

文章目录
描述: 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
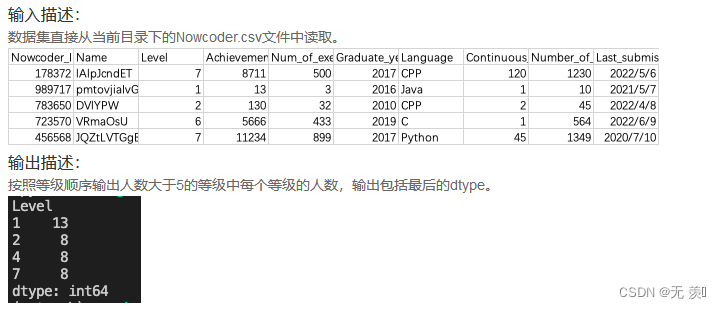
产品经理小X同学想要分析一下用户的等级数据,他想知道在人数大于5的条件下,各个等级都分别有多少人?

实现代码:
import pandas as pd
df = pd.read_csv('Nowcoder.csv', sep=',')
print(df.groupby(['Level']).Nowcoder_ID.count()>5)
运行结果:
- 统计运动会项目报名人数
描述: 某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
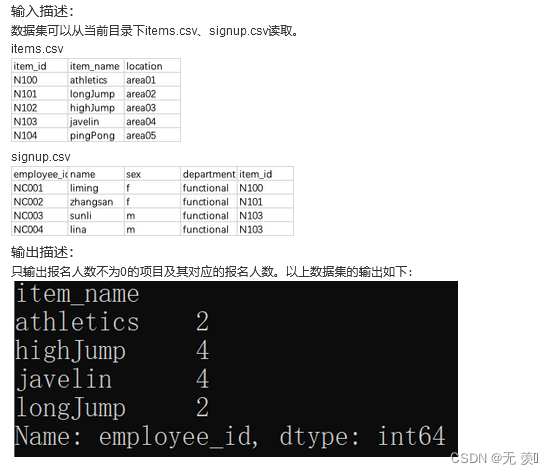
请你统计各类型项目的报名人数。
实现代码:
import pandas as pd
signup = pd.read_csv('signup.csv')
items = pd.read_csv('items.csv')
new = signup.merge(items,on='item_id')
t = new.groupby('item_name')['employee_id'].count()>0
print(t)
运行结果:
- 统计运动会项目报名人数(二)
描述: 某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
请你统计各类型项目的报名人数。
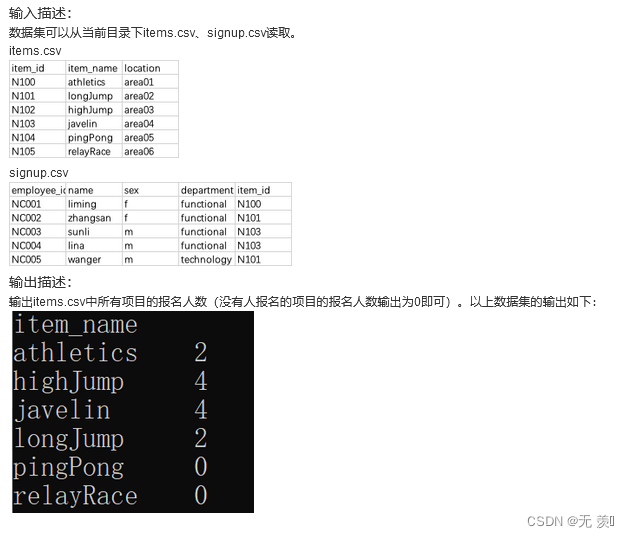
实现代码:
import pandas as pd
signup = pd.read_csv('signup.csv')
items = pd.read_csv('items.csv')
data = pd.merge(items, signup, on='item_id', how='left')
cnt = data.groupby(by='item_name')['employee_id'].count()
print(cnt)
运行结果:
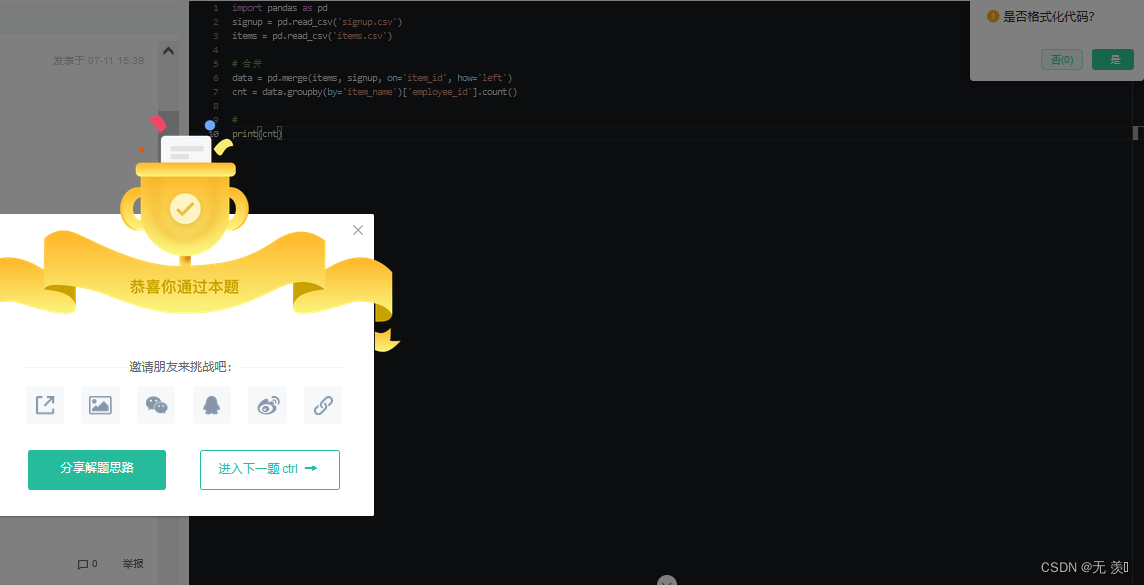
- 多报名表的运动项目人数统计
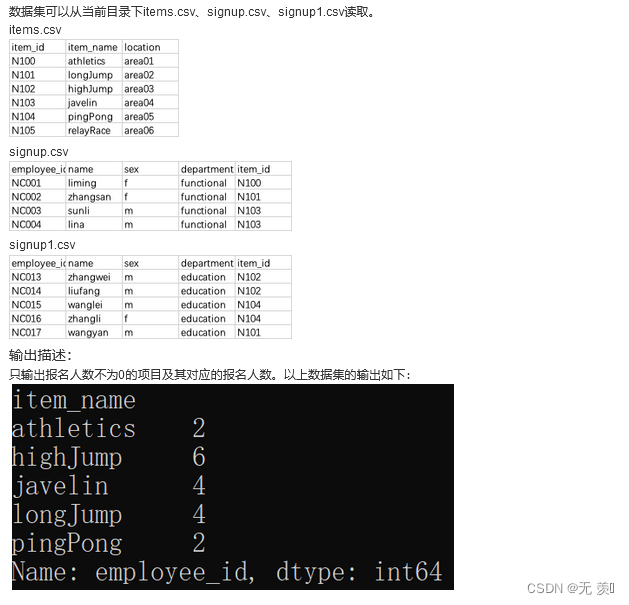
描述: 某公司计划举办一场运动会,现有部分运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id。
另有signup1.csv,是education部门的报名情况,包含字段同signup.csv。
请你将signup.csv与signup1.csv的数据集合并后,统计各类型项目的报名人数。
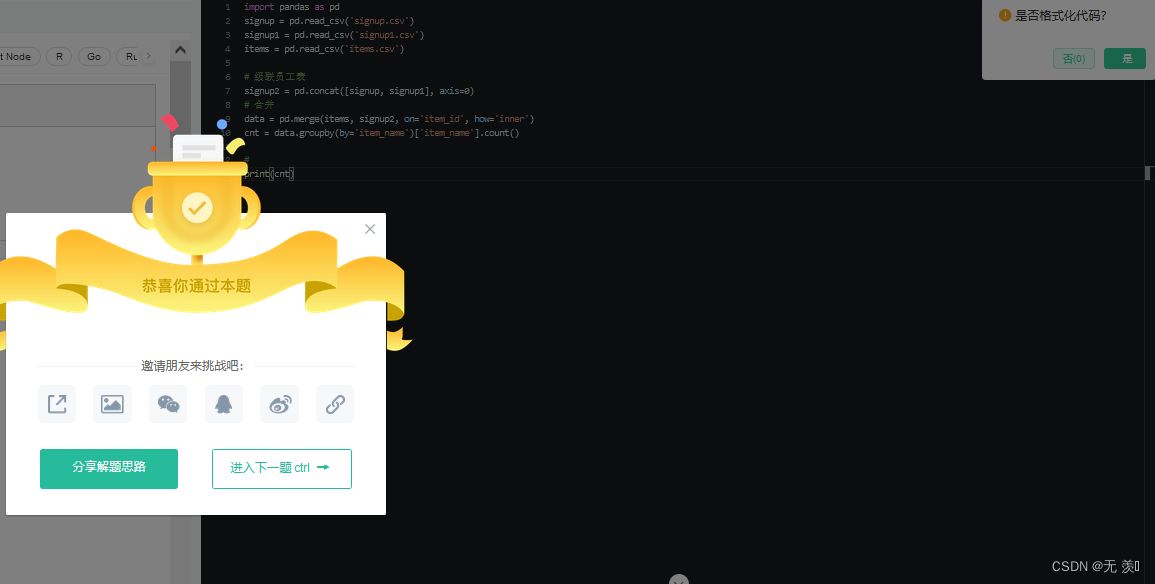
实现代码:
import pandas as pd
signup = pd.read_csv('signup.csv')
signup1 = pd.read_csv('signup1.csv')
items = pd.read_csv('items.csv')
signup2 = pd.concat([signup, signup1], axis=0)
data = pd.merge(items, signup2, on='item_id', how='inner')
cnt = data.groupby(by='item_name')['item_name'].count()
print(cnt)
运行结果:
《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等

Original: https://blog.csdn.net/yuan2019035055/article/details/127224124
Author: 无 羡ღ
Title: Python每日一练(牛客机器学习新题库)——第40天:鸢尾花分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/668502/
转载文章受原作者版权保护。转载请注明原作者出处!