

Pandas索引操作及高级索引
索引对象
Pandas 中的索引都是 Index 对象,又称索引对象,该对象是 不可以进行修改的,以保证数据的安全。例如,创建一个 Series 类对象,为其制定索引,然后再对索引重新赋值后会提示”索引不支持可变操作”的错误信息,示例代码如下:
ser_obj = pd.Series(range(5),index=['a','b','c','d','e'])
ser_index = ser_obj.index
ser_index
ser_index['2']='cc'
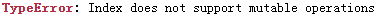

Index 类对象的不可变特性是非常重要的,正因如此,多个数据结构之间才能够安全的共享 Index 对象。例如,创建两个共同使用同一个 Index 对象的 Series 类对象,具体代码如下:
ser_obj1 = pd.Series(range(3),index=['a','b','c'])
ser_obj2 = pd.Series(['a','b','c'],index=ser_obj1.index)
ser_obj2.index is sr_obj1.index
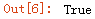
除了泛指的 Index 对象以外,Pandas 还提供了很多 Index 的子类,常见的又如下几种:
( 1 ) Int64Index:针对整数的特 Index 对象。
( 2 ) MultiIndex:层次化索引,表示单个轴上的多层索引。
( 3 ) DatetimeIndex:存储纳秒寄时间戳
重置索引
Pandas 中提供了一个重要的方法是 reindex()
reindex() 方法的语法格式如下:
DateFrame.reindex(lables=None, index=None, columns=None,
axis=None, method=None, copy=True, level=None,
fill_value=nan, limit=None, tolerance=None)
上述方法的部分参数含义如下:
( 1 ) index:用作索引的新序列。
( 2 ) method:插值填充方式。
( 3 ) fill_value:引入缺失值时使用的替代值。
( 4 ) limit:前向或者后向填充时的最大填充量。
新索引中含有原索引的数据,而原索引数据按照新索引排序,如果新索引中没有原索引数据,那么程序不仅不会报错,而且会添加新的索引,并将值填充为 NaN 或者使用 fil_value() 填充数据
缺失值默认使用NaN填充
ser_obj1 = pd.Series([1,2,3,4,5],index=['c','d','e','f','g'],dtype='int64')
ser_obj2 = ser_obj1.reindex(['a','b','c','d','e','f'])

如果不想使用NaN填充,可以使用fill_value参数来指定缺失值
ser_obj2 = ser_obj1.reindex(['a','b','c','d','e','f'],fill_value=6)

如果期望使用相邻元素值(前边或者后边元素的值)进行填充,则可以使用
method参数参数 说明 ffill pad
向前填充值
bfill backfill
后向填充值
nearest
从最近的索引值填充
例:
ser_obj1 = pd.Series([1,3,5,7],index=[0,2,4,6])
ser_obj2 = ser_obj1.reindex(range(6),method='ffill')
索引操作
Series的索引操作
和 Numpy 的 ndarray 对象的操作类似
- 通过 整数索引 索引名 获取数据
ser_obj = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
ser_obj[2]
ser_obj['a']
- 索引切片
可以使用整数索引进行切片,包含起始位置但不包括结束位置。 也可以使用索引名进行切片,但包括结束位置。
ser_obj = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
ser_obj[0:3]

ser_obj['a':'c']

- 不连续索引 如果是获取的不连续的数据,可以使用不连续索引
ser_obj = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
ser_obj[[0,2,4]]
ser_obj[['a','c','e']]
- 布尔型索引
ser_obj = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
ser_bool = ser_obj>2
ser_obj[ser_bool]
DataFrame 的索引操作
DataFrame 结构既包括行索引,也包括列索引。其中,行索引是通过 index 属性进行获取的,列索引是通过 columns 属性获取的
- 获取列
DataFrame 中每列的数据都是一个Series对象,我们可以使用列索引进行获取。
arr = np.arange(12).reshape(3,4)
df_obj= pd.DataFrame(arr, columns=['a','b','c','d'])
df_obj

df_obj['b']

如果想要从 DataFrame 中获取多个不连续的 Series 对象,则同样可以使用不连续索引进行实现
df_obj[['b','d']]
DataFrame 支持切片获取Series对象
df_obj[:2]
DataFrame 可以使用切片后再通过索引获取其中的数据
df_obj[:3][['b','d']]
loc方法 和iloc方法
loc:基于标签索引(索引名称,如a、b等),用于按标签选取数据。当执行切片操作时,既包含起始索引,也包含结束索引。
iloc:基于位置索引(整数索引,从0到 length-1),用于按位置选取数据。 当执行切片操作时,只包含起始位置,不包含结束位置。
假设,现在有一个 DataFrame 对象,具体代码如下:
arr = np.arange(12).reshape(3,4)
df_obj= pd.DataFrame(arr, columns=['a','b','c','d'])
df_obj

接下来,我们演示如何使用它们来获取列数据
注意:[] 中的第一个参数是行索引,第二个是列索引
- 获取单列数据
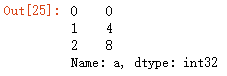
df_obj[:,'a']
df_obj.iloc[:,0]
上面两个结果相同:
- 获取多列数据
df_obj[:,['a','c']]
df_obj[:,[0,2]]
上面两个结果相同:

- 使用花式索引访问数据
df_obj.loc[1:2,['b','c']]
df_obj.iloc[1:3,[1,2]]
它们两个的输出结果也是一样的,具体如下

Original: https://blog.csdn.net/qq2351227851/article/details/122033926
Author: 地铁洗涤感冒药
Title: Pandas索引操作及高级索引
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678071/
转载文章受原作者版权保护。转载请注明原作者出处!