

1.首先构造如下的数据
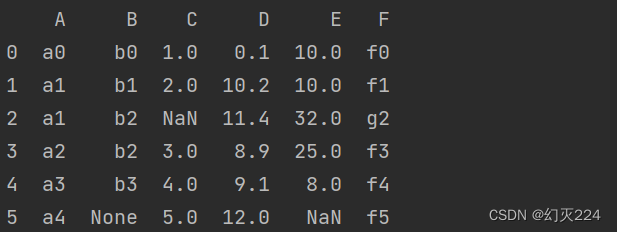

构造的数据框中有空值(None,字符类型;NaN,数据类型)和异常值的存在
2.空值检查
df=pd.DataFrame([['a0','b0',1,0.1,10,'f0'],['a1','b1',2,10.2,10,'f1'],
['a1','b2',None,11.4,32,'g2'],['a2','b2',3,8.9,25,'f3']
,['a3','b3',4,9.1,8,'f4'],['a4',None,5,12,None,'f5']],columns=['A','B','C','D','E','F'])
print(df.isnull())
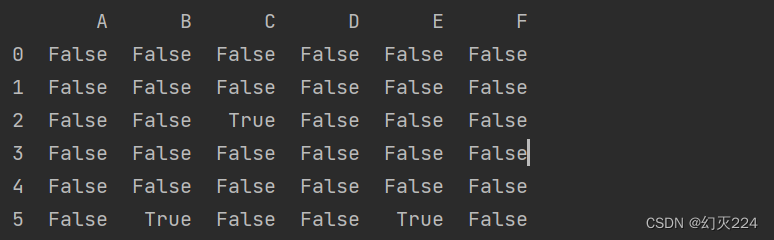
标记为Ture代表该处存在空值。
3.去除空值行
df.dropna()
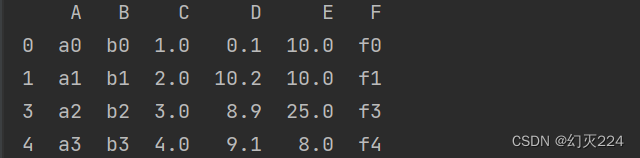
所有包含空值的行去掉。
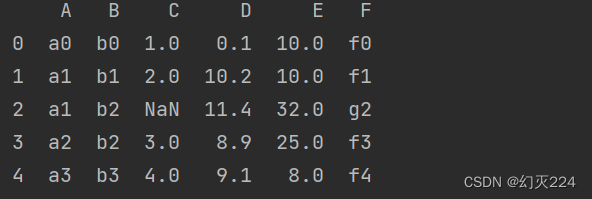
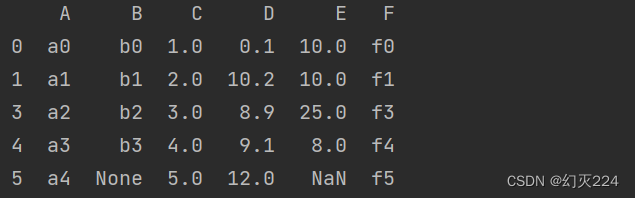
如果只想对某一属性的空值进行删除,可以使用(df.dropna(subset=[‘要删除的属性’])。比如我们只想删除属性B为空值的行,(df.dropna(subset=[‘B’]),结果如下
4.重复值的识别
检查A属性是否有重复值,df.duplicated(['A'])
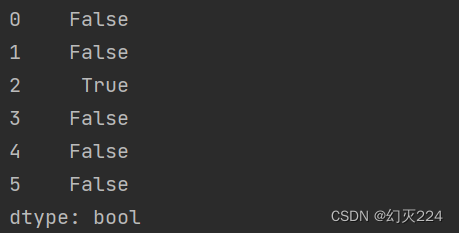
有重复的行会标记为True,显示第2行有重复值,符合实际情况。
5.去除重复值
df.drop_duplicates(['A']),去除A属性重复的行。结果如下

def drop_duplicates(
self,
subset: Hashable | Sequence[Hashable] | None = None,
keep: Literal["first"] | Literal["last"] | Literal[False] = "first",
inplace: bool = False,
ignore_index: bool = False,
) -> DataFrame | None:
以上为drop_duplicates的源码,keep表示你想保留第几个重复值,first表示保留第一个,last表示保留最后一个,false表示去除所有的重复值(不会留下任何一行重复的数据)。
6.缺失值的补充
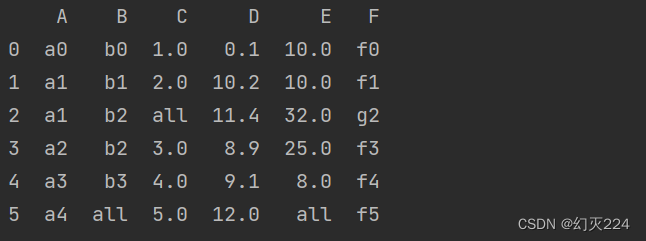
df.fillna('all'),所有缺失的位置,用'all'来填充
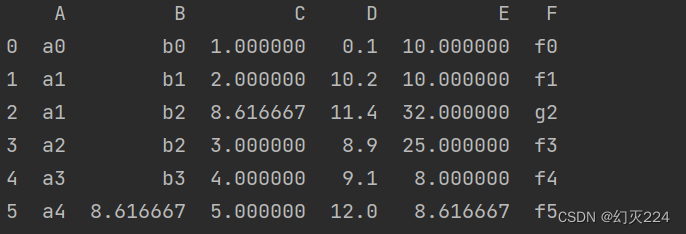
fillna函数填充时,也可以使用数据的一些均值之类的。比如使用D属性的均值来填充,
df.fillna(df['D'].mean())
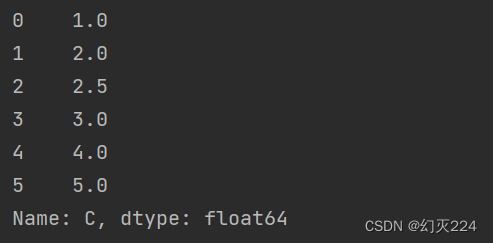
空值的处理也可以使用差值的方法,以 C属性为例,df[‘C’].interpolate()
6.检查某一属性是否符合某一规律
以F属性为例,大多数数据以f开头,需要去除非f开头的数据。
df[[True if i.startswith('f') else False for i in list(df['F'].values)]]
Original: https://blog.csdn.net/weixin_56676368/article/details/126339803
Author: 幻灭224
Title: 数据分析-异常值与空值的处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678379/
转载文章受原作者版权保护。转载请注明原作者出处!