

标注:我用的是jupyterNotebook
一、分组与聚合的原理
在Pandas 中,分组是指使用特定的条件将原数据划分为多个组,聚合在这里指的是,对每个分组中的数据执行某些操作,最后将计算的结果进行整合。
分组与聚合的过程大概分为以下三步:


二、通过groupby方法将数据拆分成组
1、在Pandas 中,可以通过 groupby()方法将数据集按照某些标准划分成若干个组。
groupby(by=None, axis=0, level=None, as_index=True, sort=True,group_keys=True, squeeze=False, observed=False, kwargs)**
- by:用于确定进行分组的依据。
- axis:表示分组轴的方向。
- sort:表示是否对分组标签进行排序,接收布尔值,默认为True 。
2、groupby ()方法会返回一个GroupBy 对象,该对象实际上并没有进行任何计算,只是包含一些关于分组键的中间数据而已。
• 使用 Series 调用 groupby() 方法返回的是 SeriesGroupBy 对 象 。
• 使 用 DataFrame 调用 groupby() 方法返回的是 DataFrameBy 对象。
3、通过groupby()方法的by 参数可以指定按什么标准分组,该参数可以接收的数据主要有以下4 种:
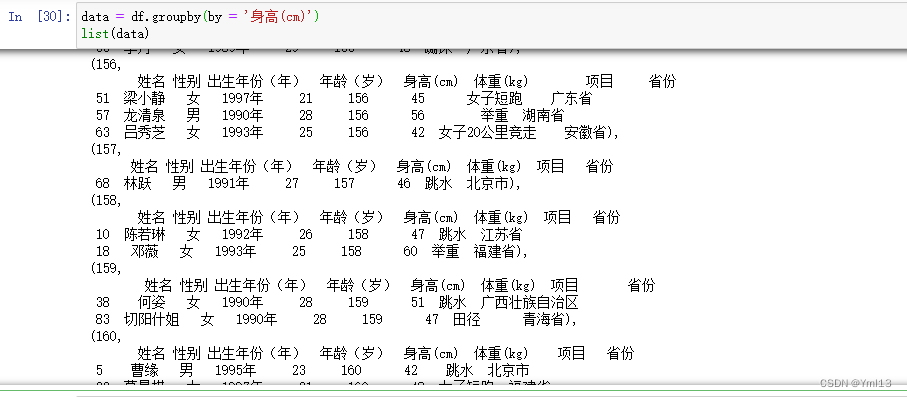
(1) 按列名进行分组
data = df.groupby(by = '身高(cm)')
遍历分组对象
for i in data:
print(i)
#list(data)
(2)按Series 对象进行分组
arr = pd.Series(['a','b','c','d','e','f','g'])
按自定义Series对象进行分组
group_obj = df.groupby(by=arr)
list(group_obj)
结果:

如果Series 对象与Pandas 对象的索引长度不相同时,则只会将具有相同索引的部分数据进行分组。
df = se = pd.Series(['a', 'a', 'b'])
group_obj = df.groupby(se)['one', 'two', 'one','two', 'one'],
'data1': [2, 3, 4, 6, 8],
'data2': [3, 5, 6, 3, 7]})
se = pd.Series(['a', 'a', 'b'])
group_obj = df.groupby(se)
(3)按字典进行分组
mapping = {'a':'第一组','b':'第二组','c':'第一组','d':'第三组','e':'第二组'}
by_column = num_df.groupby(mapping, axis=1)
(4)按函数进行分组
将函数作为分组键会更加灵活,任何一个被当做分组键的函数都会在各个索引值上被调用一次,返回的值会被用作分组名称。
使用内置函数len进行分组
groupby_obj = df.groupby(len)
三、数据聚合
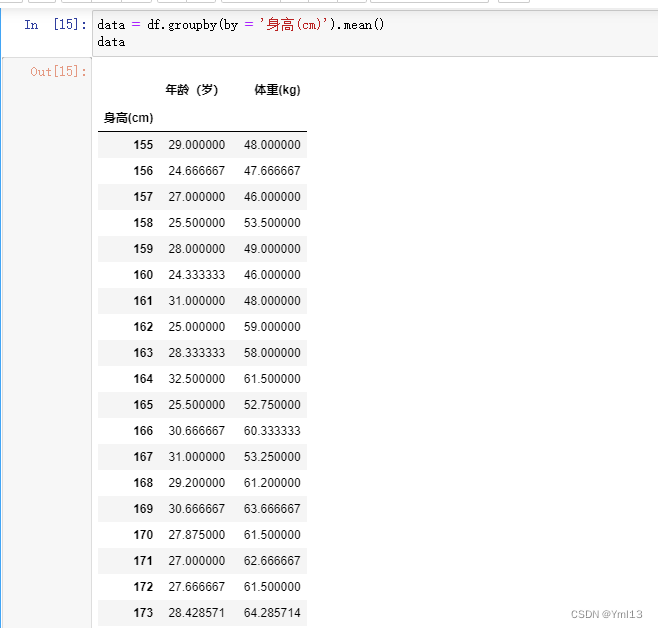
1、获取最大值和最小值的max()和mix(),这些方法常用于简单地聚合分组中的数据。
#进行分组,求每个分组的平均值
data = df.groupby(by = '身高(cm)').mean()
data
结果:
2、对每一列数据应用同一个函数
如果内置方法无法满足聚合要求时,则可以自定义函数,将它作为参数传给agg()方法,实现Pandas 对象的聚合运算。
def dfs(arr):
return arr.max()-arr.min()
data.agg(dfs)
结果:

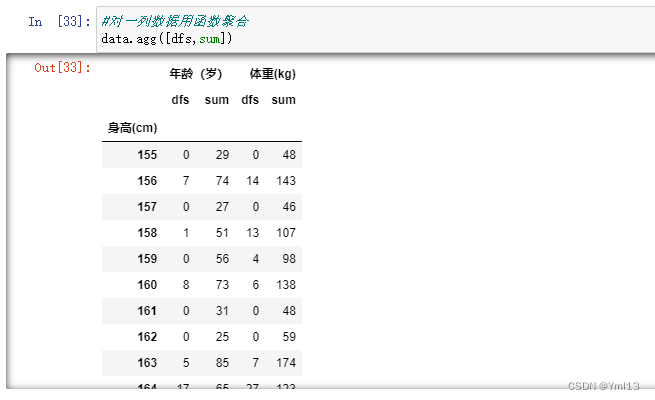
3、对某列数据应用不同的函数
可以将两个函数的名称放在列表中,之后在调用agg()方法进行聚合时作为参数传入即可
#对一列数据用函数聚合
data.agg([dfs,sum])
结果:
4、对不同列数据应用不同函数
如果希望对不同的列使用不同的函数,则可以在agg()方法中传入一个{“列名”:”函数名”}格式的字典。
data_group.agg({'a': 'sum', 'b': 'mean', 'c': range_data_group})
四、分组及运算
1、数据转换
如果希望保持与原数据集形状相同,那么可以通过transfrom()方法实现。
格式如下:
transform(func, *args, kwargs)**
• 上述方法中只有一个 func 参数,表示操作 Pandas 对象的函数。
• transfrom () 方法会把 func 函数应 用 到 各 个分组中,并且 将 计算 结 果放在适当的位置上 。
transform()方法返回的结果有两种,一种是可以广播的标量值(np.mean ),另一种可以是与分组大小相同的结果数组。
2、数据应用
apply()方法的使用是十分灵活的,它可以在许多标准用例中替代聚合和转换,另外还可以处理一些比较特殊的用例。
格式如下:
apply(func, axis=0, broadcast=None, raw=False, reduce=None,result_type=None, args=(), kwds)**
- func:表示应用于某一行或某一列的函数。
- axis:表示函数操作的轴向。
- broadcast:表示是否将数据进行广播。
Original: https://blog.csdn.net/Yml13/article/details/124810442
Author: Yml13
Title: 数据聚合与分组运算
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677383/
转载文章受原作者版权保护。转载请注明原作者出处!