

文章目录
- Pandas简介
- Pandas基本数据结构
* - Pandas库中的Series类型
– - Pandas库的DataFrame类型
– - 查看数据
* - 头尾数据
- 下标,列标,数据值
- pandas读取数据及数据操作
* - 读数据
- 行操作
– - 列操作
– - 删除某一行/列⭐
– - 通过标签选择数据⭐ —— loc
- 条件选择
* - 选取产地为美国的所有电影
- 选取产地为美国的所有电影,并且评分大于9分的电影
– - 选取产地为美国或中国大陆的所有电影,并且评分大于9的电影
- 缺失值和异常值处理
* - 缺失值处理方法
- 判断缺失值
– - 处理缺失值
– - 处理异常值
– - 数据保存
- 练习
* - Pandas基础知识
- 数据操作
Pandas简介
Python Data Analysis Library 或 pandas 是基于 numpy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas 提供了大量能使我们快速便捷地处理数据的函数和方法。
导入库:
import pandas as pd
import numpy as np
Pandas基本数据结构
Pandas 中有两种常用的基本结构:
- Series
一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构 list也很相近。Series能保存不同种数据类型,字符串、boolean值、数字等都能同时保存在Series中。
- DataFrame
二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Pandas库中的Series类型
用一维列表初始化一维数组Series
s1 = pd.Series([1,3,5,np.nan,6,8])
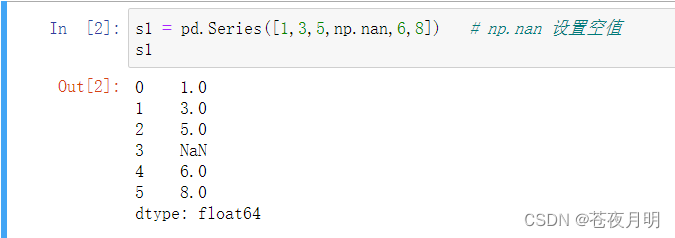

左边:0,1,2,3,4,5 代表索引。
右边:1.0,3.0,5.0,NaN(空值),6.0,8.0 代表值。
默认情况下,Series的下标都是数字(也可以使用额外参数指定),类型是统一的。
用字典初始化一维Series
dic = {'a':'啥么呀','b':'哎哟','c':'可以的',4:'还能这样啊'}
s2 = pd.Series(dic)

用额外参数指定下标
格式:参数,index
参数可以是一个:
s3 = pd.Series(1,index=list(range(4)))

参数也可以是多个:
s2 = pd.Series([1,3,5,np.nan,6,8],index=['a','b','c','d','e','f'])

用额外参数指定下标后,可以用额外参数索引,也可以用默认的数字索引
dic = {'a':'啥么呀','b':'哎哟','c':'可以的',4:'还能这样啊'}
s2 = pd.Series(dic)

参数索引直接写,b行就是b行;数字索引注意减1操作,第一行是0
Series 要求所有数据类型都相同,虽然看上去能存储很多不同类型,但最底下的dtype还是证明了只有一种类型
看dtype可以看出,Series存储的数据类型都相同!!!即便写的时候都不一样,但会给个相同类型
s4 = pd.Series([342,'dnf',True])

索引 —— 数据的行标签
s1 = pd.Series([1,3,5,np.nan,6,8])
dic = {'a':'啥么呀','b':'哎哟','c':'可以的',4:'还能这样啊'}
s2 = pd.Series(dic)
print(s1.index)
print(s2.index)

索引命名 —— 给索引一个名字
s1.index.name = '尝试'

用 对象
.index.name 方法
索引赋值
初始化时pd.Series()中可以写index=[ ]属性赋值;用字典初始化时,自动就改变索引了
s2 = pd.Series([1,3,5,np.nan,6,8],index=['a','b','c','d','e','f'])

初始化以后,再想给索引赋值,用 对象 .index 方法
s1.index = list('!@#$%&')
s1.index = ['哈哈','嘿嘿','嘻嘻','呵呵','耶耶','nice']

从上面可以看出:传给 数组.index 的新索引得是一个列表
这时再切片:

数字索引 和 自定义索引 这两种索引方式记清!!!
值
s1.values

.values 和 字典的 .values() 一样;切片和列表的切片一样。知识都是相通滴
Pandas库的DataFrame类型
构造 DataFrame 的方式之——向 DataFrame 中传入二维数组
先构造一组时间序列,作为第一维的下标,即index:
data = pd.date_range('20220528',periods=6)

要严格按照 XXXX(年)XX(月)XX(日)的格式写,否则会报错。不能写2022528,0不能省略!!!
然后创建一个 DataFrame 结构:
df = pd.DataFrame(np.random.randint(1,10,size = [6,4]))

默认情况下,行和列都是从0开始数列
用index参数设置行索引:
df = pd.DataFrame(np.random.randint(1,10,size = [6,4]),index = data)

用columns参数设置列索引:
list1 = list('ABCD')
df = pd.DataFrame(np.random.randint(1,10,size = [6,4]),index = data,columns = list1)

构造 DataFrame 的方式之——向 DataFrame 中传入字典
字典的每个 key 键代表一列,其 value 可以是各种能够转化为 Series 的对象
dic1 = {'A':1,'B':pd.Timestamp('20220528'),'C':pd.Series(1,index=list(range(4)),dtype='float'),'D':np.array([3]*4,dtype='int'),'E':pd.Categorical(['test','train','test','train']),'F':'abc'}
注意: range(4)设置了有4行,则下面无论是np.array还是pd.Categorical,都得是4个数据。否则就报错!
df2 = pd.DataFrame(dic1)

PS: pd.Categorical 是什么
pd.Categorical(['test','train','test','train'])

查看各个列具体的数据类型,用 dtypes
df2.dtypes

查看数据
头尾数据
head 和tail 方法可以分别查看最前面几行和最后面几行的数据(默认为5)
df = pd.DataFrame(np.random.randint(1,10,size = [6,4]),index = data,columns = list1)
df.head()


看前n行就 .head(n)

tail是后面几行

下标,列标,数据值
下标使用 index 属性查看:

列标使用 columns 属性查看:

数据值使用 values 查看:

; pandas读取数据及数据操作
读数据
格式: pd.read_文件后缀(路径)
excel文件就 read_excel() ;csv文件就 read_csv()
df = pd.read_excel(r'D:\数据分析\豆瓣电影数据.xlsx',index_col=0)
两个注意点:
- r 的作用:告诉程序 转义字符( \ ) 不转义了
- 如果不加 index_col=0,有的数据就会出现 Unnamed: 0 一列。不信试试

df1 = pd.read_csv(r'D:\pro1\实战案例\douban.csv')

行操作
看所有行名称

取指定行信息,用iloc

看前5行

也可以使用loc

也可以直接索引

; 添加一行
- 先构造一个字典用来创建一维Series
dic = {'名字':'人生如戏','投票人数':1263542,'类型':'搞笑','产地':'中国','上映时间':'2022-05-29 00:00:00','时长':1,'年代':2022,'评分':10.0,'首映地点':'bilibili'}
- 创建一维Series —— 用字典初始化
s = pd.Series(dic)

- 先看此时最后一行索引到几了,因为需要给新增数据加 index索引名
df.tail(1)

- 给新添加的一行命名
s.name = 38738

- 像列表一样添加
df = df.append(s)
一定要重新赋值给df,df = 这步至关重要
- 查看是否加上
df.tail()

删除一行
格式: 对象 .drop([行])
drop里写想删除行的列表

俺的人生入戏果然被删了
; 列操作
看所有列名称
df.columns

看具体列
df['名字']

看具体列的哪几行
df['名字'][2:5]

取多列
df[['名字','类型']]
注意:
[ ] 中是一个列表

取具体行都一样

; 增加一列
df['序号'] = range(1,len(df)+1)

最右边增加了序号列
删除一列
df = df.drop('序号',axis=1)
说明
- drop()里写删除列的名字的列表
- axis默认=0,表示行;令axis=1,表示删除列

序号这列被删掉了
; 删除某一行/列⭐
方法1
语法:
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
参数说明:
labels: 就是要删除的行列的名字,用列表给定axis:默认为0,指删除行;因此删除columns(列)时要指定axis=1;index:直接指定要删除的行columns:直接指定要删除的列inplace=False:默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;inplace=True:则会直接在原数据上进行删除操作,删除后无法返回。
方法2
语法:
del df['columns']
参数说明:
columns :是要删除的列名
通过标签选择数据⭐ —— loc
df.loc:根据行、列的标签值查询。- 格式 :df.loc [ [ index ] , [ column ] ]
PS : df.iloc : 根据行、列的数字位置查询(没有loc用的多)。
二行一列的数据
df.loc[[1],['名字']]

不加[ ],就没有行名列名,只是单纯的取了个数据
df.loc[1,'名字']

1,3,5,7,9行,名字产地列数据
df.loc[[1,3,5,7,9],['名字','产地']]

条件选择
选取产地为美国的所有电影
df['产地']=='美国'
这个操作返回的是布尔型而非数据。
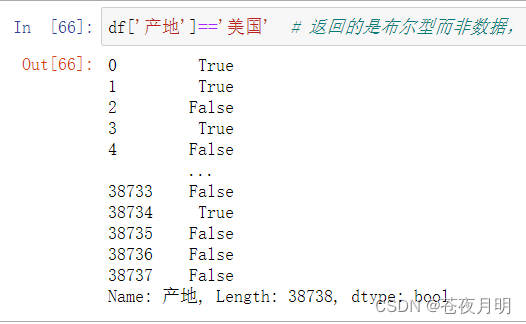
如果想得到数据,就需要外面再套一层df[ ],这样True位置的数据就留着,False位置的数据就扔掉
df[df['产地']=='美国']

后面还能加索引嘞
df[df['产地']=='美国'][7:10]

选取产地为美国的所有电影,并且评分大于9分的电影
df[(df['产地'] == '美国') & (df['评分'] > 9)]
注意:
- () 用来包住判断语句,表示一个整体。不能缺了
- 判断 “与” 时,要写 & , 不能写 and

简便写法
df[(df.产地 == '美国') & (df.评分 > 9)]
用 .代替 [" "]
用 .产地 代替 [” 产地 “]
数据选取时都可以用 .head()和 .tail()
df[(df.产地 == '美国') & (df.评分 > 9)].head()

选取产地为美国或中国大陆的所有电影,并且评分大于9的电影
df[(df.产地 == '美国') | (df.产地 == '中国大陆') & (df.评分 > 9)]
注意: ( ) 不能少啊!!!用来隔开各个判断式的。

缺失值和异常值处理
缺失值处理方法
- dropna :根据标签中的确实值进行过滤,删除缺失值
- fillna :对缺失值进行填充
- isnull :返回一个布尔值对象,判断哪些值是缺失值
- notnull :isnull的否定式
判断缺失值
对所有数据进行:是否是缺失值 的判断
df.isnull()

对一整列进行判断
df['名字'].isnull()
注意 :返回的是布尔值
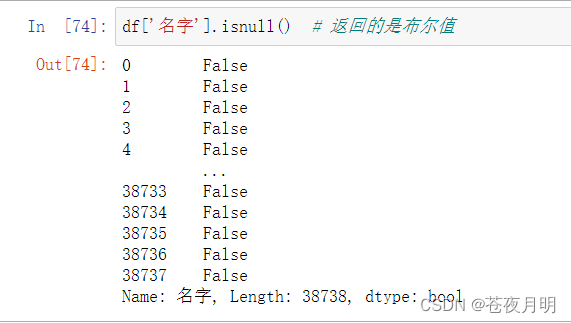
想看具体数据,外面还得再套一层
df[df['名字'].isnull()]

还能进行索引操作
df[df['名字'].isnull()].head()
df[df['名字'].isnull()][:5]

处理缺失值
填充缺失值
df['名字'].fillna('无名好片',inplace=True)
PS: inplace=True意思:直接修改原始数据(不用再赋给一个变量了/覆盖之前的数据)
这时,填充了之后,名字列就没有空值了,isnull就没值了

果然没空值了

没名字的都被无名好片填充了
删除缺失值
df.dropna()参数:
- subset = [ 列名构成的列表 ] :删除指定列缺失值
- haw = “all” :删除全为空值的行或列
- inplace = True :直接修改原始数据(不用再赋给一个变量了/覆盖之前的数据)
- axis = 0 :选择行或列。默认等于0,删除确定了值的这行。如果axis等于1,则这列有一个空值直接全删了,整列全删!

就删了3条。因为之前把名字都填充了,所以其他没什么空的了
; 处理异常值
异常值:
在数据集中存在不合理的值,又称离群点。比如年龄为-1,笔记本电脑重量为1吨等,都属于异常值。
处理方式:
对于异常值,一般来说数量都会很少,在不影响整体数据分布的情况下,直接删除即可。
先查看异常值

跟之前学的一样
; 去除异常值
注意思路:
保存正确的数,而非删除错误的数
df = df[df.投票人数 > 0]
df = df[df.投票人数 % 1 == 0]
这样 df 中投票人数都是大于0且为整数了,保存了正确的数据。
检查一下

现在再看就没有异常值了
数据保存
格式:
对象.to_文件类型(r'路径.文件后缀')
数据处理之后,将数据重新保存到 movie_data.xlsx
df.to_excel(r'D:\数据分析\movie_data.xlsx')
也可以保存到csv文件中
对象.to_csv(r'路径.csv')
练习
Pandas基础知识
(1) 用字典数据类型创建 DataFrame。 data = {‘state’:[‘a’,’b’,’c’,’d’],’year’:[1991,1992,1993,1994],’pop’:[6,7,8,9]}

(2) 将创建的 DataFrame的索引设置为,ABCD。并命名为 “索引”。

(3) 在下面新增一行。然后删除。
先创建一维数组Series

把Series加进DataFrame中

删除

(4) 增加新的属性列,列名设置为 ‘port’,值均为1。

(5) 取出1991和1994年的数据。

(6) 获取 ‘state’ 和 ‘year’ 的数据。

(7) 查看每一列数据的数据格式,并且将 ‘pop’ 每个数据乘2。

; 数据操作
(1) 读取香港酒店数据
df = pd.read_excel(r'D:\数据分析\香港酒店数据.xlsx')
(2) 按照数据的内容,重新设置数据的索引,重新设置列名称为’名字’,’类型’,’城市’,’地区’,’地点’,’评分’,’评分人数’,’价格’。
df.columns = ['名字','类型','城市','地区','地点','评分','评分人数','价格']
(3) 查看所有类型为’浪漫情侣’的酒店
df[df['类型']=='浪漫情侣']
(4) 查看所有类型为’浪漫情侣’,且地区在湾仔的酒店
df[(df['类型']=='浪漫情侣') & (df['地区']=='湾仔')]
(5) 查看所有地区在观塘或者油尖旺,且评分大于4的酒店
df[((df['地区']=='观塘') | (df['地区']=='油尖旺')) & (df['评分']>4)]
(6) 查看类型缺失的数据
df['类型'].isnull()
df[df['类型'].isnull()]
(7) 用’其他’填充 类型和地区
df['类型'].fillna('其他',inplace=True)
df['地区'].fillna('其他',inplace=True)
(8) 用评分均值填充缺失值
df['评分'].fillna(df['评分'].mean(),inplace = True)
(9) 删除价格和评分人数的缺失值
df = df.dropna(subset=['价格','评分人数'])
(10) 保存到 “酒店数据.xlsx”
df.to_excel(r'D:\数据分析\酒店数据.xlsx')

Original: https://blog.csdn.net/qq_56952363/article/details/125124226
Author: 苍夜月明
Title: Python 数据分析 —— Pandas ①
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677869/
转载文章受原作者版权保护。转载请注明原作者出处!