

文章目录
- 一、SIFT算法
* - 1.1什么是SIFT算法?
- 1.2SIFT算法特点
- 二、SIFT算法实质
* - 2.1SIFT算法实现特征匹配主要有以下三个流程:
- 三、SIFT算法原理
* - 3.1图像金字塔
- 3.2创建图像高斯金字塔
- 3.3高斯金字塔创建总图
- 四、尺度空间
- 五、高斯差分金字塔
* - 5.1极值点(Key points)的精确定位
- 5.2确定关键点(极值点)方向
- 5.3关键点描述
- 5.4关键点匹配
- 六、sift代码
- 七、总结
一、SIFT算法
1.1什么是SIFT算法?
尺度不变特征转换(SIFT, Scale Invariant Feature Transform)是图像处理领域中的一种局部特征描述算法. 该方法于1999年由加拿大教授David G.Lowe提出,申请了专利,其专利属于英属哥伦比亚大学. SIFT专利在2020年3月17日之后到期,现在只需更新cv版本即可免费使用.
SIFT算法不仅只有尺度不变性,当旋转图像,改变图像亮度,移动拍摄位置时,仍可得到较好的检测效果.
其实,在我们生活中,SIFT算法还是有所应用的,比如,我们手机上的全景拍摄,当我们拿着手机旋转拍摄时,就可以得到一幅全景图,大家想过没有,手机摄像头的视角是确定的,为什么通过旋转拍摄时,角度就变大了呢?其实角度并没有变化,只是我们在旋转拍摄时,拍摄了很多的图像,这些图像相邻之间有重叠部分,把这些图像合在一起,去除重叠部分,就可以得到一幅全景图啦.
1.2SIFT算法特点
- 具有较好的 稳定性和不变形,能够适当旋转、尺度缩放、亮度的变化,能在一定程度上不受视角变化、仿射变换、噪声的干扰。
- 区分性好,能够在海量特征数据库中进行快速准确的区分信息进行匹配
- 多属性,就算只有单个物体,也能产生大量特征向量
- 高速性,能够快速的进行特征向量匹配
- 可扩展性,能够与其它形式的特征向量进行联合
二、SIFT算法实质
在不同的尺度空间上查找关键点,并计算出关键点的方向。
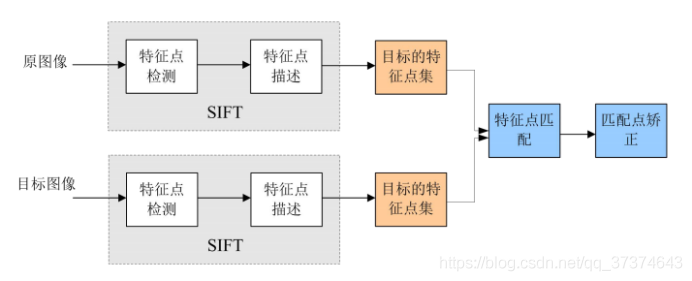

; 2.1SIFT算法实现特征匹配主要有以下三个流程:
- 提取关键点:关键点是一些十分突出的不会因光照、尺度、旋转等因素而消失的点,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。此步骤是搜索所有尺度空间上的图像位置。通过高斯微分函数来识别潜在的具有尺度和旋转不变的兴趣点。
- 定位关键点并确定特征方向:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。然后基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 通过各关键点的特征向量,进行两两比较找出相互匹配的若干对特征点,建立景物间的对应关系。
三、SIFT算法原理
3.1图像金字塔
图像金字塔是一种以多分辨率来解释图像的结构,通过对原始图像进行多尺度像素采样的方式,生成N个不同分辨率的图像。把具有最高级别分辨率的图像放在底部,以金字塔形状排列,往上是一系列像素(尺寸)逐渐降低的图像,一直到金字塔的顶部只包含一个像素点的图像,这就构成了传统意义上的图像金字塔。
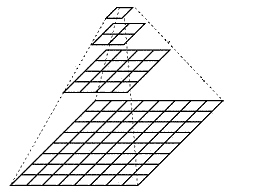
获得图像金字塔一般包括二个步骤:
- 利用低通滤波器平滑图像
- 对平滑图像进行抽样(采样)
有两种采样方式——上采样(分辨率逐级升高)和下采样(分辨率逐级降低)
上采样:

下采样:

; 3.2创建图像高斯金字塔
什么是图像高斯金字塔?
在说高斯金字塔之前,我们先来说一下人的眼睛,我们人眼对世界的感知有两种特性:一是近大远小:同一物体,近处看时感觉比较大,远处看时感觉比较小;二是”模糊”:更准确说应该是”粗细”,我们看近处,可以看到物体的细节(人会觉得比较清楚),比如一片树叶,近看可以看到该树叶的纹理,远处看只能看到该片的大概轮廓(人会觉得比较模糊). 从频率的角度出发,图像的细节(比如纹理,轮廓等)代表图像的高频成分,图像较平滑区域表示图像的低频成分.
图像高斯金字塔实际上是一种图像的尺度空间(分线性和非线性空间,此处仅讨论线性空间),尺度的概念用来模拟观察者距离物体的远近程度,在模拟物体远近的同时,还得考虑物体的粗细程序.
综上,图像的尺度空间是模拟人眼看到物体的远近程度以及模糊程度.
图像高斯金字塔就考虑了这两个方面:① 图像的远近程度;② 图像的模糊程度(理解为粗细更好).
那该怎么模拟图像的远近程度呢?
采样法(上采样,下采样)
比如一幅图像,对于每一行,隔一个像素点取一个像素点,那么最后得到的图像就是原图像的行和列各1/2. 这属于下采样的一种.
那该怎么模拟图像的粗细程序呢?
采用高斯核对图像进行平滑处理,因为高斯卷积核是实现尺度变换的唯一线性核.
上面,我们从一个感性的角度去理解高斯金字塔的形成过程,现在我们来理性分析高斯金字塔的创建过程。
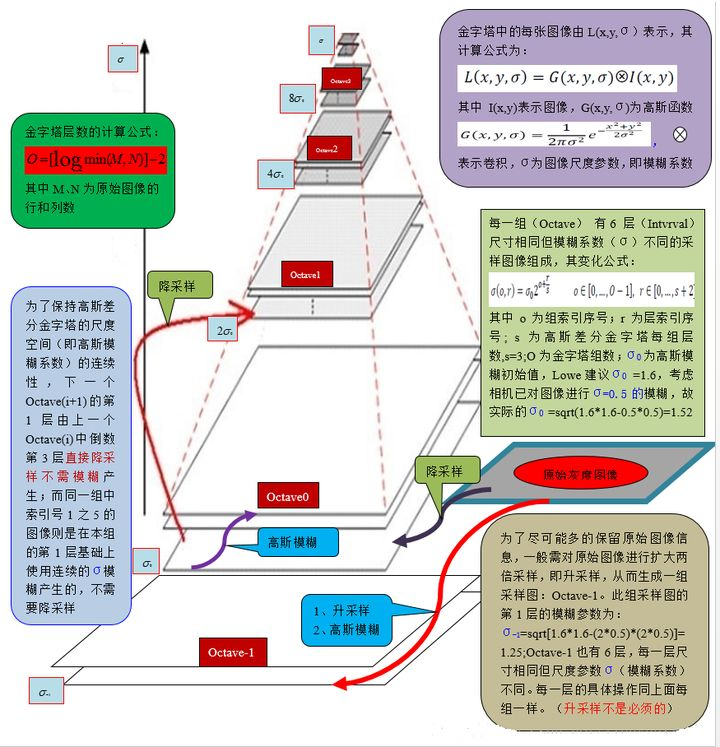
高斯金字塔式在Sift算子中提出来的概念,首先高斯金字塔并不是一个金字塔,而是有很多组(Octave)金字塔构成,并且每组金字塔都包含若干层(Interval)。
高斯金字塔构建过程:
- 先将原图像扩大一倍之后作为高斯金字塔的第1组第1层,将第1组第1层图像经高斯卷积(其实就是高斯平滑或称高斯滤波)之后作为第1组金字塔的第2层,高斯卷积函数为:
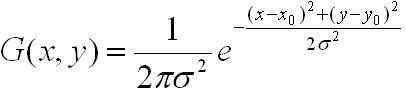
对于参数σ,在Sift算子中取的是固定值1.6。 - 将σ乘以一个比例系数k,等到一个新的平滑因子σ=k*σ,用它来平滑第1组第2层图像,结果图像作为第3层。
- 如此这般重复,最后得到L层图像,在同一组中,每一层图像的尺寸都是一样的,只是平滑系数不一样。它们对应的平滑系数分别为:0,σ,kσ,k2σ,k3σ……k^(L-2)σ。
- 将第1组倒数第三层图像作比例因子为2的降采样,得到的图像作为第2组的第1层,然后对第2组的第1层图像做平滑因子为σ的高斯平滑,得到第2组的第2层,就像步骤2中一样,如此得到第2组的L层图像,同组内它们的尺寸是一样的,对应的平滑系数分别为:0,σ,kσ,k2σ,k3σ……k^(L-2)σ。但是在尺寸方面第2组是第1组图像的一半。
这样反复执行,就可以得到一共O组,每组L层,共计O*L个图像,这些图像一起就构成了高斯金字塔,结构如下:
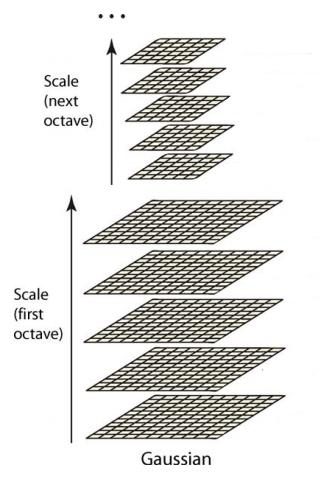
在同一组内,不同层图像的尺寸是一样的,后一层图像的高斯平滑因子σ是前一层图像平滑因子的k倍;
在不同组内,后一组第一个图像是前一组倒数第三个图像的二分之一采样,图像大小是前一组的一半;
高斯金字塔图像效果如下,分别是第1组的4层和第2组的4层:


3.3高斯金字塔创建总图
其中
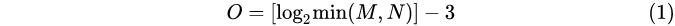
式(1)中,M 为原始图像的行高;N 为原始图像的列宽;O 为图像高斯金字塔的组数.
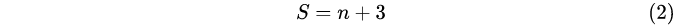
式(2)中,n 为待提取图像特征的图像数;S 为图像高斯金字塔每组的层数.
注:n所代表的意思可能有人不太理解,这里详细说一下.
(1) 假设高斯金字塔每组有S = 5层,则高斯差分金字塔就有S-1 = 4,
那我们只能在高斯差分金字塔每组的中间2层图像求极值(边界是没有极值的),
所以n = 2
(2) 假设高斯金字塔每组有S = 6层,则高斯差分金字塔就有S-1 = 5,
那我们只能在高斯差分金字塔每组的中间3层图像求极值,所以n = 3
(3) 假设高斯金字塔每组有S = 7层,则高斯差分金字塔就有S-1 = 6,
那我们只能在高斯差分金字塔每组的中间4层图像求极值,所以n = 4
为了方便计算,从0开始记录组数或层数
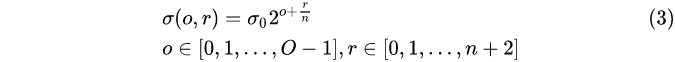
(3)中,o 为组索引序号,r 为层索引序号,σ (o, r ) 为对应的图像的高斯模糊系数.
σ 0 σ_0 σ0 为高斯模糊初始值,David G.Lowe 教授刚开始设置为1.6,考虑相机实际已对图像进行σ=0.5的模糊处理,故实际:
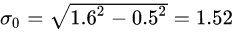
通过式(3),可以计算对应图像金字塔中的高斯模糊系数,如下:
第0组,第0层:
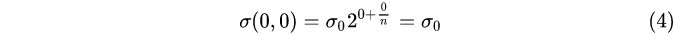
第0组,第1层:
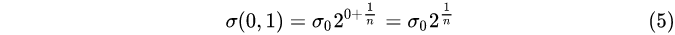
第0组,第2层:
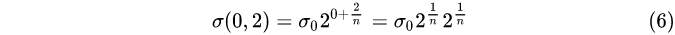
…
…
第1组,第0层:
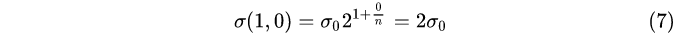
第1组,第1层:
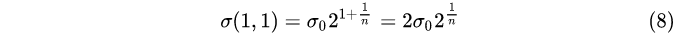
第1组,第2层:
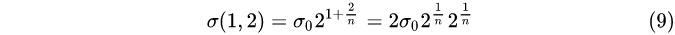
…
…
第2组,第0层:
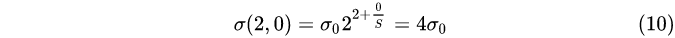
第2组,第1层:
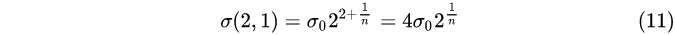
第2组,第2层:
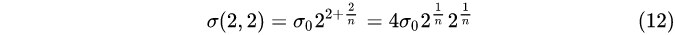
…
…
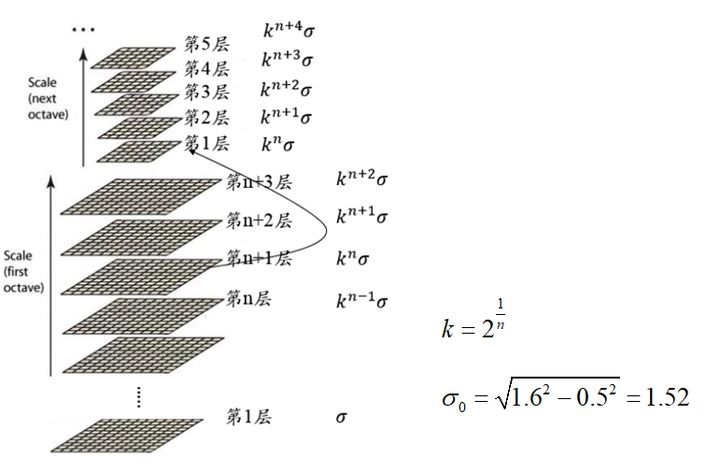
由上述计算,我们知道
① 每一组内,相邻层之间的高斯模糊系统相差 2 1 / n 2^{1/n}2 1 /n;
② 第0组第0层,第1组第第0层,第2组第0层,…,的高斯模糊系数分别为σ 0 , 2 σ 0 , 4 σ 0 , . . . σ_0,2σ_0,4σ_0,…σ0 ,2 σ0 ,4 σ0 ,… ;
③ 下一组的第0层为上一组倒数第3层降采样所得,无须进行高斯模糊操作.
总的过程,如图2所示:
四、尺度空间
图像的尺度空间解决的问题是如何对图像在所有尺度下描述的问题。
在高斯金字塔中一共生成O组L层不同尺度的图像,这两个量合起来(O,L)就构成了高斯金字塔的尺度空间,也就是说以高斯金字塔的组O作为二维坐标系的一个坐标,不同层L作为另一个坐标,则给定的一组坐标(O,L)就可以唯一确定高斯金字塔中的一幅图像。
尺度空间的形象表述:
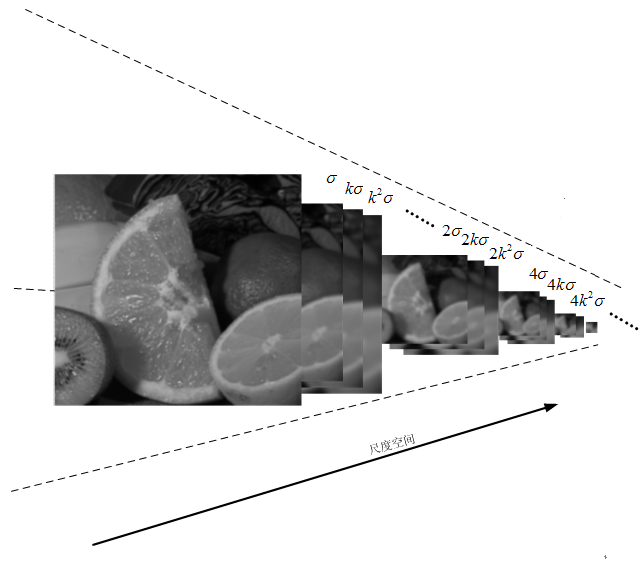
上图中尺度空间中k前的系数n表示的是第一组图像尺寸是当前组图像尺寸的n倍
; 五、高斯差分金字塔
创建好图像高斯金字塔后,每一组内的相邻层相减可以得到高斯差分金字塔(DoG, Difference of Gaussian),是后期检测图像极值点的前提,如图2所示:
DOG金字塔的第1组第1层是由高斯金字塔的第1组第2层减第1组第1层得到的。以此类推,逐组逐层生成每一个差分图像,所有差分图像构成差分金字塔。概括为DOG金字塔的第o组第l层图像是有高斯金字塔的第o组第l+1层减第o组第l层得到的。
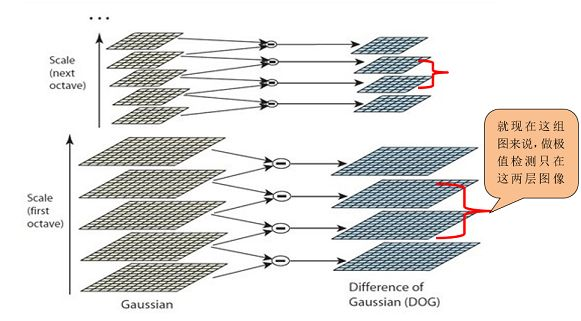
每一组在层数上,DOG金字塔比高斯金字塔少一层。后续Sift特征点的提取都是在DOG金字塔上进行的。
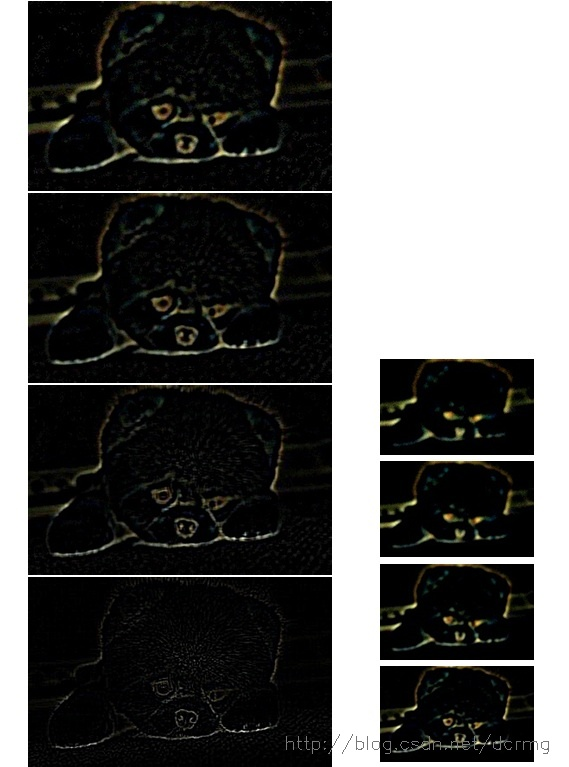
DOG金字塔的显示效果如下:
下边对这些DOG图像进行归一化,可有很明显的看到差分图像所蕴含的特征,并且有一些特征是在不同模糊程度、不同尺度下都存在的,这些特征正是Sift所要提取的”稳定”特征:
5.1极值点(Key points)的精确定位
阈值化
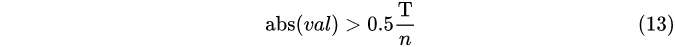
其中,T = 0.04,可人为设定其值;n为待提取特征的图像数;abs(val)为图像的像素值. 设定像素阈值,为了去除一些噪点或其它一些不稳定像素点.
在高斯差分金字塔中寻找极值点
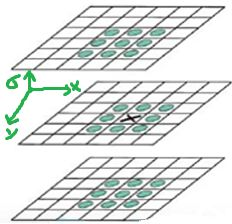
特征点是由DOG空间的局部极值点组成的。为了寻找DoG函数的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。
如下图所示:在高斯差分金字塔中寻找极值点,除了考虑x,y方向的点,还要考虑σ 方向的点,所以判断一个像素点是否为极值点,要与周围的26个点进行比较.
注:
① 如果高斯差分金字塔每组有3层,则只能在中间1层图像寻 找极值点,
两端的图像不连续,没有极值点.
② 如果高斯差分金字塔每组有5层,则只能在中间3层图像寻找极值点.
依此类推…
当我们检测到极值点之后,会发现一个问题,高斯差分金字塔是离散的(因为尺度空间和像素点都是离散的),所以找到的极值点不太准确的,很大可能在真正极值点附近,如图4所示,为了找到更高亚像素位置精度的极值点,需利用泰勒展开式.
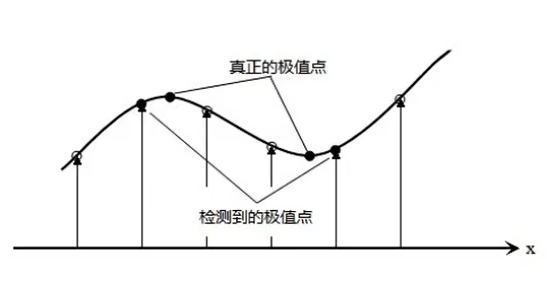
更正极值点位置
在检测到的极值点处,作三元二阶泰勒展开:
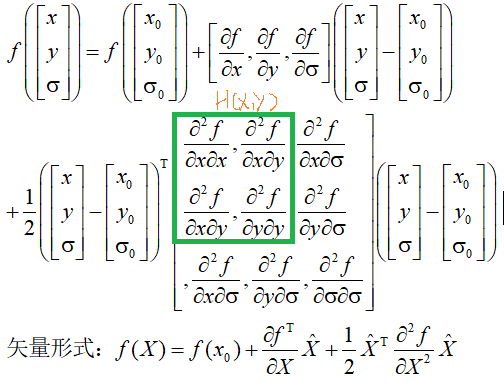
f(x)对x进行求导:
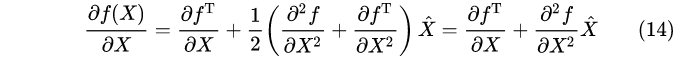
令导数为零
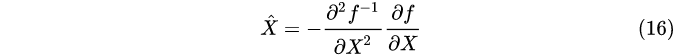
带入f(x),可得
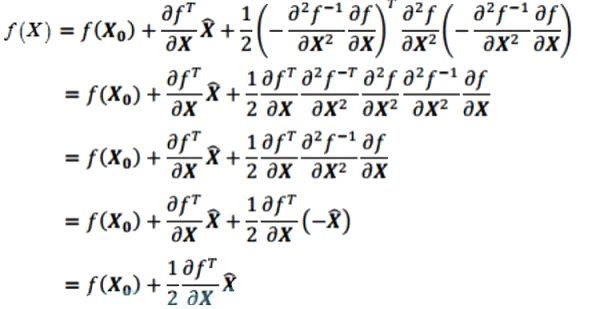
注:
上述求解的结束标志:达到一定的迭代次数.
求解亚像素精度极值点时,当所得解超出离散极值点一定范围舍去,
因为泰勒展开只是在离散点附近能够较好的拟合原函数.
舍去低对比度的点
若|f(x)|
Original: https://blog.csdn.net/weixin_48167570/article/details/123704075
Author: Tc.小浩
Title: 全网最详细SIFT算法原理实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/668061/
转载文章受原作者版权保护。转载请注明原作者出处!