

当数据中的dataframe(df)是一个二重索引且某一层索引的第二层索引值并不是全部索引值时,我们应该如何在该层索引插入第二层索引没有的值呢?本文记录自己的学习遇到的情况~
如以下的df
import numpy as np
import pandas as pd
import random
tuples=list(zip(['A','B'],['a','b']))
data=np.array([random.randint(1,10) for i in range(4)]).reshape(2,2)
df=pd.DataFrame(data,columns=['col1','col2'],index=pd.MultiIndex.from_tuples(tuples, names=['row1', 'row2']))
df


上述代码块中pd.MultiIndex.from_tuples具体可看官方文档。pandas.MultiIndex
现在我们要往row2里面插入两条索引为(‘A’,’b’)和(‘B’,’a’)需要如何操作呢,本文提供两种做法,当然如果还有别的做法欢迎留言交流学习!
这里建议直接使用第二种,简单粗暴。
第一种:
这种方法很复杂,我们需要在原来的df上遍历到需要插入的位置插入这个索引,当然你这种做法需要随时做好面对各种报错各种问题的出现。其步骤如下:
- for循环收集到子索引的所有值
- 遍历外层索引里面的值,一一比对,如果不存在该索引则插入进去。
- 处理边界问题、版本本身问题?(留个坑后面有说到)的一些注意事项
代码如下:
查到文章中说pandas无法向列表里面的insert函数一样随意插入位置,只有append函数添加在df最后一行
只能对df在插入的地方分成两个df1,df2,然后再使用concat函数合并三个df(分别为df1,df_add(要插入的那一行数据),df2)
def insert(df, df_add, name, i):
"""
创建一个函数用来向df中插入选定的位置
:param df: 原始df,要插入数据的那个df,对于下面函数来讲,df1由df赋值,一开始就对df1本身拆分
:param df_add: 要插入的数据行,以df形式传入
:param name: 指定外层索引的名字,即要插入到哪个外层索引里面
对于下面的df.loc[[name]],本身name就只是一个参数,为什么会需要用[]做成一个长度为1的列表呢,接着挖个坑后面说到(这个问题就是步骤3)
:param i: 插入哪一行
:return: 返回插入后的df
"""
# 指定第i行插入一行数据
df1 = df.loc[[name]].iloc[:i, :]
df2 = df.loc[[name]].iloc[i:, :]
df = pd.concat([df1, df_add, df2])
return df
def expend_all_index(df):
index1:外索引,即上述中的[A,B],为了保证不重复取到通过一个索引,需要unique一下
index2:内索引,即上述的[a,b]
index1=np.unique([value[0] for value in df.index])
index2=np.unique([value[1] for value in df.index])
创建一个与df一致的索引跟列
df_total = pd.DataFrame(columns=df.columns,
index=pd.MultiIndex.from_product(
[index1, index2],
names=list(df.index.names)))
遍历第一层索引
for id1 in index1:
取一层索引的下的index保存在pos1中,如上述中A索引下的[a]
pos1=list(df.loc[id1].index)
初始化一个与df一致的df1,保证insert函数中对其重复插入(此句看不懂可以再看看insert函数的说明)
df1 = df
i为pos1的索引,j为index2的索引
i=0
j=0
挨个比较pos1跟index2的值,如果一致,则往下移,如果不一致则进入if语句
while i
调用上述函数,运行结果如下:

这样就实现了df多重索引添加多行的操作啦~
现在开始填上面的坑,如果使用上述函数出现如下类似的keyError报错

大概率是因为使用df.loc的时候,有些是只显示df当前索引下的子索引,有些是显示当前索引+子索引,当只显示子索引的时候,你再loc[‘A’]之后,他就显示KeyError,所以要想显示当前索引+子索引,我们需要采用df.loc[[name]],其中name为外层索引的值,即使该值只有一个,所以要想显示当前索引+子索引的话,需要对loc传入一个列表。至于为什么会出现这种情况,一开始我以为是pandas版本问题,然后在pycharm安装了不同版本测试,然后结果似乎没有变化。具体看下例子:
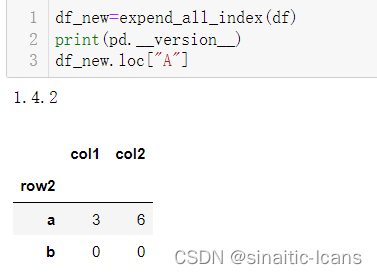
但我一开始在pycharm实现该函数的时候并没有发现问题,df.loc[‘A’]的时候显示的是外层索引+内层索引,如下所示
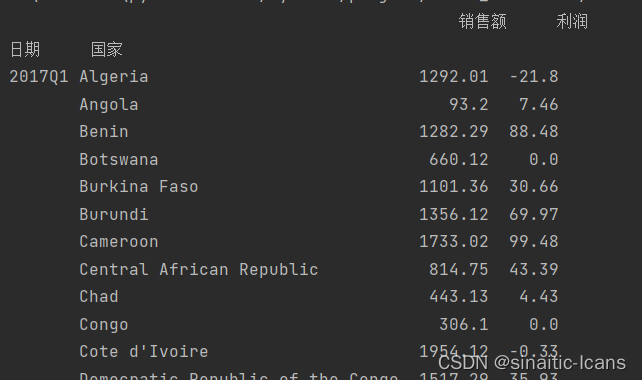
但当我把函数放在jupyter运行的时候,他只显示子索引,由于我jupyter跟pycharm的pandas版本不一样,所以我认为是版本的问题,但上述结果好像并不是这样。所以上述函数,即使只有一个传入的name只有一个值,要想显示外层索引+内层索引最好以列表形式传入。
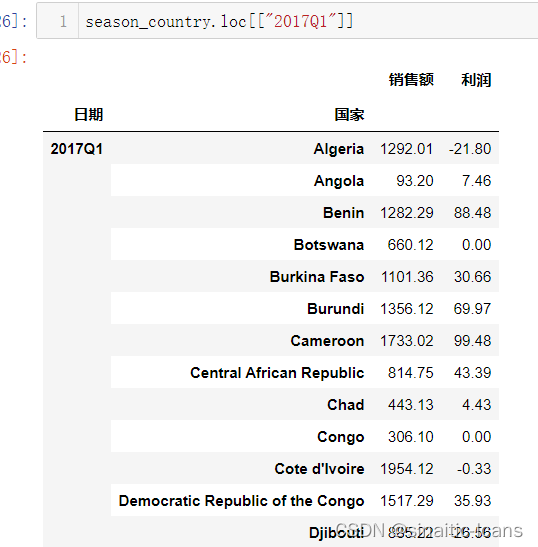
第二种:
这种方法很简单,直接创建新的df,然后使用pd.MultiIndex.from_product创建一个外层索引*内层索引的index赋值给新的index,然后再用原来已有的值填充新的df,对于剩下的值直接fillna一下即可。
- 列表生成式得到内外层索引的值
- 创建一个新的df
- for循环挨个赋值
- fillna填充nan值
代码如下:
tuples=list(zip(['A','B'],['a','b']))
data=np.array([random.randint(1,10) for i in range(4)]).reshape(2,2)
df=pd.DataFrame(data,columns=['col1','col2'],index=pd.MultiIndex.from_tuples(tuples, names=['row1', 'row2']))
df

接着创建一个新的df_new:
index1=np.unique([value[0] for value in df.index])
index2=np.unique([value[1] for value in df.index])
df_new=pd.DataFrame(columns=df.columns,index=pd.MultiIndex.from_product([index1,index2],names=list(df.index.names)))
for value in df.index:
df_new.loc[value]=df.loc[value]
df_new.fillna(0,inplace=True)
df_new
最后结果如下:

如果对你有帮助的话就点个赞吧~
Original: https://blog.csdn.net/weixin_59699198/article/details/127112461
Author: sinaitic-Icans
Title: pandas多重索引补全子索引缺失的方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678199/
转载文章受原作者版权保护。转载请注明原作者出处!