

嗨害大家好鸭~我是小熊猫❤🥩
天冷还是应该吃烤肉大老远跑过去很值得
降温就要吃烤肉啊 滋辣滋辣的声音特别好听~
快乐周六吃烤肉果然是快乐的~ ~~
天冷了,逛街……
天冷了,吃烤肉……
天冷了,喝奶茶……
有温度的冬天,才暖暖的🥩


为了造福”烤肉控”们,今天就用Python爬取一座城市的烤肉店数据,选出最适合的一家
; 准备工作🥩
环境
- python 3.6
- pycharm
- requests >>> 发送请求 pip install requests
- csv >>> 保存数据

; 了解爬虫最基本的思路🥩
一. 数据来源分析🍖
- 确定我们爬取的内容是什么?
爬取店铺数据
2. 去找这些东西是从哪里来的
通过开发者工具进行抓包分析, 分析数据来源
二. 代码实现过程🍖
- 发送请求, 对于找到数据包发送请求
- 获取数据, 根据服务器给你返回的response数据来的
- 解析数据, 提取我们想要的内容数据
- 保存数据, 保存到csv文件
- 多页爬取, 根据url地址参数变化
代码实现过程🥩
1. 发送请求🍻
url = 'https://平台原因不能放'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': 32,
'cateId': '-1',
'q': '烤肉',
,
}
headers = {
'Referer': 'https://平台原因/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
200 表示请求成功 状态码 403 你没有访问权限
2. 获取数据🍻
print(response.json())
3. 解析数据🍻
result = response.json()['data']['searchResult']
for index in result:
index_url = f'https://www.平台原因自己打/meishi/{index["id"]}/'
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
4. 保存数据🍻
f = open('烤肉数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader()
5.翻页🍻
for page in range(0, 1025, 32):
url = 'https://平台原因不能放.....group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
}
运行代码得到数据🥩

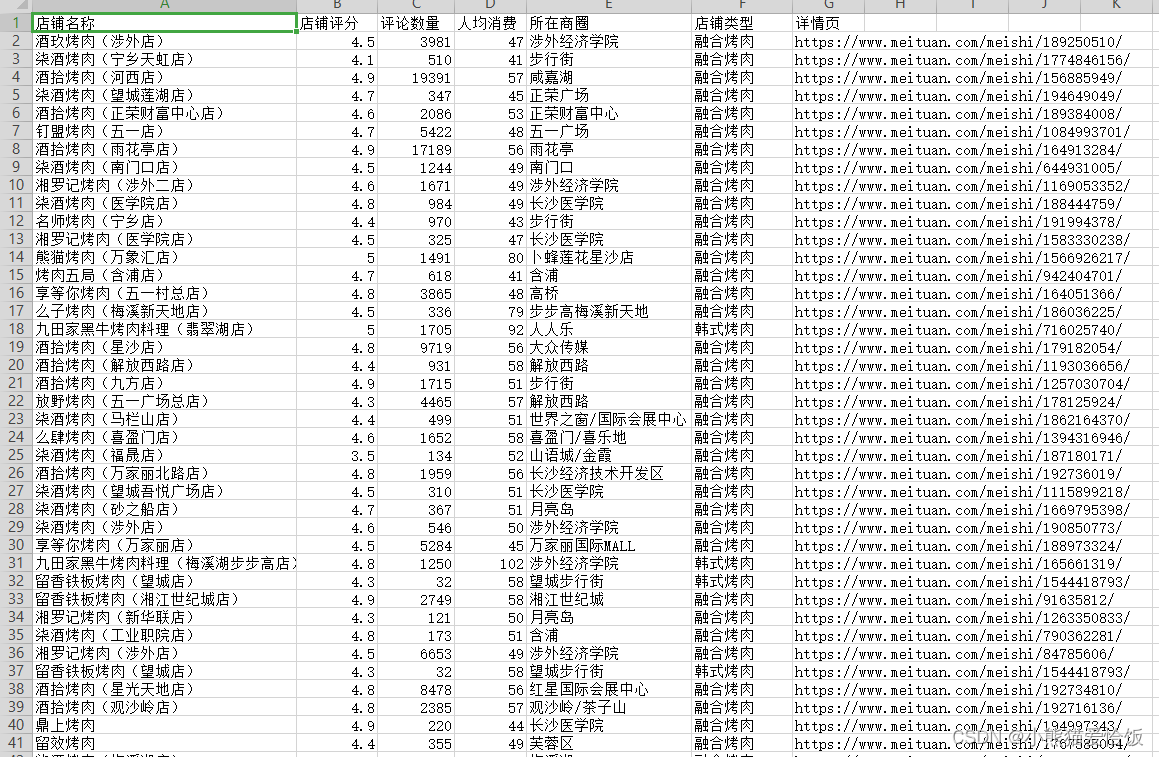
; 完整代码🥩
f = open('烤肉数据1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader()
for page in range(0, 1025, 32):
url = 'https://平台原因不能放'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
}
headers = {
'Referer': 'https://chs.平台原因不能放.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
result = response.json()['data']['searchResult']
for index in result:
index_url = f'https://平台原因不能放/meishi/{index["id"]}/'
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
终于敲完了…
给我馋得…我等下就下去吃肉嘿嘿~ ~ ~
我是小熊猫,咱下篇文章再见啦(✿◡‿◡)

Original: https://blog.csdn.net/m0_67575344/article/details/127319432
Author: 小熊猫爱恰饭
Title: 天冷就要大口吃肉肉~python采集周边烤肉店数据【附代码】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/673508/
转载文章受原作者版权保护。转载请注明原作者出处!