

各位同学好,今天我向大家介绍一下pandas库中的索引操作–增、删。
1. 增加
1.1 对series操作
方法一:在原有数据上增加,改变原有数据。
Series名[新标签名] = 新标签名对应的值
创建Series类型数据ps1,它的标签为’a’到’e’,对应的值为0到4,原标签不存在’g’,使用ps1[‘g’]=9,在原数组的最后追加一个标签’g’,以及它对应的值9。
import pandas as pd
创建一个Series类型数据,标签为'a'到'e',对应的值为0到4
ps1 = pd.Series(range(5),index=["a","b","c","d","e"])
新标签'g',对应的值为9
ps1["g"] = 9
方法二:增加数据并赋值给新变量,不影响原来的数据
新变量 = Series名.append(Series类型数据)
创建一个Series类型数据ps1,使用字典创建一个被追加的Series数据,append()函数不会对原数据修改,需要用一个新变量来接收这个追加后的结果。
import pandas as pd
创建一个Series类型数据
ps1 = pd.Series(range(5),index=["a","b","c","d","e"])
利用字典创建一个需要添加的Series类型数据
s1 = pd.Series({'f':999})
将s1追加到ps1后面
ps2 = ps1.append(s1)
1.2 对DataFrame操作
(1)对列操作
在最后一列后面追加一列:
变量名.[新标签] = 新标签对应的值
该方法会直接对原数据修改。如下,使用numpy创建一个1到9的一维数组,使用shape(行数,列数)函数变成3行3列的二维数组,再转换成DataFrame类型。pd1[4]=9,追加一列的新列标签名是4,这一列的值都是9。注意的是, 此处的列标签名4是int类型,而pd1中的’A’、’B’等都是str类型。
import pandas as pd
import numpy as np
在最后一列后面追加一列
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
追加一列的列标签名是4,这一列的值都是9
pd1[4] = 9
追加一列的列标签名是4,这一列的值与列表对应
pd1[4] = [11,12,13]


在指定位置插入一列:
变量名.insert(下标索引位置前, 索引名, 列数据)
该方法会直接对原数据修改。首先下标索引位置是指位置索引标签,即0、1、2等。 插入的索引名和值是插在自己指定的下标位置索引前面一列。如下,我指定位置索引是0,即我想在第1列前面插入一列。我定义的插入的一列的列索引名是’E’。
import pandas as pd
import numpy as np
在指定位置插入一列
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
插入一列的列位置索引号是0,在0前插入标签E
pd1.insert(0,"E",[100,100,100])
(2)对行操作
在最后一行的后面追加一行,方法一:
变量名.loc[标签名] = 行数据
利用 标签索引loc操作,涉及高级索引,后续章节会详述。 该方法会直接对原数据修改。loc指定行,在原数据最后一行后面,新增行标签’k’,及其对应的行数据。
import pandas as pd
在最后一行追加一行
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
pd1.loc["k"] = [77,88,99]

在最后一行的后面追加一行,方法二:
新变量 = 变量名.append(字典, ignore_index = True)
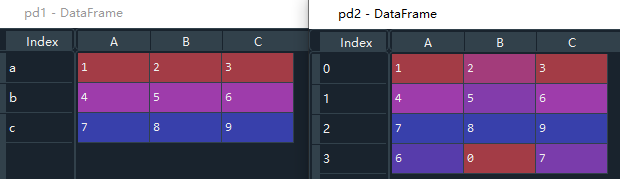
该方法不会直接对原数据修改,需使用新变量接收。如下,我有一行数据想追加到DataFrame后面,但是直接追加的话,字典的key和dataframe的列标签名不对应,无法直接追加,此时使参数 ignore_index = True,使字典的key和dataframe的列标签自动匹配进行追加。
import pandas as pd
import numpy as np
在最后一行追加一行
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
创建一个字典,字典的key和pd1的列标签不对应,需要调整位置
row = {"B":0,"A":6,"C":7}
使字典的key和列标签自动匹配进行追加
pd2 = pd1.append(row,ignore_index=True)
2. 删除
2.1 对Series操作
(1)在原始数据上删除:
del Series名[索引名]
删除索引名所对应的一行数据
import pandas as pd
删除一行数据
ps1 = pd.Series(range(5),index=["a","b","c","d","e"])
del ps1['c'] #删除c所在的一行
(2)不影响原始数据的删除:
新变量 = series名.drop(索引名1, 索引名2)
需要一个新变量来接收结果。可以删除多行,自行输入需要删除的行索引名。
import pandas as pd
ps1 = pd.Series(range(5),index=["a","b","c","d","e"]) #创建一个series类型
删除'a'所在的一行
ps2 = ps1.drop('a')

2.2 对DataFrame操作
(1)删除一行:
新变量 = 变量名.drop(行索引名)
(2)删除多行
新变量 = 变量名.drop([行索引名1, 行索引名2])
import pandas as pd
import numpy as np
pd1 = pd.DataFrame(np.arange(1,26).reshape(5,5),index=["a","b","c","d","e"],columns=["A","B","C","D","E"])
删除一行
pd_d1 = pd1.drop('a')
删除多行
pd_d2 = pd1.drop(['a','c'])

(3)删除一列:
新变量 = 变量名.drop(索引名, axis = 1)
新变量 = 变量名.drop(索引名, axis = ‘columns’)
(4)删除多列:
新变量 = 变量名.drop([索引名1,索引名2], axis = 1)
新变量 = 变量 名.drop( [索引名1,索引名2] , axis = ‘columns’)
该方法需要有变量接收返回值。对列操作需要指定轴axis,axis=1代表列方向,axis=0代表行方向。
import pandas as pd
import numpy as np
pd1 = pd.DataFrame(np.arange(1,16).reshape(3,5),index=["a","b","c"],columns=["A","B","C","D","E"])
删除一行
pd2 = pd1.drop("A",axis=1)
删除多行
pd3 = pd1.drop(["A","C"],axis='columns')

(5)inplace属性:
变量名.drop(行索引名, inplace=True)
可直接在原数据上修改,不需要新变量来接收返回结果。
import pandas as pd
import numpy as np
pd1 = pd.DataFrame(np.arange(1,13).reshape(4,3),index=["a","b","c","d"],columns=["A","B","C"])
删除一行
pd1.drop("a",inplace=True)

Original: https://blog.csdn.net/dgvv4/article/details/121308419
Author: 立Sir
Title: 【Pandas库】(5) 索引操作–增、删
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678113/
转载文章受原作者版权保护。转载请注明原作者出处!