

背景
掌柜最近在做王者荣耀2022KPL春季赛的赛事数据分析,下表kpl是从官方数据平台获取到的 2022KPL春季赛常规赛近500场的赛事数据:


这里大家可以很明显的看到team_bh和team_ph两列下面都是一堆数字,其实它们分别代表的是王者荣耀里面的各个英雄。下表code就是掌柜整理的2022KPL春季赛常规赛登场的所有英雄和对应的数字编码:

; 问题
- 将kpl表中的team_bh和team_ph两列数据进行拆分,分别得出每个战队ban(禁用)的四位英雄和pick(选用)的五位英雄;
- 对拆分后的禁用英雄和选用英雄根据code表进行批量替换。
思路
- 第一个问题其实 考的是pandas对DataFrame的一列里面多个数据拆分为多列,但每列只有一个数据的方法。 在pandas里面对于这样的文本数据,可以使用.str.split()方法按竖线(|)进行拆分, 生成新的DataFrame;然后再用join对两表进行合并,最后删除多余列。
- 第二个问题则是 对pandas的多列进行多值替换的考察。 通常可以采用map()函数、replace()函数或apply()函数来进行替换。
具体方法
- 这里掌柜就先给出 参考代码 再做解说:
import pandas as pd
ban_name = ['ban' + str(x+1) for x in range(4)]
ban = kpl['team_bh'].str.split('|', expand=True)
ban.columns = ban_name
kpl = kpl.join(ban)
kpl
拆分后的效果图:
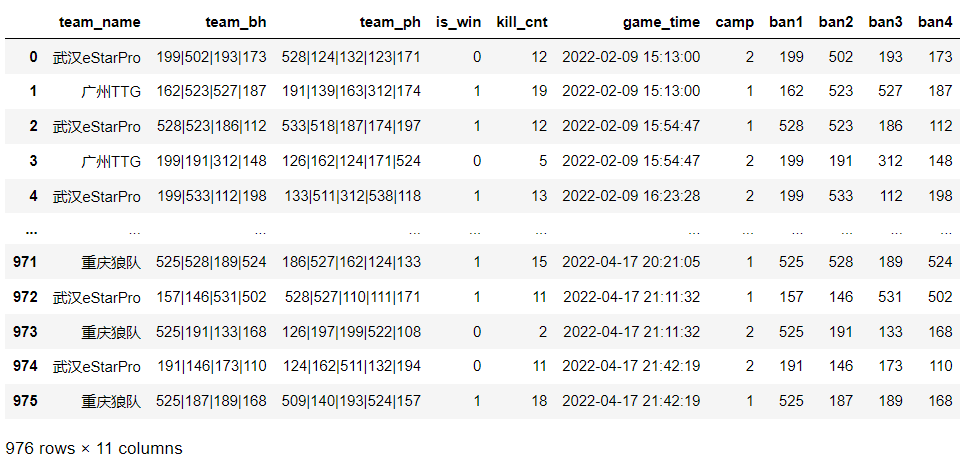
可以看到最后四列就是拆分后的每队禁用英雄,这里取名为ban加上数字1-4,表示禁用英雄的顺序, ban1就是最先禁用的英雄。同理可以对team_ph列进行如上操作,然后删除team_bh和team_ph两列,得到拆分后的新kpl表:
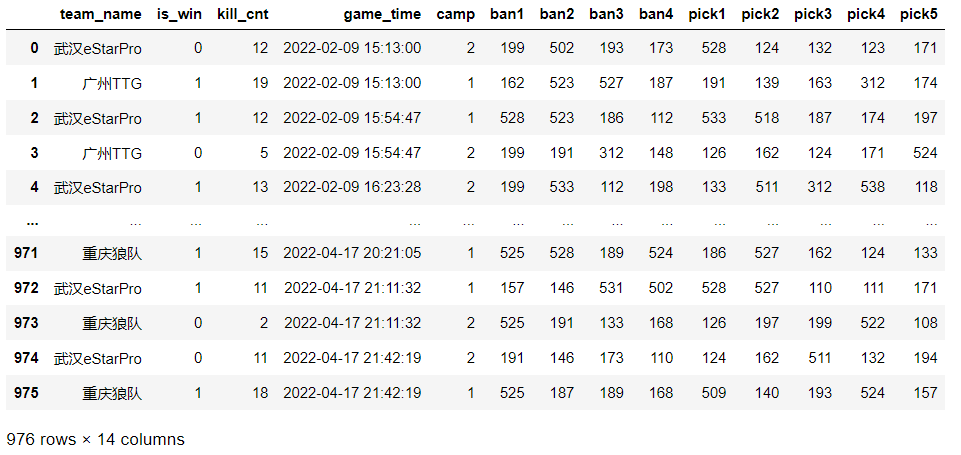
这样就解决了第一个问题,下面来看 第二个问题的具体方法:
- 依然先给出 关键的参考代码(其实主要就这两句):
hero_code = code.set_index(['code'])['hero'].to_dict()
kpl['ban1'] = kpl['ban1'].map(hero_code)
替换后新的kpl表:
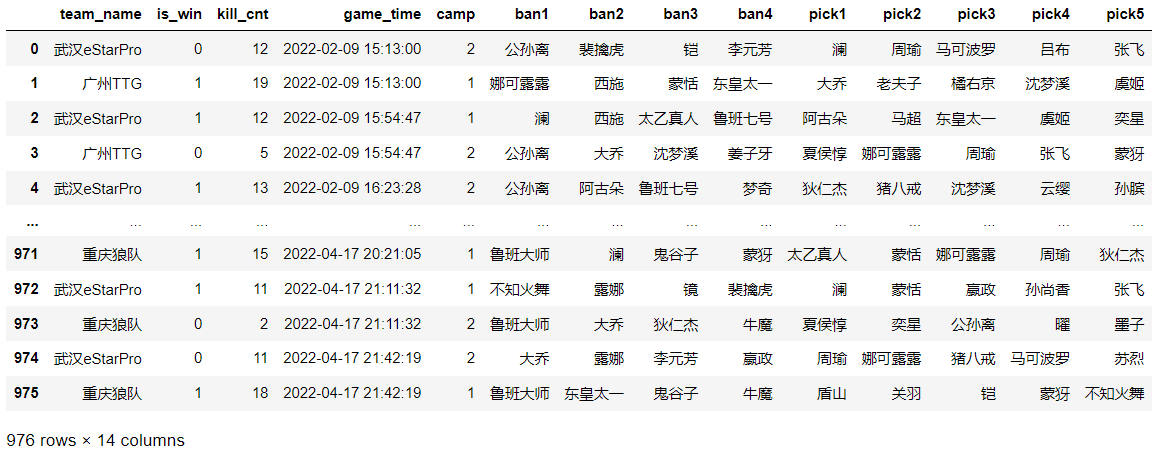
首先掌柜 对code表进行了一个转换,将里面的数字编码和对应英雄转换为字典格式,这样方便后面进行批量的多值替换。
接着掌柜 用map()函数进行一个映射操作(也就是每一列的数字都根据字典中的key进行一个匹配,如果适配,就替换为对应的英雄名字);当然这里也可以使用 replace()函数或apply()函数来替换,但是速度没有map()函数的快。
结果
现在这张经过处理后的kpl赛事数据表就干净很多了,我们可以一眼就看出来每个战队禁用英雄的顺序( 公孙离和鲁班大师几乎都在第一ban位🤣)和选用英雄的优先级( 夏侯惇和澜一选的概率较大),后面将会根据各个战队进行一系列的数据分析和挖掘工作,敬请期待!🤝😁
PS:完整的代码会在整个项目做完后放上Github,谢谢耐心等待和理解。
参考资料:
按照字典dict替换Pandas DataFrame的值:三种方法性能比较
Original: https://blog.csdn.net/weixin_41013322/article/details/124408217
Author: 小白掌柜
Title: Pandas 根据一张DataFrame的两列数据对另一张DataFrame的多列值进行批量替换
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675177/
转载文章受原作者版权保护。转载请注明原作者出处!