

在python中,我们常用的数据分析库莫过于pandas,而数据分析中,我们常用的方法莫过于筛选、拼接、多级列表和数据透视了,下面我将通过四个板块对这四个方面进行介绍。
目录
- 筛选
- 拼接(连接)
- 多级列表
- 数据透视
- 完整代码
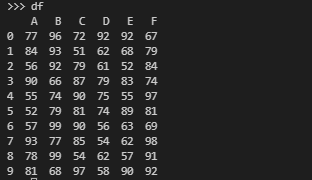
首先创建一个 10*6的Dataframe,用到的库有 pandas、numpy
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
df

一、 筛选
对于excel的常用就是对某列进行筛选操作了,那么我们在pandas中如何进行呢?其实pandas给我们提供了多个方法,不过最常用的还是 loc和 iloc,这两个方法的筛选逻辑不一样,简单的理解来说就是: loc是关注于列的筛选,iloc关注的行的筛选,两者的功能没有区别下面我分别介绍两种方法。
1.1、loc
上面已经创建好了df,下面我们开始利用df进行讲解
df.loc[a,b]
a表示行,b表示列,注意b只能为字符或者列表,不能为数字,否则报错,下面是相关的方法运用。
单列数据筛选
>>> df.loc[:,"A"]
0 77
1 84
2 56
3 90
4 55
5 52
6 57
7 93
8 78
9 81
Name: A, dtype: int32
多列数据筛选
df.loc[:,["A","B"]]
A B
0 77 96
1 84 93
2 56 92
3 90 66
4 55 74
5 52 79
6 57 99
7 93 77
8 78 99
9 81 68
也可以用:来进行引用,如下
>>> df.loc[:,"A":"E"]
A B C D E
0 77 96 72 92 92
1 84 93 51 62 68
2 56 92 79 61 52
3 90 66 87 79 83
4 55 74 90 75 55
5 52 79 81 74 89
6 57 99 90 56 63
7 93 77 85 54 62
8 78 99 54 62 57
9 81 68 97 58 90
上面简单的介绍了 loc方法筛选列,下面来介绍筛选行
对多行的单列值进行筛选:
>>> df.loc[df['B']==99]
A B C D E F
6 57 99 90 56 63 69
8 78 99 54 62 57 91
对B列进行筛选筛选其值等于99的数据。
对多行数据的多列值进行筛选:
>>> df.loc[(df['B']==99)&(df['C']==90)] #注意细节,这里需要加(),否则会报错
A B C D E F
6 57 99 90 56 63 69
这里有个细节,对列的数据进行并列筛选时,注意细节,这里需要加(),否则会报错
1.2、iloc
下面来介绍iloc,用法大概如下
df.iloc[a,b]
这个地方a和b都必须是intege。iloc的列参数只能是整数;
a代表的行,b代表的列
列筛选:
>>> df.iloc[2,:]
A 56
B 92
C 79
D 61
E 52
F 84
Name: 2, dtype: int32
>>> df.iloc[2,3:5]
D 61
E 52
Name: 2, dtype: int32
如果发现这个取数的格式不是我们想的那样,想要如df格式那样,如下:
>>> df.iloc[2:3,3:5]
D E
2 61 52
这里进行总结一下,loc和iloc的主要区别有两个
1、两者参数都是[行,列],但是loc的列参数不能为数字,必须为columns,否则会报错
iloc的参数为数字,否则也会报错
2、: loc的带:参数实行的左闭右闭规则,但是iloc实行的是左闭右开规则,所以取数逻辑不一样。
二、拼接
拼接,又称作连接,对于df的绘制非常的重要,一般常用的有 append、merge、concat,在这里,主要讲解 merge和concat。
2.1、merge
merge的产生主要如下:
pd.merge(left, right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False, sort=True,
suffixes=('_x', '_y'),
copy=True,
indicator=False,
validate=None)
我们在拼接过程中常用的是on、how,我也只准备从这两个方面展开:
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。
如果未传递且left_index和right_index为False,
则DataFrame中的列的交集将被推断为**连接键。**
how: 参数有4个。**inner是取交集,left,right,outer取并集。没有同时出现的会将缺失的部分添加缺失值。**
下面是相关的实例:
outer
>>> df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
>>> df1
A B C D E F
0 66 69 84 87 76 51
1 60 50 75 80 93 78
2 55 57 92 91 88 60
3 89 77 68 92 53 75
4 93 64 58 55 67 68
5 85 85 50 56 70 82
6 93 56 74 58 73 82
7 57 83 77 91 72 73
8 90 78 67 58 95 84
9 96 96 67 50 78 72
>>> df2=pd.DataFrame(np.random.randint(50,100,(10,5)),columns=['F',"M",'N','X','Y'])
>>> df2
F M N X Y
0 77 96 67 75 65
1 57 55 61 98 89
2 80 51 68 64 53
3 66 68 88 71 76
4 59 58 89 65 99
5 75 81 82 61 64
6 50 55 97 57 81
7 91 96 83 59 82
8 89 87 67 88 72
9 91 86 82 83 55
>>> pd.merge(df1,df2,on="F",how="outer")
A B C D E F M N X Y
0 66.0 69.0 84.0 87.0 76.0 51 NaN NaN NaN NaN
1 60.0 50.0 75.0 80.0 93.0 78 NaN NaN NaN NaN
2 55.0 57.0 92.0 91.0 88.0 60 NaN NaN NaN NaN
3 89.0 77.0 68.0 92.0 53.0 75 81.0 82.0 61.0 64.0
4 93.0 64.0 58.0 55.0 67.0 68 NaN NaN NaN NaN
5 85.0 85.0 50.0 56.0 70.0 82 NaN NaN NaN NaN
6 93.0 56.0 74.0 58.0 73.0 82 NaN NaN NaN NaN
7 57.0 83.0 77.0 91.0 72.0 73 NaN NaN NaN NaN
8 90.0 78.0 67.0 58.0 95.0 84 NaN NaN NaN NaN
9 96.0 96.0 67.0 50.0 78.0 72 NaN NaN NaN NaN
10 NaN NaN NaN NaN NaN 77 96.0 67.0 75.0 65.0
11 NaN NaN NaN NaN NaN 57 55.0 61.0 98.0 89.0
12 NaN NaN NaN NaN NaN 80 51.0 68.0 64.0 53.0
13 NaN NaN NaN NaN NaN 66 68.0 88.0 71.0 76.0
14 NaN NaN NaN NaN NaN 59 58.0 89.0 65.0 99.0
15 NaN NaN NaN NaN NaN 50 55.0 97.0 57.0 81.0
16 NaN NaN NaN NaN NaN 91 96.0 83.0 59.0 82.0
17 NaN NaN NaN NaN NaN 91 86.0 82.0 83.0 55.0
18 NaN NaN NaN NaN NaN 89 87.0 67.0 88.0 72.0
inner
>>> df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
>>> df1
A B C D E F
0 91 55 73 66 77 93
1 82 88 67 57 93 80
2 51 58 56 81 62 75
3 63 85 93 99 50 85
4 98 92 58 63 72 66
5 93 79 85 76 64 86
6 67 69 86 57 73 69
7 94 69 84 79 78 84
8 62 83 68 70 61 78
9 88 84 98 76 85 87
>>> df2=pd.DataFrame(np.random.randint(50,100,(10,5)),columns=['F',"M",'N','X','Y'])
>>> df2
F M N X Y
0 94 95 71 71 68
1 71 94 63 89 97
2 50 95 80 70 82
3 79 83 87 72 99
4 87 93 70 66 95
5 91 78 90 59 87
6 58 63 67 81 70
7 64 77 67 64 86
8 76 89 94 62 52
9 67 79 51 63 61
>>> pd.merge(df1,df2,on="F",how="inner")
A B C D E F M N X Y
0 88 84 98 76 85 87 93 70 66 95
两者的区别可以总结如下
1、inner取拼接列的共有值(交集),将两边的列进行组合
2、outer取拼接列的所有值(并集),将两边的列进行组合,对于多出来的列值,用NaN填充
2.2、concat
concat的参数如下
pd.concat(objs,
axis=0,
join='outer',
join_axes=None,
ignore_index=False,
keys=None, levels=None,
names=None,
verify_integrity=False,
copy=True)
主要参数简介
objs:一般为列表,表示要拼接的df,形如[df1,df2,df3]
join:拼接的类型,如merge的参数
axis:拼接的类型,纵向拼接还是横向拼接
ignore_index:是否对新表的index进行重构,重新排序
实例如下
纵向连接,作用与merge的outer一样
>>> df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
>>> df1
A B C D E F
0 97 58 92 71 56 64
1 81 68 90 70 83 84
2 79 56 52 94 68 80
3 76 70 69 79 63 77
4 81 63 67 65 76 63
5 86 98 85 92 76 79
6 99 96 56 78 53 84
7 53 79 99 65 86 81
8 55 60 66 66 61 61
9 66 56 59 56 98 84
>>> df2=pd.DataFrame(np.random.randint(50,100,(10,5)),columns=['F',"M",'N','X','Y'])
>>> df2
F M N X Y
0 59 56 61 57 54
1 72 53 74 53 51
2 65 93 83 96 79
3 95 56 50 85 97
4 95 70 57 70 52
5 50 92 76 66 88
6 81 85 80 54 51
7 65 62 60 77 79
8 53 81 66 87 59
9 59 94 57 95 55
>>> # pd.merge(df1,df2,on="F",how="inner")
>>>
>>> pd.concat([df1,df2],axis=0)
A B C D E F M N X Y
0 97.0 58.0 92.0 71.0 56.0 64 NaN NaN NaN NaN
1 81.0 68.0 90.0 70.0 83.0 84 NaN NaN NaN NaN
2 79.0 56.0 52.0 94.0 68.0 80 NaN NaN NaN NaN
3 76.0 70.0 69.0 79.0 63.0 77 NaN NaN NaN NaN
4 81.0 63.0 67.0 65.0 76.0 63 NaN NaN NaN NaN
5 86.0 98.0 85.0 92.0 76.0 79 NaN NaN NaN NaN
6 99.0 96.0 56.0 78.0 53.0 84 NaN NaN NaN NaN
7 53.0 79.0 99.0 65.0 86.0 81 NaN NaN NaN NaN
8 55.0 60.0 66.0 66.0 61.0 61 NaN NaN NaN NaN
9 66.0 56.0 59.0 56.0 98.0 84 NaN NaN NaN NaN
0 NaN NaN NaN NaN NaN 59 56.0 61.0 57.0 54.0
1 NaN NaN NaN NaN NaN 72 53.0 74.0 53.0 51.0
2 NaN NaN NaN NaN NaN 65 93.0 83.0 96.0 79.0
3 NaN NaN NaN NaN NaN 95 56.0 50.0 85.0 97.0
4 NaN NaN NaN NaN NaN 95 70.0 57.0 70.0 52.0
5 NaN NaN NaN NaN NaN 50 92.0 76.0 66.0 88.0
6 NaN NaN NaN NaN NaN 81 85.0 80.0 54.0 51.0
7 NaN NaN NaN NaN NaN 65 62.0 60.0 77.0 79.0
8 NaN NaN NaN NaN NaN 53 81.0 66.0 87.0 59.0
9 NaN NaN NaN NaN NaN 59 94.0 57.0 95.0 55.0
横向拼接
>>> df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
>>> df1
A B C D E F
0 75 68 84 82 77 62
1 65 50 95 79 87 98
2 64 56 79 83 85 91
3 98 67 90 60 81 93
4 79 66 91 66 94 81
5 64 56 91 85 99 88
6 77 53 58 73 52 85
7 76 82 54 92 81 81
8 79 66 69 83 79 54
9 99 62 76 95 74 63
>>> df2=pd.DataFrame(np.random.randint(50,100,(10,5)),columns=['F',"M",'N','X','Y'])
>>> df2
F M N X Y
0 93 68 87 87 63
1 96 93 79 88 73
2 69 62 81 75 89
3 52 57 88 96 76
4 80 51 85 61 74
5 94 87 59 79 86
6 74 76 71 59 95
7 80 81 55 61 59
8 95 63 72 57 85
9 76 88 83 80 95
>>> # pd.merge(df1,df2,on="F",how="inner")
>>>
>>> pd.concat([df1,df2],axis=1)
A B C D E F F M N X Y
0 75 68 84 82 77 62 93 68 87 87 63
1 65 50 95 79 87 98 96 93 79 88 73
2 64 56 79 83 85 91 69 62 81 75 89
3 98 67 90 60 81 93 52 57 88 96 76
4 79 66 91 66 94 81 80 51 85 61 74
5 64 56 91 85 99 88 94 87 59 79 86
6 77 53 58 73 52 85 74 76 71 59 95
7 76 82 54 92 81 81 80 81 55 61 59
8 79 66 69 83 79 54 95 63 72 57 85
9 99 62 76 95 74 63 76 88 83 80 95
三、多级索引
先来解释下多级索引:多级索引也称为层次化索引(hierarchical indexing),是指数据在一个轴上(行或者列)拥有多个(两个以上)索引级别。之所以引入多级索引,在于它可以使用户能以低维度形式处理高维度数据。
pandas 的多级索引,主要是通过 pd.MultiIndex的方法来创建的,具体创建方式有三种,我们介绍其中的两种类型 from_product、from_tuples
3.1、from_product
from_product主要有两个参数list1和list2
MultiIndex.from_product:
mul_col = pd.MultiIndex.from_product([[list1,list2])
该方法用于创建list1*list2的2级索引,list1为1级,list2为2级
下面我们来实际看一下:
>>> df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
>>> df1
A B C D E F
0 74 75 85 60 94 59
1 93 69 64 66 80 88
2 94 73 60 80 68 67
3 50 87 95 69 70 78
4 81 65 63 93 61 50
5 92 89 65 92 52 72
6 61 50 76 57 82 64
7 70 65 53 57 74 70
8 99 69 53 69 63 78
9 60 66 89 54 90 94
>>> col=pd.MultiIndex.from_product([["A","B"], ['x','y','z']])
>>> col
MultiIndex([('A', 'x'),
('A', 'y'),
('A', 'z'),
('B', 'x'),
('B', 'y'),
('B', 'z')],
)
>>> df1.columns=col
>>> df1
A B
x y z x y z
0 74 75 85 60 94 59
1 93 69 64 66 80 88
2 94 73 60 80 68 67
3 50 87 95 69 70 78
4 81 65 63 93 61 50
5 92 89 65 92 52 72
6 61 50 76 57 82 64
7 70 65 53 57 74 70
8 99 69 53 69 63 78
9 60 66 89 54 90 94
多级列表2
>>> df1
考试1 考试2 考试3 考试4 考试5 考试6
0 63 93 50 86 81 99
1 75 73 87 77 66 60
2 98 58 79 62 91 74
3 81 92 57 64 54 61
4 81 96 81 61 73 97
5 64 91 75 82 90 90
6 58 86 55 56 87 52
7 71 89 71 90 77 97
8 80 71 55 78 81 81
9 68 74 54 63 54 88
>>> # col=pd.MultiIndex.from_product([["A","B"], ['x','y','z']])
>>> # col
>>> # df1.columns=col
>>> # df1
>>>
>>> index=pd.MultiIndex.from_product([["小明","小龙"],["科目1","科目2","科目3","科目4","科目5"]],names=["姓名","科目"])
>>> df1.index=index
>>> df1
考试1 考试2 考试3 考试4 考试5 考试6
姓名 科目
小明 科目1 63 93 50 86 81 99
科目2 75 73 87 77 66 60
科目3 98 58 79 62 91 74
科目4 81 92 57 64 54 61
科目5 81 96 81 61 73 97
小龙 科目1 64 91 75 82 90 90
科目2 58 86 55 56 87 52
科目3 71 89 71 90 77 97
科目4 80 71 55 78 81 81
科目5 68 74 54 63 54 88
3.2、from_tuples
from_tuples的格式大概如下,my_tup是一个list,list的每一个数据都是一个tuple,因此叫 from_tuples
pd.MultiIndex.from_tuples([list], names = ['Obj', 'time'])
pd.MultiIndex.from_tuples
pd.MultiIndex.from_tuples(my_tup, names = ['Obj', 'time'])
my_tup是个list,里面包含多级索引信息,以tuple中的第一个值为1级,第二个值为2级
案例如下:
>>> my_index = pd.MultiIndex.from_tuples(my_tup, names = ['Obj', 'time'])
>>> pd.DataFrame(np.random.randint(60,100, (4,3)),
... index = my_index,
... columns = [*'ABC'])
A B C
Obj time
Python 期中 71 92 71
期末 87 98 73
Java 期中 73 62 76
期末 94 93 84
>>>
四、数据透视
在 pandas中,进行数据透视的主要方法是 pivot_table
pivot_table(data, # DataFrame
values=None, # 值
index=None, # 分类汇总依据
columns=None, # 列
aggfunc='mean', # 聚合函数
fill_value=None, # 对缺失值的填充
margins=False, # 是否启用总计行/列
dropna=True, # 删除缺失
margins_name='All' # 总计行/列的名称
)
由于本人时间的缘故,就先写到此,详细了了解pandas 的数据透视操作,参考 链接
本文全部代码
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
df
筛选
loc
df.loc[:,"A"]
df.loc[df['A']==55] #取A列都是55的行数据
df.loc[:,['A','B']] #取A B两列的数据
df.loc[(df['B']==99)&(df['C']==90)] #注意细节,这里需要加(),否则会报错
iloc
为了方便记忆,记住i是integer的意思。iloc的列参数只能是整数;loc的列参数不能是整数。这是本质区别。注意,这里所指的是列参数。
df.iloc[0,:]
连接
df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
df1
df2=pd.DataFrame(np.random.randint(50,100,(10,5)),columns=['F',"M",'N','X','Y'])
df2
pd.merge(df1,df2,on="F",how="inner")
pd.concat([df1,df2],axis=1)
多级索引
df1=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['考试1',"考试2",'考试3','考试4','考试5','考试6'])
df1
col=pd.MultiIndex.from_product([["A","B"], ['x','y','z']])
col
df1.columns=col
df1
index=pd.MultiIndex.from_product([["小明","小龙"],["科目1","科目2","科目3","科目4","科目5"]],names=["姓名","科目"])
df1.index=index
df1
my_tup = [('Python', '期中'),('Python', '期末'),('Java', '期中'),('Java', '期末')]
my_index = pd.MultiIndex.from_tuples(my_tup, names = ['Obj', 'time'])
pd.DataFrame(np.random.randint(60,100, (4,3)),
index = my_index,
columns = [*'ABC'])
本文参考了以下链接
https://blog.csdn.net/brucewong0516/article/details/82707492
https://blog.csdn.net/qq_21840201/article/details/80727504
https://blog.csdn.net/zzpdbk/article/details/79232661
https://blog.csdn.net/anshuai_aw1/article/details/83510345
https://www.jianshu.com/p/d30fdfbeb312
https://www.cnblogs.com/shanger/p/13245669.html
https://www.cnblogs.com/onemorepoint/p/8425300.htmlOriginal: https://blog.csdn.net/qq_42105477/article/details/121046844
Author: 水木工南
Title: pandas常用技巧:筛选、拼接、多级索引、数据透视
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674401/
转载文章受原作者版权保护。转载请注明原作者出处!