

DataFrame介绍:
DataFrame是一个表格型的数据结构,它含有一组 有序 的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
导入包:

1.将字典转化为DataFrame
定义字典:
data = {"grammer":["Python","C","Java","GO",np.nan,"SQL","PHP","Python"],
"score":[1,2,3,4,5,6,7,10]}
将字典转化为DataFrame:
df = pd.DataFrame(data)
得到:

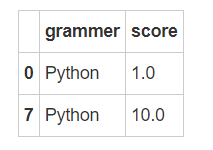
2.提取含有字符串”Python”行:
方法一:
df[df['grammer'] == 'Python']
方法二:
results = df['grammer'].str.contains("Python")
results.fillna(value=False,inplace = True)
df[results]
得到的结果:
3.输出列名:
print(df.columns)
得到的结果:
Out[28]: Index(['grammer', 'score'], dtype='object')
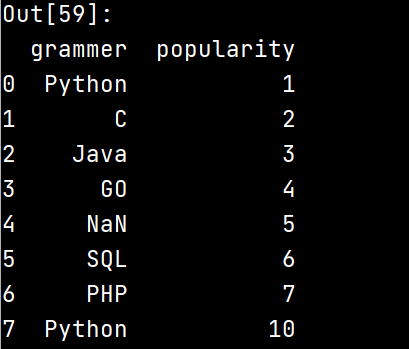
4.将第二列改成”popularity”:
df.rename(columns = {'score':'popularity'}, inplace = True)
输出df:
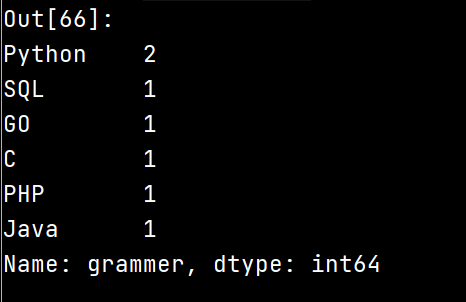
5.统计grammer每一列中编程语言出现的次数:
df['grammer'].value_counts()
结果:
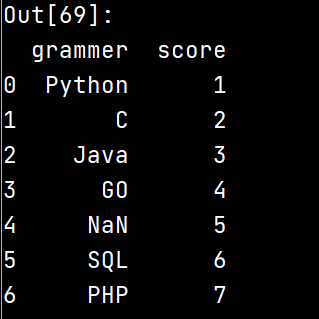
6.提取popularity中大于三的:
df[df['score']>3]
结果:
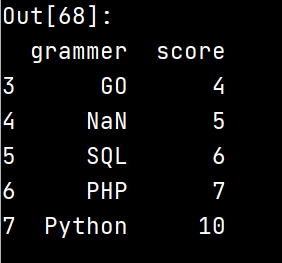
7.按照grammer列进行去除重复值:
df.drop_duplicates(['grammer'])
8.计算popularity列的平均值:
df['score'].mean()
9.将grammer列转化为list:
df['grammer'].tolist()
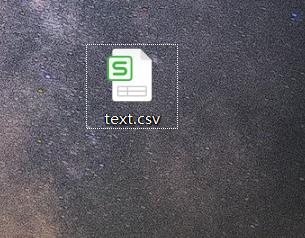
10.将DataFrame保存为csv
df.to_csv("text.csv")
结果得到了一个csv文件:
Original: https://blog.csdn.net/weixin_51756104/article/details/116356100
Author: 小皮麻花
Title: Task1 Pandas基础学习(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677983/
转载文章受原作者版权保护。转载请注明原作者出处!