_yanke"
df = pd.read_excel(os.path.join(res_dir, "noNullSex_8783.xlsx"))
df.shape
df.keys()
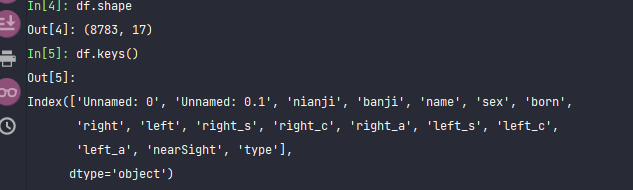

一共8783个数据。其中变量分别为:
年级、班级、姓名、性别、出生日期、右眼视力,左眼视力、右眼球镜s、右眼球镜c、右眼球镜a、左眼球镜s、左眼球镜c、左眼球镜a、是否视力不良、学段(分为幼儿园、小学、初中)
首先替换掉姓名部分。为了保护隐私起见,替换掉中间的部分。
name2 = [ re.sub(r'(\w)(\w)', r'\1*', x) for x in df['name'] ]
name2
df['name'] = name2
df['name']
df.info()

基本信息都是全的,左右眼数据中,有一些视力是缺失的,右眼有8777个有效数据,左眼有8779个有效的,因为两眼是主要的数据,所以基本视力这个必须有。删掉缺失的。
df = df.dropna(subset = ['left', 'right'])
df.shape
df[['right', 'left']].describe()
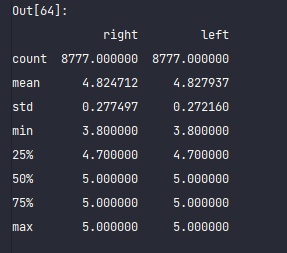
这是全部的基本信息。
首先可以分组看一看。均值。
df['type'].value_counts()
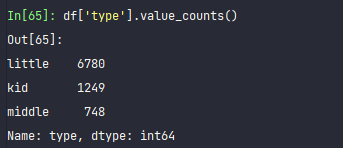
小学人数是6780, 幼儿园是1249, 初中是748.
各组的均值是多少。
df.groupby('type')['right', 'left'].mean()
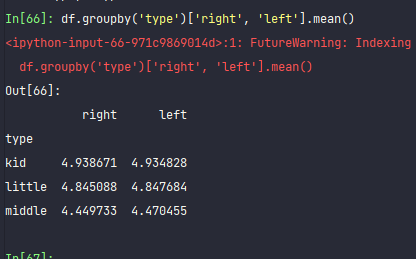
可以看出来,幼儿园小朋友视力是最棒的,到了初中,基本上,视力都下降到了4.5左右了。都是近视了。
当然,也可以看看,初中的数据的分布。
df[df['type'] == "middle"]['right'].describe()
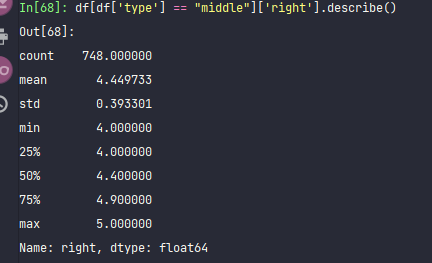
单纯以右眼来看,初中生,中位数是4.4。有四分之一的同学,视力已经在4.0以下了。
就视力来说,有判断标准如下:
1.视力不良, 就是左右眼有任一个眼睛视力在5.0以下,就算视力不良。
2.近视,左右眼视力在5.0以下,并且单眼的球镜a数据小于 -0.5。就算近视,如果是大于正的某个数,就是远视了。这里仅以近视为例。
首先生成一个视力不良的变量,判断任一眼睛视力在5.0以下的。
df['sight_impaired'] = ( df['right'] < 5.0 ) | (df['left'] < 5.0 )
df['sight_impaired'].value_counts()
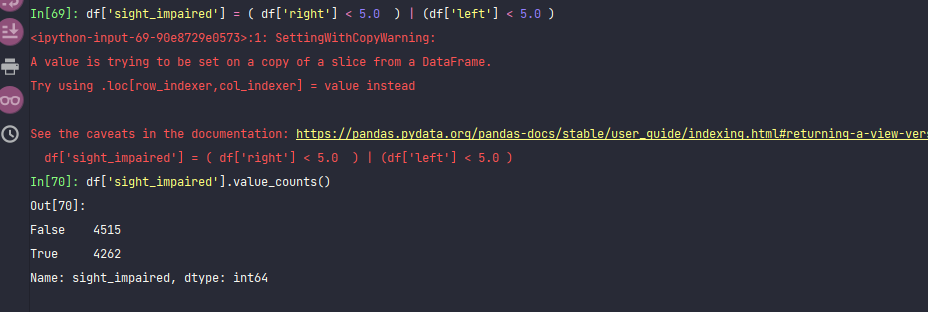
可以看出,接近一半的是视力不良。
但是这里面,幼儿园小朋友也有很多视力不良的。不信可以分组看看。
df.groupby('type')['sight_impaired'].value_counts(normalize=True).unstack()

df['nianji'].value_counts()
df.groupby('nianji')['sight_impaired'].value_counts(normalize=True).unstack()
df['nianji'].unique()
nianji_order = ['托班','小班', '中班', '大班', '一年级', '二年级', '三年级', '四年级', '五年级', '初一', '初三', '初二', '初四']
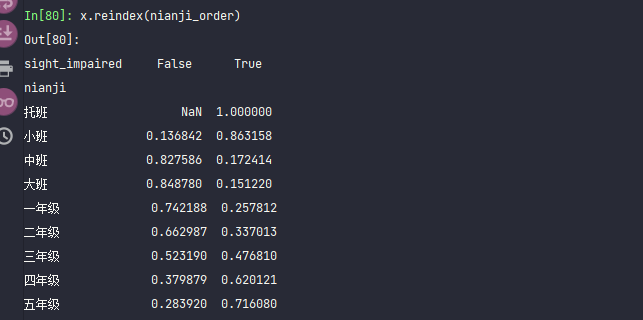
x = df.groupby('nianji')['sight_impaired'].value_counts(normalize=True).unstack()
x
x.reindex(nianji_order)[True]
x.reindex(nianji_order)[True].plot()
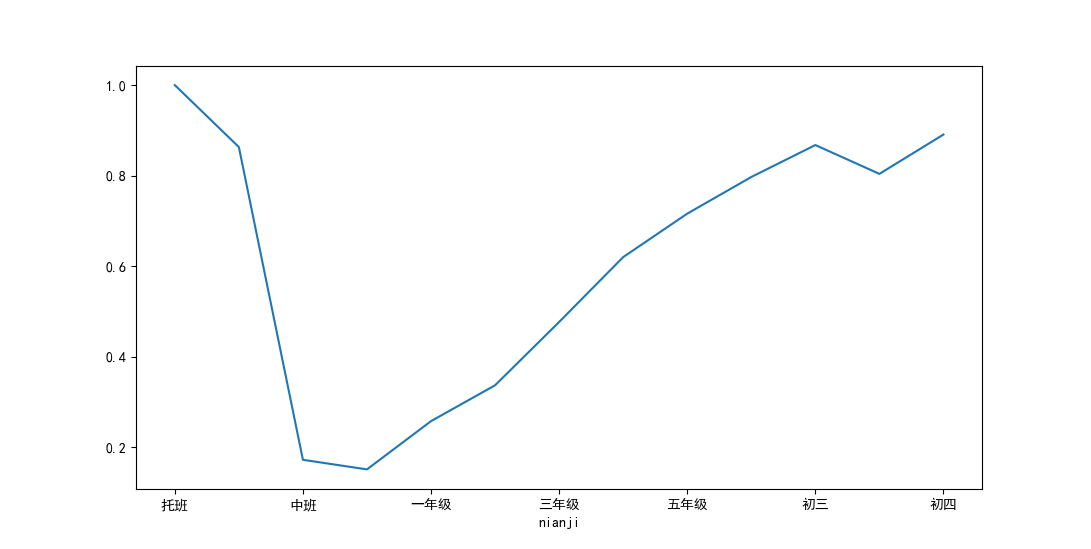
发现,幼儿园小朋友视力不良的比例高,其实这是因为幼儿园小朋友大部分都是远视,等到长大了,视力就回复正常了。比如一年级小朋友,基本上都是视力5.0, 没有问题,但是随着年级越高,视力不良的比例也就越高,初四,就接近100%了。差不多都近视了。幼儿园和初中虽然都搞,但是是两种完全不同的高。
通过近视比例可以看出来。
这就用到前面近视的判定标准了。
左右眼任一眼睛视力在5.0以下, 球镜s 数值小于-0.5。需要生成一个变量,满足这些条件,则判定为True,否则为False
Original: https://blog.csdn.net/weixin_40340586/article/details/122955502
Author: JECK_ケーキ
Title: 记录一次数据分析的过程。儿童视力数据(1)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678647/
转载文章受原作者版权保护。转载请注明原作者出处!