

实现功能:
对年龄(age)这一数值型变量进行分段统计,统计每一区间(年龄段)患者人数。
实现代码:
import numpy as np
import pandas as pd
def Read_data(file):
dt = pd.read_csv(file)
dt.columns = ['age', 'sex', 'chest_pain_type', 'resting_blood_pressure', 'cholesterol',
'fasting_blood_sugar', 'rest_ecg', 'max_heart_rate_achieved','exercise_induced_angina',
'st_depression', 'st_slope', 'num_major_vessels', 'thalassemia', 'target']
data =dt
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
print(data.head().append(dt.tail()))
return data
def Segment_statistics(data):
age = data[["age"]]
bins = [20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
age2 = pd.cut(age.values.flatten(), bins=bins)
print(age2)
print(age2.value_counts())
age2 = pd.DataFrame(age2, columns=["年龄段"]) #
age3 = pd.concat([age, age2], axis=1)
print(age3)
return
if __name__=="__main__":
data1=Read_data("F:\数据杂坛\\0504\heartdisease\Heart-Disease-Data-Set-main\\UCI Heart Disease Dataset.csv")
Segment_statistics(data1)
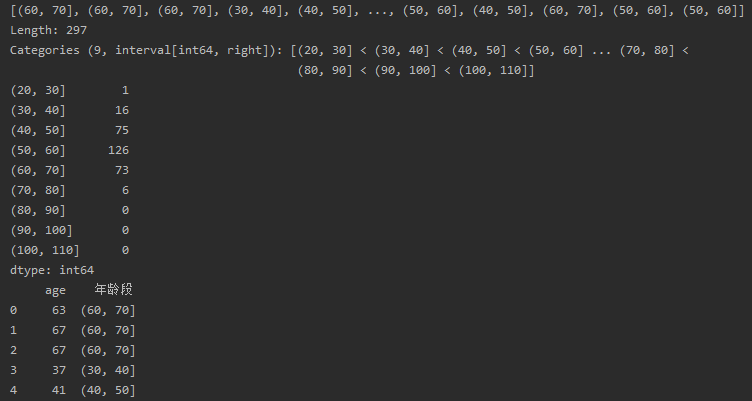
实现效果:
将年龄这一数值型变量进行分段,间隔为10年,统计出每个区间的患者人数,例如20-30的有1人,30-40的有16人…,同时实现增加年龄段这一列。

喜欢记得点赞,在看,收藏,
关注V订阅号:数据杂坛,获取完整代码和效果,将持续更新!

Original: https://blog.csdn.net/sinat_41858359/article/details/124857883
Author: 不再依然07
Title: python实现数值型变量分段统计
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/676293/
转载文章受原作者版权保护。转载请注明原作者出处!