

问题场景:
在处理dataframe时,可能会遇到某一列/ 几列数据连续缺失的情况,连续缺失行数较少的情况可以考虑插值填充,连续缺失行数过多时,可能需要将连续缺失值所在行的数据完全删除。
如何快速删除连续缺失的多行数据,并且缺失的阈值可选择的?
不想看原理的,可以直接跳到”函数封装”
解决思路:


假设有形式如上的dataframe,绿色代表非空值,灰色代表nan值,删除连续缺失≥n行的思路如下:
首先,对每一列而言,筛选出连续缺失 ≥ 阈值n的数据,
然后获取其对应的index值,并保存到一个列表list_missing中,
对每一列数据进行如上操作,并根据列表储存的index值,删除原dataframe对应行数据。
代码详解
step1.读取数据
import pandas as pd
import numpy as np
生成数据
NaN = np.nan
data = pd.DataFrame({"SO2":[10, 5, 5, NaN, 9, NaN, NaN, NaN],
"NO2":[12, NaN, NaN, 10, 10, 23, 15, 9],
"CO2":[15, 23, NaN, 24, 25, NaN, NaN, NaN],
"O3":[17, 23, 33, NaN, NaN, NaN, 5, 22]
})
data = data.fillna("*") # 为什么要替换空值,后文会讲
本例数据形式如下:

这里将空值用 “*” 替换,原因后面会讲,另外,填充的值不能和非缺失值重复。
step2.提取dataframe的列名
key = "SO2"
df1 = data[key].to_frame() # series转换为dataframe
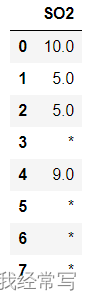 df1的形式如左图所示。
df1的形式如左图所示。
step3.将连续重复出现的数据聚合
这里会用到如下代码,将逐层讲解
df1[key].shift() != df1[key]
df1[key].shift()是将每一行的值下移动一行,
可以看到,第一行变为NaN,其余值依次往下移动一位。
df1[key].shift() != df1[key]的判断结果如下:
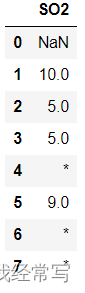

需要注意的是,np.nan不等于np.nan,这就是之前要对缺失值进行替换的原因。
后面再加上 cumsum()
(df1[key].shift() != df1[key]).cumsum()
cumsum()给出一个非降序的id序列,其中每个id表示一个具有相同值的连续块(在对布尔值求和时,True被认为是一,而False被认为是零)

通过groupby(),将数据按照相同长度进行聚合,并使用filter()筛选出连续重复长度≥设定阈值的数据。
threshold = 2 # 设置连续缺失阈值
df2 = df1.groupby((df1[key].shift() != df1[key]).cumsum()
).filter(lambda x: len(x) >= threshold)

df3 = df2[df2[key].isin(["*"])]

step4.获取连续缺失行的index值
list1 = df3.index.tolist()

对每一列都进行如上处理,获得所有连续缺失行index,最后用drop同意删除就可以了,下面对前文所述进行封装,以便调用。
函数封装
def missing_treat(df, key, fill, threshold):
df1 = df[key].to_frame()
df2 = df1.groupby((df1[key].shift() != df1[key]).cumsum()).filter(lambda x: len(x) >= threshold)
list1 = df2[df2[key].isin([fill])].index.tolist()
return list1
函数的参数有
df: 原始的dataframe(需要替换np.nan后的)
key: dataframe的列名
fill: 对np.nan进行替换的值
threshold:连续缺失阈值,连续缺失行≥threshold的,删除
调用一下,
数据准备
NaN = np.nan
data = pd.DataFrame({"SO2":[10, 5, 5, NaN, 9, NaN, NaN, NaN],
"NO2":[12, NaN, NaN, 10, 10, 23, 15, 9],
"CO2":[15, 23, NaN, 24, 25, NaN, NaN, NaN],
"O3":[17, 23, 33, NaN, NaN, NaN, 5, 22],
})
keys = []
for key in data.columns: # 读取列名
keys = np.append(keys, key)
df0 = data.fillna("*") # 缺失值填充
res = []
for key in keys[2:]:
list_missing = missing_treat(df=df0, key=key, fill="*", threshold=2)
res = sorted(list(set(res).union(list_missing))) # 对所有list_missing求并集
data.drop(index=res, inplace=True) # 根据index删除原dataframme对应行
data

参考
上面的参考最后用了merge,实际使用时,发现会出问题,在一些特定情况(包括本例)不能达到使用要求,所以改用记录index来删除。
实现方式肯定不止一种,文章也可能存在错误,欢迎大家批评交流。
Original: https://blog.csdn.net/qq_57313910/article/details/126769783
Author: bug嘛我经常写
Title: pandas 删除连续缺失超过n行的数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674922/
转载文章受原作者版权保护。转载请注明原作者出处!