

对经典问题 波士顿房价进行回归预测
交流学术思想,加入Q群 号:815783932
一、加载波士顿数据集并观察数据的shape。
from sklearn.model_selection import train_test_split
def del_data():
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
print(train_data.shape)
print(train_targets.shape)
print(test_data.shape)
print(test_targets.shape)
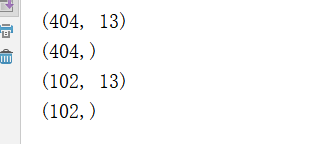

由图像可知道,波士顿训练集的房价特征集是404个 13个维度的特征集,测试集为102。
二、xgboost回归是否需要归一化
答案:否,xgboos底层还是根据决策树去做的,是通过最优分裂点进行优化的。和树有关的决策算法过程是不需要进行归一标准化的。
三、xgboost可调节参数
答案:任何一个机器学习的算法中都存在自己的Parameters,参数集可以调节。
XGboost的管方文档 对于python的 api调用接口可以看下方的网址:
https://xgboost.readthedocs.io/en/latest/python/python_api.html
参数名解释含义max_depth-基本学习器的最大树深度, 通过这个值避免过拟合,默认值是6learning_rate-学习率,评价训练的速度,若值设置过低学习慢,设置低影响迭代最优值n_estimators-决策树的数量,这些都是决定过拟合和欠拟合objective-基于此函数去进行求解最优化回归树gamma-惩罚项系数,指定节点分裂所需的最小损失函数下降值alpha-L1正则化系数……-……
从官方文档中能看到可以调节的参数有非常的多,但是在实际试验中,调用算法 除了较为重要的一些参
数可以采用网格搜索的方法进行调参,其他系数,若没有强大的数学功底和理解底层的思想,用默认的
参数就是最有的解。
max_depth,learning_rate,n_estimators 是可以调节的参数。
四、下面是代码实现的过程
from sklearn.metrics import mean_squared_error
import xgboost as xgb
from keras.datasets import boston_housing
def main():
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
model = xgb.XGBRegressor(max_depth=6,learning_rate=0.05,n_estimators=100,randam_state=42)
model.fit(train_data,train_targets)
test_predict=model.predict(test_data)
train_predict = model.predict(train_data)
msetest=mean_squared_error(test_targets,test_predict)
msetrain=mean_squared_error(train_targets,train_predict)
print(msetest)
print(msetrain)
print(test_targets)
print(abs(test_predict-test_targets))
model 是构建的模型。通过对训练集的学习来做对未来的预测。
msetest,msetrain是你自己的评估结果 可以通过这两个值来判断你的模型构建是否优秀 。
msetest 是模型对测试集预测得到结果的mse值, msetrain 是模型对训练集预测得到结果的mse值。
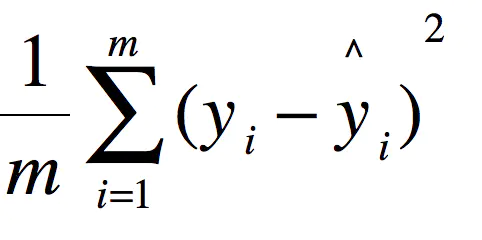

由此能看出,在训练集表现的非常好,测试集表现还比较差。需要通过优化模型来进行调参。这里我就
不做累述去调参,后期会更新如何调参的文章,这篇主要是说原理。
五、原理通俗解释。
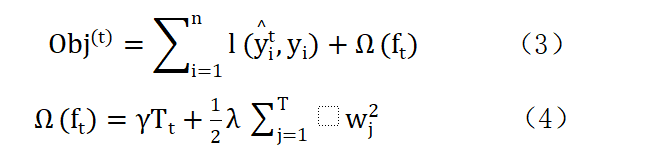
obj是目标函数 ,整个算法就是通过最优化这个目标函数来实现的。
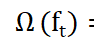
这个是正则项为了防止模型的复杂度,抑制模型复杂度。
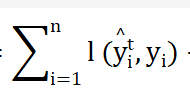
这个的优化,本算法采取已知第t-1步回归树的形成,去推导第t步回归树的形成,进而可以优化目标函数。
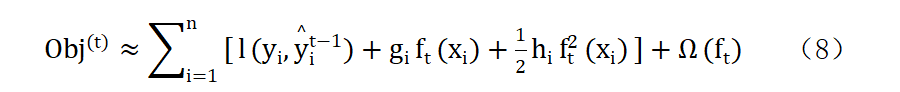
优化到这样的形式,具体也可以看官方文档和论文讲的非常详细,我就是从简单理解和实现的角度去讲述。
最终的展示结果为
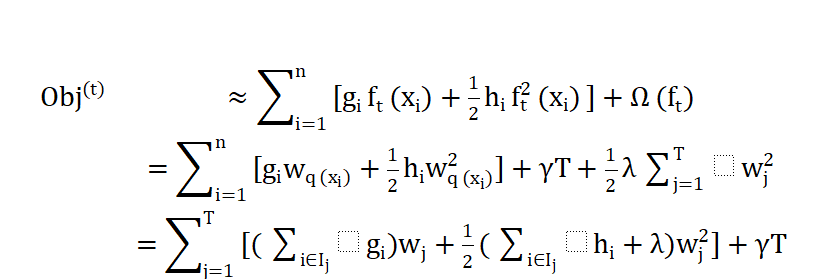
六、简单理解
其实就是根据决策树的思想将n个样例m个特征,划分每一个特征的回归决策树,找到最优点进行分割,最终得到n个样例m个特征的最优划分点。由最初迭代至最终的算法。
整体的思路框架大概就是这样的。欢迎讨论
文章不易 希望能够。。。。。。。。。。。。

Original: https://blog.csdn.net/weixin_47324594/article/details/120819585
Author: 普普通通研究生学代码
Title: python XGboost回归预测 算法实现和原理讲解(比赛青睐)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/671158/
转载文章受原作者版权保护。转载请注明原作者出处!