

pandas按行,按列取值,主要使用的是 iloc和 loc函数进行取值
下面就介绍下取值
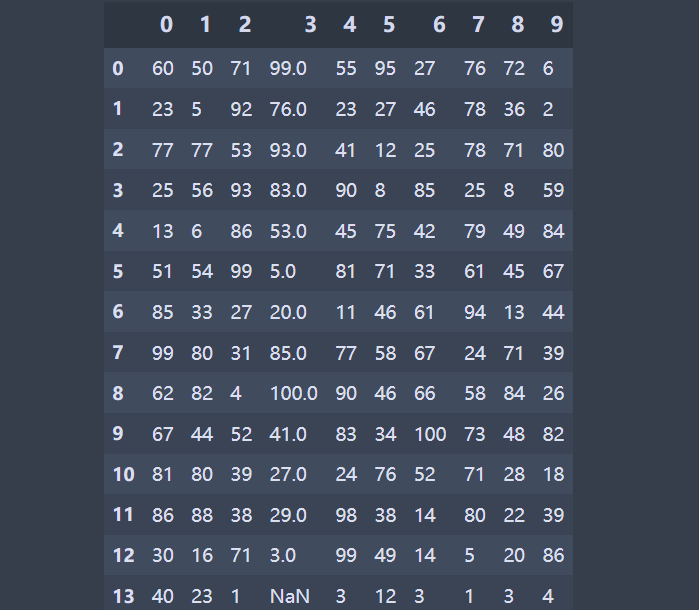

这个是我创建的数据,现在我们需要取出第一行到第五行,第一列到第5列的数据
import pandas as pd
data = pd.read_excel('excel_col.xlsx')
print(data.iloc[:5,:5])
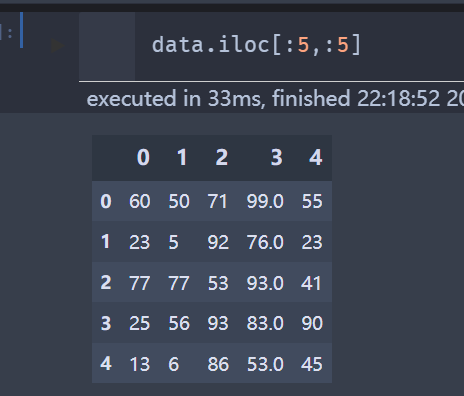
如果想直接从第3列开始
data.iloc[:5,2:5]
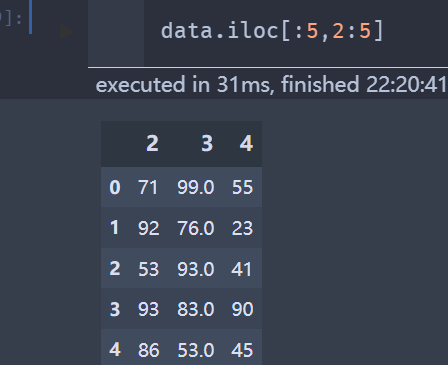
以上为 iloc函数,iloc[],前面的为取行,然后使用,隔开再取列
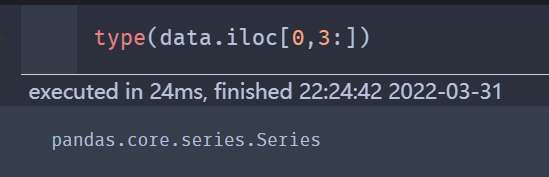
如果取单独的一行,用第1行举例,取第1行,从第4列开始,取到最后一列
data.iloc[0,3:]
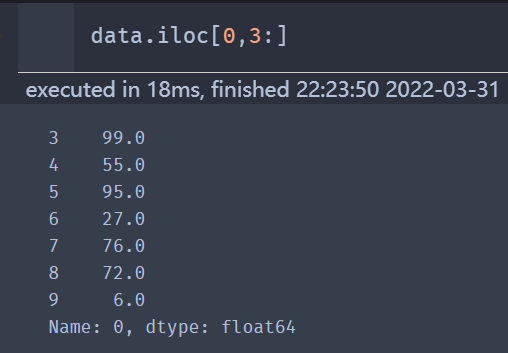
列同上,如果是取单独的一列或者单独的一行,则类型为 series
接下来使用 loc函数, loc函数,不同于iloc,loc函数后面的列,必须为列名,不能直接是列的索引(即数字)
因为我的数据比较特殊,列名是用数字代替的,所以希望大家不要混肴
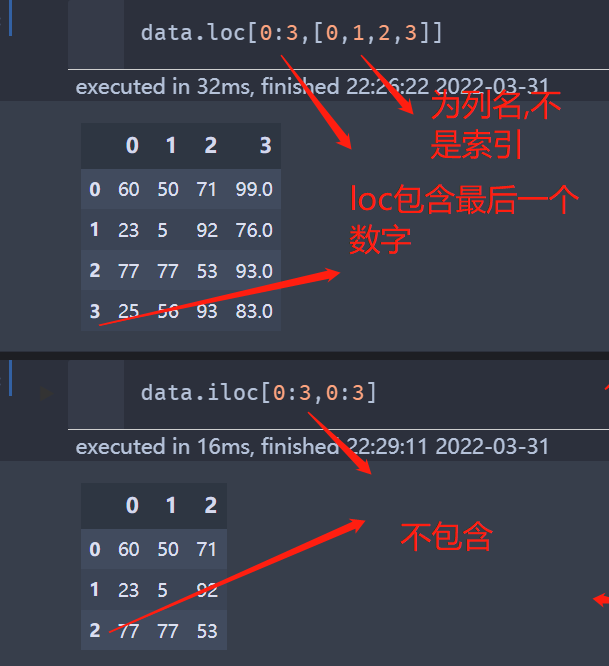
还是一样,取前4行,前4列
需要注意的是对于iloc[] 函数来讲,我们指定最后一行的时候,是不包含的,但是loc[]是包含的
data.loc[0:3,[0,1,2,3]]
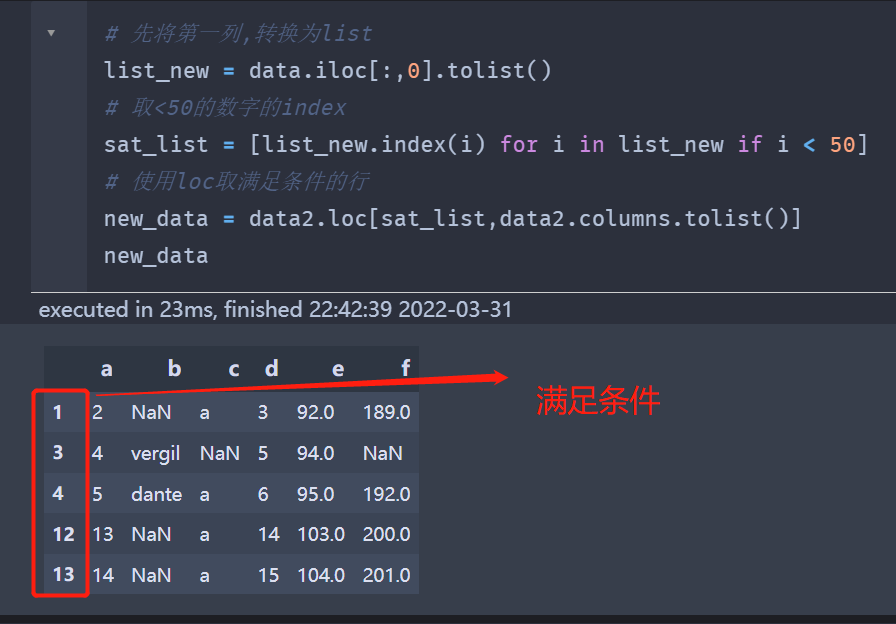
有时候,我们读取的是两个文件,然后根据第一个文件满足条件的行,取第二个文件的行数
使用 loc即可满足
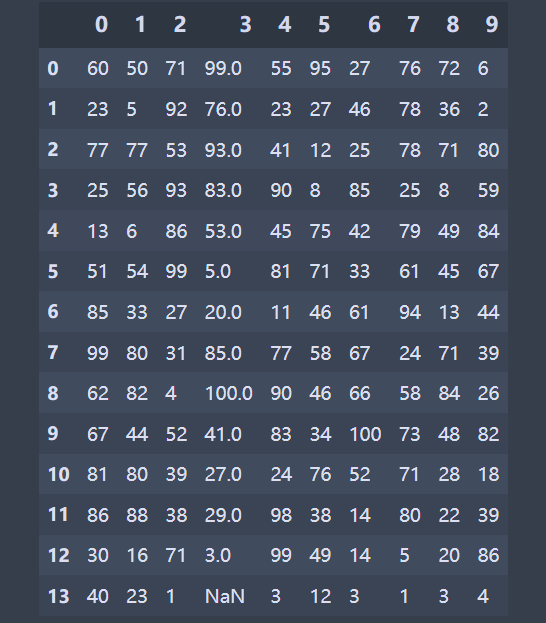
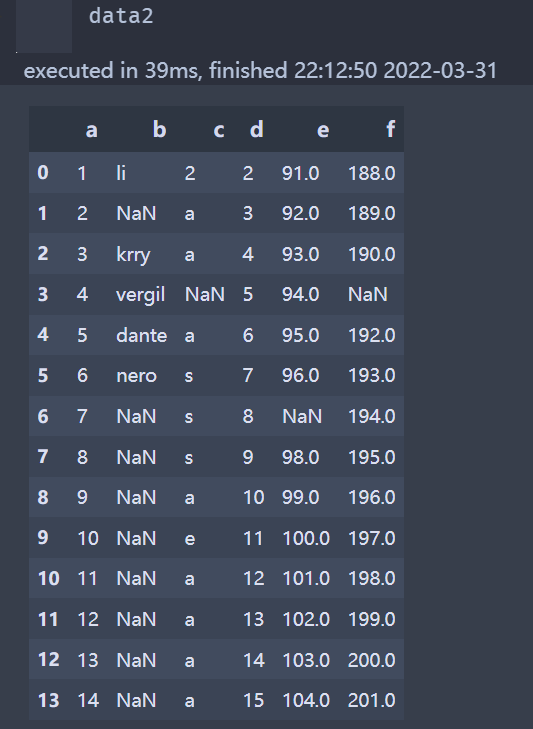
上面是两个dataframe
现在我需要在第一个dataframe取出第一列满足
import pandas as pd
data = pd.read_excel('excel_col.xlsx')
data2 = pd.read_excel('test.xlsx')
list_new = data.iloc[:,0].tolist()
sat_list = [list_new.index(i) for i in list_new if i < 50]
new_data = data2.loc[sat_list,data2.columns.tolist()]
Original: https://blog.csdn.net/KIKI_ZSH/article/details/123885234
Author: Vergil_Zsh
Title: pandas实现按行取值或者按照行取另外一组数据的值
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674821/
转载文章受原作者版权保护。转载请注明原作者出处!