

设逾期表为df,格式为pandas.DataFrame,详细数据如下所示,其中order_no为非
重复订单号,overdue_days为逾期天数,info_tabel为逾期标签,其中1表示逾期,
0表示未逾期
设逾期表为df,格式为pandas.DataFrame,详细数据如下所示,其中order_no为非
重复订单号,overdue_days为逾期天数,info_tabel为逾期标签,其中1表示逾期,
0表示未逾期
import pandas as pd
import numpy as np
from IPython.display import display
df = pd.DataFrame({
'order_no':['order_18213','order_16061','order_10176','order_11923','order_18791','order_12534','order_14502','order_14488','order_15488','order_18118'],
'province':['山东','四川','福建','广东','广东','广东','广东','山东','湖南','福建',],
'gender':[ '女', '女', '女', '女', '男', '女', '男', '男', '女', '女'],
'age':[ 29.0, 27.0, 25.0, 25.0,np.nan, 27.0, 25.0, 27.0,np.nan, 27.0],
'education':[ '本科', '研究生', '本科', '研究生', '研究生', '本科', '大专', '大专', '本科', '大专'],
'overdue_days':[ 0, 17, 0, 0, 12, 20, 22, 32, 0, 2],
'info_label':[ 0, 1, 0, 0, 1, 1, 1, 1, 0, 1]
})
display(df)
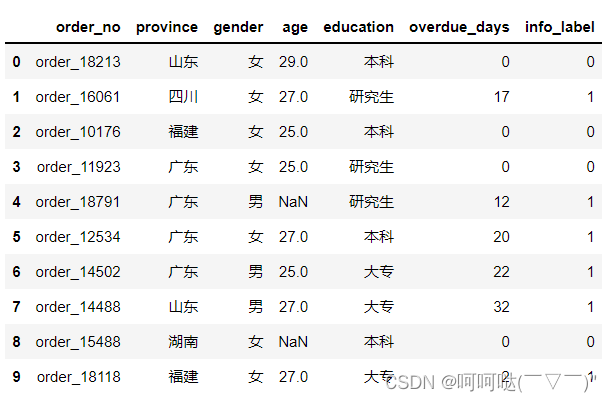

题目1:将gender列中的 男 ,女分别替换为数值1、0
题目1:将gender列中的 男 ,女分别替换为数值1、0
【方法1】
df['gender'] = df['gender'].map({'男':1,'女':0})
display(df)
【方法2】
df['gender'] = df['gender'].replace(['男','女'],[1,0])
display(df)
【方法3】
df.loc[df['gender']=='男','gender'] = 1
df.loc[df['gender']=='女','gender'] = 0
display(df)
注意df.loc用法:
df.loc[行标签,列标签]
df.loc['a':'b']#选取ab两行数据
df.loc[:,'one']#选取one列的数据
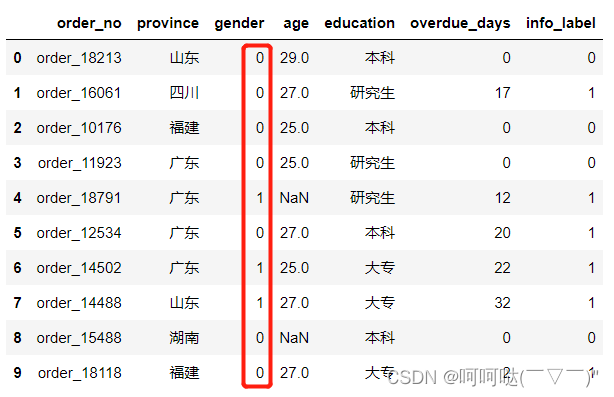
题目2:将age列的缺失值用age列的均值代替
题目2:将age列的缺失值用age列的均值代替
使用fillna填补缺失值即可
df_mean = df['age'].mean()
df['age'].fillna(df_mean,inplace=True)
print(df)
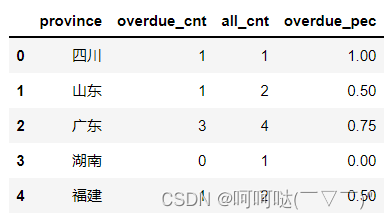
题目3:计算各省的平均逾期率
逾期率=逾期客户/全部客户
题目3:计算各省的平均逾期率
逾期率=逾期客户/全部客户
计算各省的逾期用户
df_overdue = df.groupby('province')['info_label'].sum().reset_index()
df_overdue.columns=['province', 'overdue_cnt']
display(df_overdue)
计算各省的用户数
df_all = df.groupby('province')['info_label'].count().reset_index()
df_all.columns=['province', 'all_cnt']
display(df_all)
合并各省逾期用户及各省用户数形成新的报表df1
df1 = pd.merge(df_overdue,df_all,on=['province'],how='left')
得到各省的逾期率
df1['overdue_pec'] = df1['overdue_cnt']/df1['all_cnt']
display(df1)
题目4:计算广东省男性用户的逾期率
题目4:计算广东省男性用户的逾期率
计算广东省的逾期男性用户的人数
overdue_maleCount = df[(df['province']=='广东') & (df['gender']== 1)]['info_label'].sum()
overdue_allMaleCount = df[(df['province']=='广东') & (df['gender']== 1)]['info_label'].count()
overdue_pec_gd = overdue_maleCount / overdue_allMaleCount
display(overdue_pec_gd)
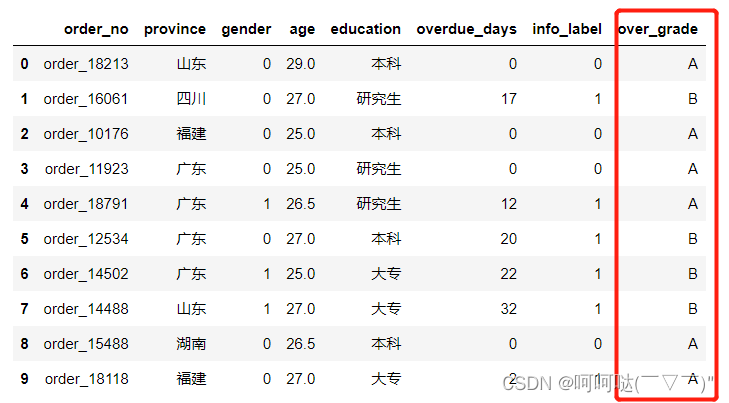
题目5:在df里面新增1列overdue_grade,其中
overdue_days=15时 overdue_grade取值为B
题目5:在df里面新增1列overdue_grade,其中
overdue_days=15时 overdue_grade取值为B
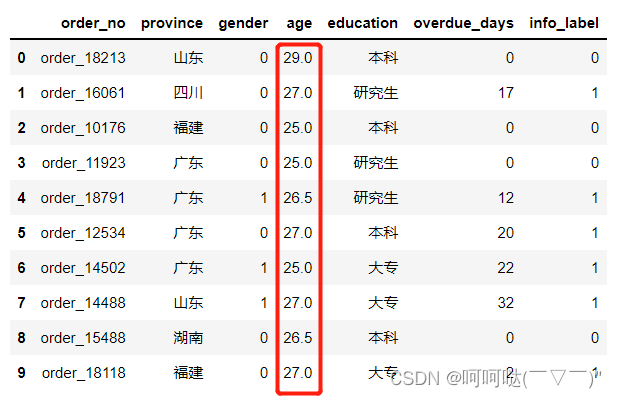
df['over_grade'] = df['overdue_days'].apply(lambda x: 'A' if x < 15 else'B')
display(df)
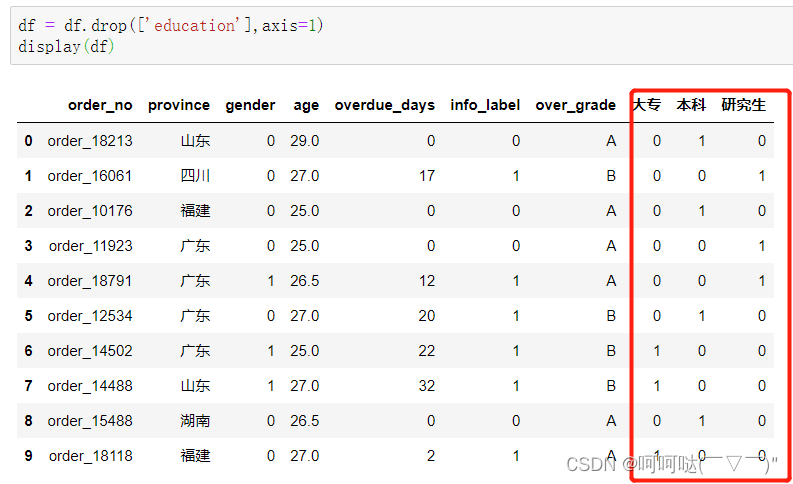
题目6:将类别型变量education 转化为哑变量(Dummy Variables),
并与原df在axis=1 方向上合并,然后删除初始的education列
题目6:将类别型变量education 转化为哑变量(Dummy Variables),
并与原df在axis=1 方向上合并,然后删除初始的education列
使用get_dummies进行one-hot变量,然后进行数据合并concat,删除使用drop
df=pd.concat((df,pd.get_dummies(df['education'])),axis=1)
print(df)
df = df.drop(['education'],axis=1)
print(df)

>>注意:在Jupyter环境下运行的代码,dataframe表格怎么对齐?
from IPython.display import display
display(df)
>>使用pandas数据处理数据,最好用的函数搭配:apply+lambda
#函数应用和映射
import numpy as np
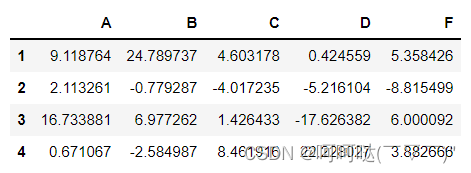
import pandas as pd
df=pd.DataFrame(np.random.randn(4,5)*10,columns=list('ABCDF'),index=['1','2','3','4'])
display(df)
知识点补充:
d1 = df.apply(lambda x: x.max()-x.min())
display(d1)

d2 = df.apply(lambda x: x.max()-x.min(),axis=1)
display(d2)

浮点值保留两位小数
d3=df['B'].map(lambda x: '%.2f'%x)
display(d3)

d4=df.applymap(lambda x: '%.2f'%x)['B']
display(d4)

lambda 参数:操作(参数)
#单个参数的:
h = lambda x : x 2
print(h(3)) # 9
#多个参数的:
h = lambda x, y, z : (x + y) z
print(h(1,2,2)) # 9
map(lambda x : x + 1, [1, 2, 3]) # [2,3,4]
map(lambda x: x*x, [y for y in range(10)]) #将一个 list 里的每个元素都平方
(lambda x,y: x if x> y else y)(101,102) # 102
>> 保存dataFrame数据到excel文件
import pandas as pd
import numpy as np
df = pd.DataFrame({
'order_no':['order_18213','order_16061','order_10176','order_11923','order_18791','order_12534','order_14502','order_14488','order_15488','order_18118'],
'province':['山东','四川','福建','广东','广东','广东','广东','山东','湖南','福建',],
'gender':[ '女', '女', '女', '女', '男', '女', '男', '男', '女', '女'],
'age':[ 29.0, 27.0, 25.0, 25.0,np.nan, 27.0, 25.0, 27.0,np.nan, 27.0],
'education':[ '本科', '研究生', '本科', '研究生', '研究生', '本科', '大专', '大专', '本科', '大专'],
'overdue_days':[ 0, 17, 0, 0, 12, 20, 22, 32, 0, 2],
'info_label':[ 0, 1, 0, 0, 1, 1, 1, 1, 0, 1]
})
print(df)
tmp_file_path='test.xlsx'
writer = pd.ExcelWriter(tmp_file_path)
df.to_excel(writer, sheet_name=tmp_file_path.split('.')[0],index= False)
worksheet = writer.sheets[tmp_file_path.split('.')[0]]
worksheet.set_column(0,1, 35) #指定第1-2列为35像素宽度
worksheet.set_column(2,13, 10) #指定第3-13列为10像素宽度
writer.save()
>>pandas读取excel文件的数据
import pandas as pd
df = pd.read_excel("test.xlsx")
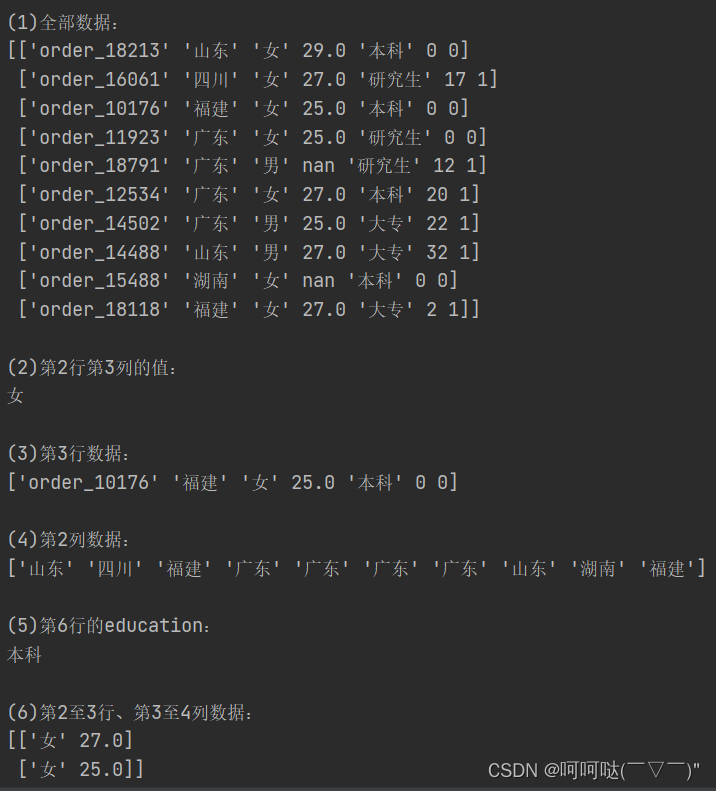
print("\n(1)全部数据:")
print(df.iloc[:,:].values)
print("\n(2)第2行第3列的值:")
print(df.iloc[1,2])
print("\n(3)第3行数据:")
print(df.iloc[2].values)
print("\n(4)第2列数据:")
print(df.iloc[:,1].values)
print("\n(5)第6行的education:")
print(df.loc[5,"education"])
print("\n(6)第2至3行、第3至4列数据:")
print(df.iloc[1:3,2:4].values)
Original: https://blog.csdn.net/weixin_41987016/article/details/126874868
Author: 呵呵哒( ̄▽ ̄)”
Title: python数据分析-面试题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674701/
转载文章受原作者版权保护。转载请注明原作者出处!