

pandas 案例积累(一)—— 基础应用
- 使用list构造Series
- 使用dict构造Series
- 通过可迭代对象构造Series
- 通过一维数组构造Series
- 通过标量(常数)构造Series
- Series转换成List
- 将Series转换成DataFrame
- 转换Series的数据类型
- 给Series添加新的元素
- 使用dict创建DataFrame
- 使用Series组成的字典创建DataFrame
- 使用字典组成的列表创建DataFrame
- 其他创建DataFrame的方法
- 生成指定范围的日期
- 生成一年的所有周一日期
- 生成一天的所有小时
- 用日期生成DataFrame
- 将日期作为DataFrame的索引
- 查看数据
- 条件选择
- 对列进行排序
- 分组聚合
- 表格转置翻转
- 统计分析
使用list构造Series
import pandas as pd
courses = ["数学", "语文", "英语", "计算机"]
data = pd.Series(data=courses)
print(data)
运行结果:


使用dict构造Series
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
data = pd.Series(data=grades)
print(data)
运行结果:

通过可迭代对象构造Series
import pandas as pd
data = range(5)
print(type(data))
ser_obj = pd.Series(data, index=['a', 'b', 'c', 'd', 'e'])
print(ser_obj)
运行结果:

通过一维数组构造Series
import numpy as np
import pandas as pd
x = np.arange(10, 60, 10)
y = pd.Series(x)
print(y)
运行结果:

通过标量(常数)构造Series
import pandas as pd
x = 22
y1 = pd.Series(x)
print(y1)
print("-分割-"*4)
y2 = pd.Series(x,index=list(range(5)))
print(y2)
运行结果:

Series转换成List
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades)
print(ser_obj.tolist())
运行结果:

将Series转换成DataFrame
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades)
df1 = pd.DataFrame(data=ser_obj, columns=["grade"])
df2 = ser_obj.reset_index()
df2.columns = ["index", "grade"]
print(df1)
print("-分割-"*4)
print(df2)
运行结果:

转换Series的数据类型
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades, dtype=int)
ser_obj1 = ser_obj.astype(float)
ser_obj2 = ser_obj.map(str)
print(ser_obj1)
print("-分割-"*4)
print(ser_obj2)
运行结果:

给Series添加新的元素
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades, dtype=int)
ser_obj = ser_obj.append(pd.Series({
"物理":88,
"化学":99
}))
print(ser_obj)
运行结果:
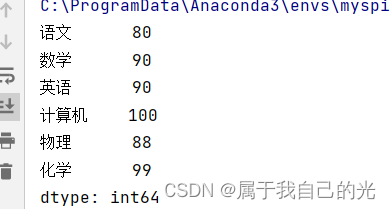
使用dict创建DataFrame
import pandas as pd
df = pd.DataFrame({
"姓名":["小明", "小王", "小李"],
"年龄":[23, 12, 24],
"性别":["男", "男", "女"]
})
print(df)
df.set_index("姓名", inplace=True)
print("-分割-"*4)
print(df)
运行结果:

使用Series组成的字典创建DataFrame
d = {
'x':pd.Series([1, 2, 3], index=['a', 'b', 'c'], dtype=float),
'y':pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'], dtype=float)
}
df = pd.DataFrame(data=d)
print(df)
"""
x y
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
"""
使用字典组成的列表创建DataFrame
list_one = [
{'x':1, 'y':2, 'z':3},
{'x':4, 'y':5}
]
df = pd.DataFrame(data=list_one, index=['a', 'b'])
print(df)
"""
x y z
a 1 2 3.0
b 4 5 NaN
"""
其他创建DataFrame的方法
df1 = pd.DataFrame.from_dict({'国家':['中国', '美国', '日本'], '人口':[13.97, 3, 2]})
print(df1)
"""
国家 人口
0 中国 13.97
1 美国 3.00
2 日本 2.00
"""
df2 = pd.DataFrame.from_records([('中国', '美国', '日本'), (13.97, 3, 2)])
print(df2)
"""
0 1 2
0 中国 美国 日本
1 13.97 3 2
"""
生成指定范围的日期
import pandas as pd
date_range1 = pd.date_range(start='2021-10-01', end='2021-10-06')
print(date_range1)
print("-分割-"*4)
date_range2 = pd.date_range(start='2021-10-01', periods=6)
print(date_range2)
运行结果:

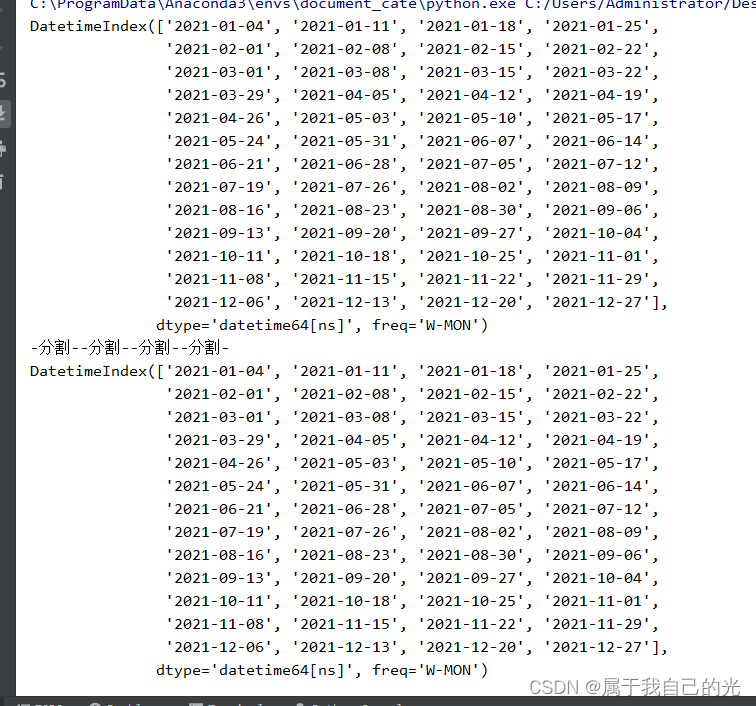
生成一年的所有周一日期
import pandas as pd
date_range1 = pd.date_range(start='2021-01-01', end='2021-12-31', freq='W-MON')
date_range2 = pd.date_range(start='2021-01-01', periods=52, freq='W-MON')
print(date_range1)
print("-分割-"*4)
print(date_range2)
运行结果:
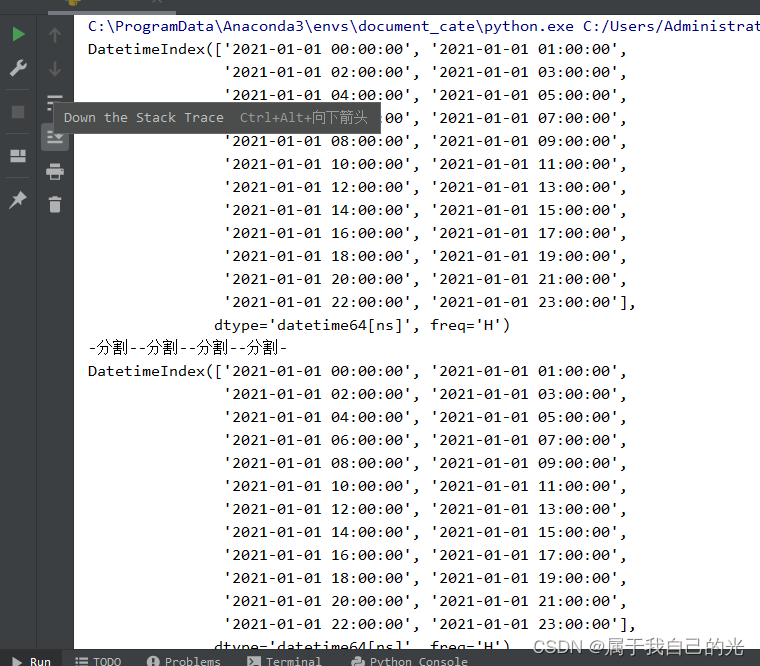
生成一天的所有小时
import pandas as pd
date_range1 = pd.date_range(start='2021-01-01', periods=24, freq='H')
date_range2 = pd.date_range(start='2021-01-01', end='2021-01-02', freq='H', closed='left')
print(date_range1)
print("-分割-"*4)
print(date_range2)
用日期生成DataFrame
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=31)
df = pd.DataFrame(data=date_range, columns=['day'])
df['day_of_year'] = df['day'].dt.dayofyear
print(df)

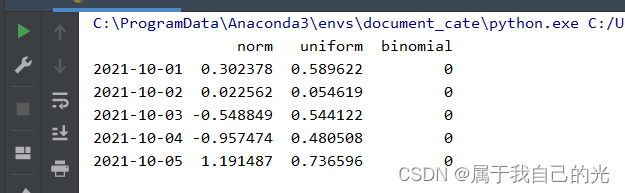
将日期作为DataFrame的索引
import numpy as np
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=5)
data = {
'norm':np.random.normal(loc=0, scale=1, size=5),
'uniform':np.random.uniform(low=0, high=1, size=5),
'binomial':np.random.binomial(n=1, p=0.2, size=5)
}
df = pd.DataFrame(data=data, index=date_range)
print(df)
查看数据
import numpy as np
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=500)
data = {
'norm':np.random.normal(loc=0, scale=1, size=500),
'uniform':np.random.uniform(low=0, high=1, size=500),
'binomial':np.random.binomial(n=1, p=0.2, size=500)
}
df = pd.DataFrame(data=data, index=date_range)
print("查看前3行:\n", df.head(3), end='\n\n')
print("查看后2行:\n", df.tail(2), end='\n\n')
print("随机查看3行:\n", df.sample(3), end='\n\n')
print("查看数据类型、索引情况、行列数、字段类型、使用内存等:")
df.info()
print("\n查看数值型汇总统计:")
print(df.describe())
print("\n查看数据行和列名:\n", df.axes)
print("\n查看各字段类型:\n", df.dtypes)
print("\n查看列名:\n", df.columns)
print("\n查看指定列:\n", df['norm'])
print("\n查看指定的两列:\n", df[['norm', 'binomial']])
print("\n查看指定的两列(等价):\n", df.loc[:, ['norm', 'binomial']])
print("\n查看指定行:\n", df[df.index == '2021-10-04'])
print("\n查看第2到5行(索引取值):\n", df[1:4])
print("\n查看第2到5行(等价写法):\n", df.iloc[1:4, :])
print("\n查看第2到10行(索引取值, 两行取一行):\n", df[1:9:2])
print("\n查看指定行列数据:\n", df.loc['2021-10-04', 'uniform':'binomial'])
print("\n查看指定行列数据:\n", df.loc['2021-10-04':'2021-10-06', 'uniform':'binomial'])
`
查看前3行:
norm uniform binomial
2021-10-01 -0.781939 0.719271 0
2021-10-02 0.487875 0.292774 0
2021-10-03 -0.572962 0.055363 0
查看后2行:
norm uniform binomial
2023-02-11 0.62362 0.135654 0
2023-02-12 -0.35141 0.070681 0
随机查看3行:
norm uniform binomial
2022-11-24 -1.632031 0.153601 0
2023-01-19 -1.239771 0.812020 0
2022-02-12 -1.460656 0.196312 0
查看数据类型、索引情况、行列数、字段类型、使用内存等:
DatetimeIndex: 500 entries, 2021-10-01 to 2023-02-12
Freq: D
Data columns (total 3 columns):
# Column Non-Null Count Dtype
Original: https://blog.csdn.net/qq_37200100/article/details/125401557
Author: 属于我自己的光
Title: pandas 案例积累(一)—— 基础应用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/676862/
转载文章受原作者版权保护。转载请注明原作者出处!