

一、项目背景及意义
AI人工智能一直是近年来热度一直热度不减的话题,我们常在各种科幻电影和小说都能看到它的身影,甚至在现实生活中看见它,对于AI的研究也一直源源不断。这个项目是基于循环神经网络构建一个商品评论分类模型使用的是LSTM就是循环神经网络对评论的情感预测。LSTM模型,是循环神经网络的一种变体,可以很有效的解决简单循环神经网络的梯度爆炸或消失问题。通过对京东小米的评论的训练,能让人工智能辨别出是好评还是差评。通过这个项目,对于人工智能的研究,对于今天和未来有着巨大的意义。
二、主要工作介绍
使用浏览器的开发工具获取京东小米的评论的url分别爬取京东小米商品的好评和差评放到不同的csv表里,然后使用python读取好评和差评并将好评和差评转为dataframe,并给分别每列评论创建一个列名,和打上0和1的标签,方便模型的训练。然后就是分别使用正则表达式去掉一些没必要的符号然后使用结巴分词将评论分成一个一个的词语。接下来就是平衡好评和差评的数量,再将好评和差评进行合并并将数据进行打乱。然后就是给每个词语构建一个索引,然后将索引赋值给评论的词语,使用索引代替在dataframe里的词语,找出最大评论的长度,并统一索引的长度。接下来,就是创建神经网络使用LSTM构建模型,训练模型在再对模型的评估和测试。最后构建一个能够输入评论和判断是好评还是差评的函数。
三、相关技术介绍
使用Requests库(2.27.1)对京东数据进行爬虫并使用time包控制爬取速度防止被封号。
使用Sklearn(0.0.0)对数据进行预处理。
使用tensorflow(2.8.0)机器学习框架对模型进行训练。
使用matplotlib(3.5.1)查看训练精度和损失值。
四、项目实现及展示(重点内容,目的要让别人知道你怎么实现 )
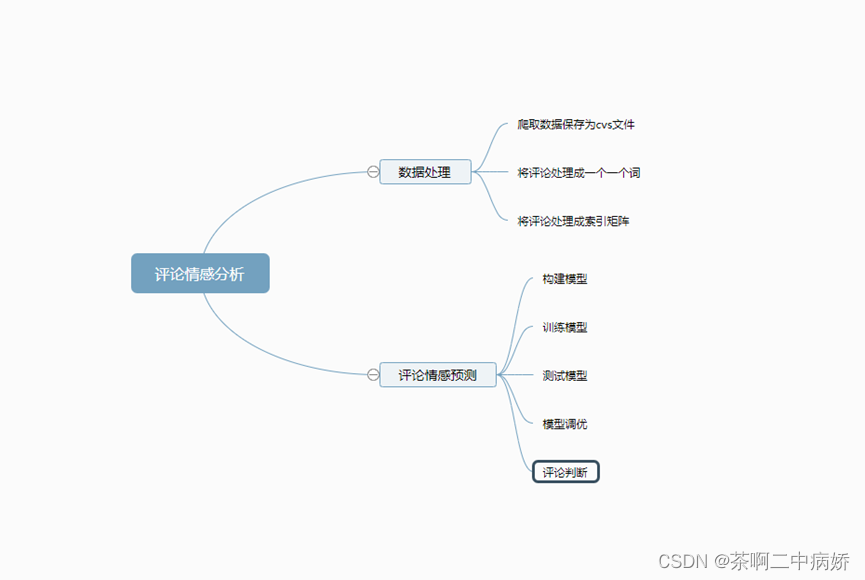

思路图
数据采集
打开浏览器,进入京东官网,搜索小米11手机,按按键F12打开浏览器开发者模式在网络下面名称里找到productPageComments标头查看URL,然后使用python获取url,使用循环得到好评和差评每条评论的json数据,并分别将其保存为csv文件。
图一小米评论的原始json数据
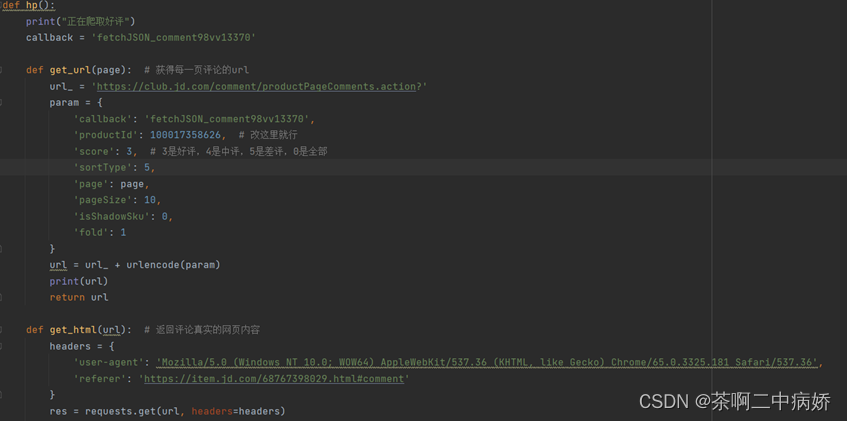
图二爬取京东好评的部分代码
爬取京东评论的代码是分成了两个部分,一个是爬取京东好评的部分,一个是爬取京东差评的部分。只要将param部分的soce更改成差评ur的soce的参数。在循环获取部分加上time.sleep(1)代码控制爬取速度,不然会被京东把ip拉黑。

图三好评csv部分数据
数据处理
接下来就是数据处理环节,导入相关的包,然后使用pd.read_csv将好评和差评分别放入d1和d2两个dataframe里并将给评论创建一个列名,并将没有列名的那一列删掉,仅保存带有列名的那一列。
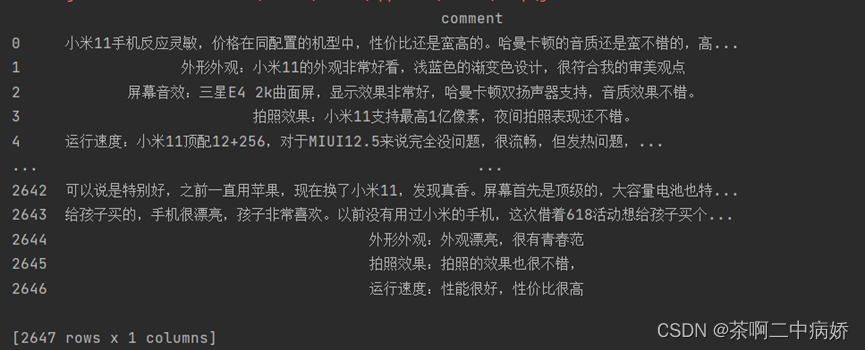
图四好评部分datafarme数据展示
再将好评部分创建一列1,差评部分创建一列0,方便后面识别评论是好评还是发差评,再创建两个列表l1和l2。使用循环分别读取d1和d2的每一条评论然后再使用正则表达式去掉除中文以外的其他数据。再使用结巴分词将其处理成一个一个词,再将这些词放进创建的两个列表里将列表转为dataframe然后将他们与0和1拼接起来将好评和差评弄成一样多列,再将他们打乱顺序,以保
证好评和差评的数量不会差太多。
图五用结巴分词分号并乱序

图六给词语标上索引
图七用索引替换
然后找出最长的评论,并将所有列填充成一样的长度,这是方便弄成一个由索引构成的向量
图八将索引填充成一样长
模型搭建
当得到图八的数据后就可以构建模型了这里使用的是循环神经网络来构建模型,神经元是64个,使用激活函数sigmoid进行编译迭代数15
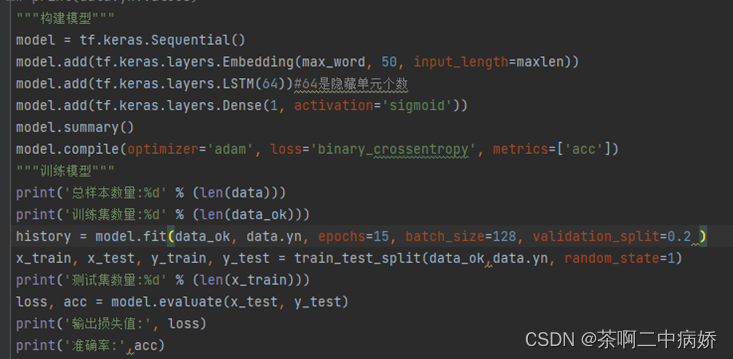
图九模型搭建的代码
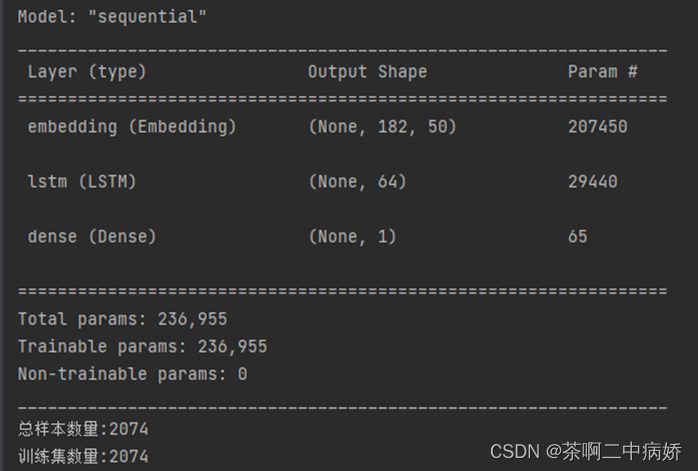
图十模型的参数
接下来就是模型的评估和可视化
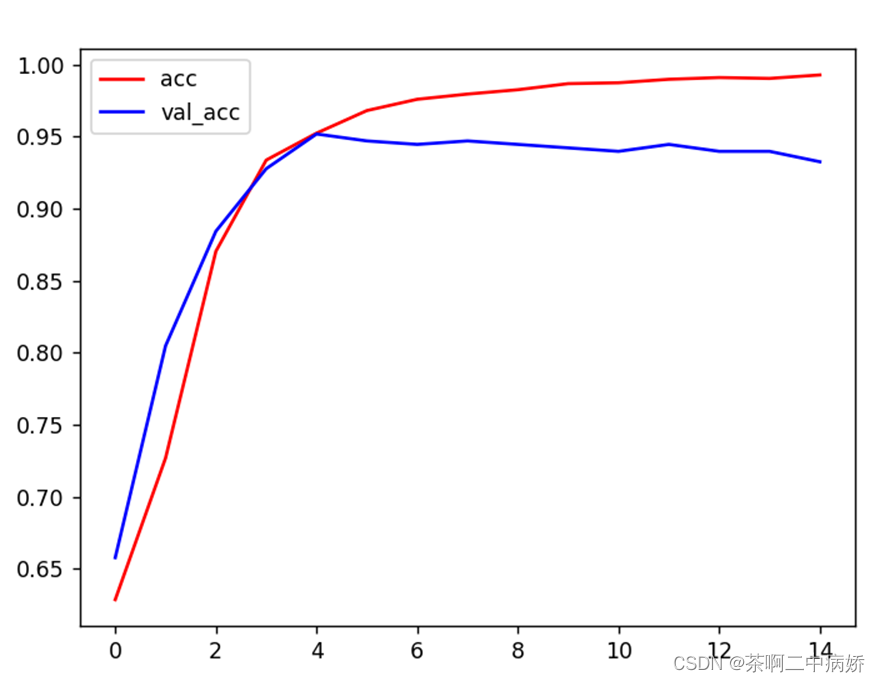
图十一展示acc和val_acc
可以看出验证集和验证集的准确度是不带上升的这就证明了模型的可以的,使用一定的测试集来进行测试查看准确率和输出损失值

图十二测试结果
为了更直观的检测训练的模型,接下来做一个输入评论然后判断是好评还是差评。我的思路是输入一个评论然后用结巴分词和正则表达式分割开来,用word_index.get(word, 0)判断割开的词语是否在之前的列表里的,并使查看之前列表里的词出现的频率,如果评论太高或者一些毫无意义的中性词就把它去掉。如果在的话就把列表的索引替换成词,如果不在的话就忽略。再转成dataframe使用模型测试。测试所有词的平均分数因为我们训练的标签是0和1所以大于0.5是好评小于0.5的是差评。为了准确测试,我们在京东爬取的数
据,去淘宝复制评论进行测试。我们选前面五组好评和后面五组差评进行测试
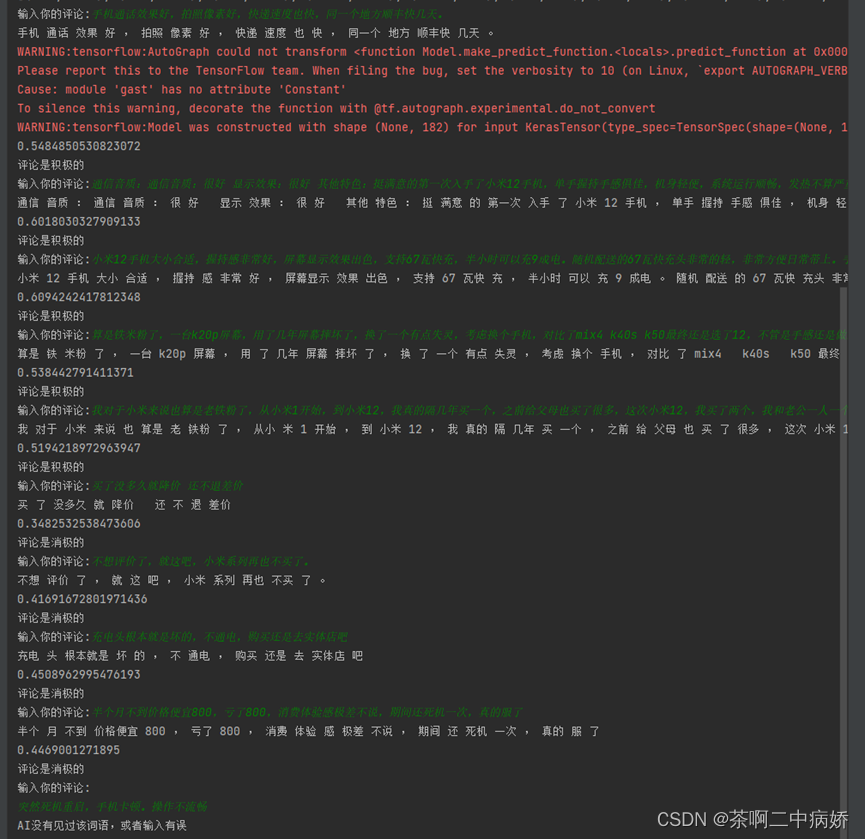
可以看到训练模型的还是可以的,对于判断的结果还是令人比较满意,除了最后一个评论我多复制了一个换行,程序报错,我也用代码做了提醒功能,如果用户输入有错或者是全部都是列表里没有的词汇就会提醒用户,输入有误,或者全部是新词汇,可以重新输入,这里没有重新输入是应为循环10次这是最后一次,报错占用了最后一次循环
五、总结
这次的实验对我还是挺有难度的,不仅要求对书上和课上的知识掌握透彻,还需要掌握爬虫的新知识。其实一开始我是想爬取淘宝评论的,但是奈何淘宝的反爬虫机制太过于强大,所以才转为京东的。刚开始爬京东的时候也是啥都没有,后面用伪造浏览器的方法才能爬出数据。在除里数据时,因为数据格式不对使用函数经常报错,这也是我一个头痛的事情。然后在训练完模型后因为不知道怎么把评论放进去去网上研究了一下午也没有解决这个问题,后面请教一下同学,他说可以用训练的第一列索引放进去试试,我顿时茅塞顿开,将评论结巴转为索引再转为dataframe就可以使用模型了。这次的实验是我大学以来收获最大的实验,通过这次实验不仅对dataframe的知识还有列表字典等处理方法,还有对神经网络的深入了解,更重要的是学会了如何上网查找资料以及变学边做。因为该案例在网上资源比较少,后面参考的还是一篇基于循环网络lstm对航空评论的预测。但是它处理的是英文所以差距还是蛮大的。比这跟大的意义在于,人类对人工智能的研究,通过我训练的模型也可以方便用户使用。从这次的实战给我带来了不小的成就,也激发了我独自编程的快乐,对自己提升很大。
代码
爬虫代码
import requests
import json
from urllib.parse import urlencode
import time
def hp():
print("正在爬取好评")
callback = 'fetchJSON_comment98vv13370'
def get_url(page): # 获得每一页评论的url
url_ = 'https://club.jd.com/comment/productPageComments.action?'
param = {
'callback': 'fetchJSON_comment98vv13370',
'productId': 100017358626, # 改这里就行
'score': 3, # 3是好评,4是中评,5是差评,0是全部
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
url = url_ + urlencode(param)
print(url)
return url
def get_html(url): # 返回评论真实的网页内容
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'referer': 'https://item.jd.com/68767398029.html#comment'
}
res = requests.get(url, headers=headers)
return res.text
def get_json(html, callback): # 得到评论的json数据
data = html.replace(callback, '')
data = data.replace('(', '')
data = data.replace(')', '')
data = data.replace(';', '')
data = json.loads(data)
return data
t1 = []
for i in range(150): # 爬取10页评论好评
url = get_url(i)
print("正在爬取第%s页" % i)
html = get_html(url)
data = get_json(html, callback)
for i in data['comments']:
t1.append(i['content'])
time.sleep(1)
# print(t1)
# print(i)
print(i['content'])
print('---------')
with open("商品好评.csv", 'w') as f:
for i in t1:
f.write(i + '\n') # 按行写入txt换行
def cp():
print("正在爬取差评")
callback = 'fetchJSON_comment98vv13370'
def get_url(page): # 获得每一页评论的url
url_ = 'https://club.jd.com/comment/productPageComments.action?'
param = {
'callback': 'fetchJSON_comment98vv13370',
'productId': 100017358626, # 改这里就行
'score': 1, # 3是好评,4是中评,5是差评,0是全部
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
url = url_ + urlencode(param)
print(url)
return url
def get_html(url): # 返回评论真实的网页内容
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'referer': 'https://item.jd.com/68767398029.html#comment'
}
res = requests.get(url, headers=headers)
return res.text
def get_json(html, callback): # 得到评论的json数据
data = html.replace(callback, '')
data = data.replace('(', '')
data = data.replace(')', '')
data = data.replace(';', '')
data = json.loads(data)
return data
t1 = []
for i in range(150): # 爬取10页评论 全部评论
url = get_url(i)
print("正在爬取第%s页" % i)
html = get_html(url)
data = get_json(html, callback)
for i in data['comments']:
t1.append(i['content'])
time.sleep(1)
# print(t1)
# print(i)
print(i['content'])
print('---------')
with open("商品差评.csv", 'w') as f:
for i in t1:
f.write(i + '\n') # 按行写入csv换行
def qb():
print("正在全部")
callback = 'fetchJSON_comment98vv13370'
def get_url(page): # 获得每一页评论的url
url_ = 'https://club.jd.com/comment/productPageComments.action?'
param = {
'callback': 'fetchJSON_comment98vv13370',
'productId': 100017358626, # 改这里就行
'score': 1, # 3是好评,4是中评,5是差评,0是全部
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
url = url_ + urlencode(param)
print(url)
return url
def get_html(url): # 返回评论真实的网页内容
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'referer': 'https://item.jd.com/68767398029.html#comment'
}
res = requests.get(url, headers=headers)
return res.text
def get_json(html, callback): # 得到评论的json数据
data = html.replace(callback, '')
data = data.replace('(', '')
data = data.replace(')', '')
data = data.replace(';', '')
data = json.loads(data)
return data
t1 = []
for i in range(200): # 爬取10页评论
url = get_url(i)
print("正在爬取第%s页"% i)
html = get_html(url)
data = get_json(html, callback)
for i in data['comments']:
t1.append(i['content'])
time.sleep(1)
# print(t1)
# print(i)
print(i['content'])
print('---------')
with open("商品差评.csv", 'w') as f:
for i in t1:
f.write(i + '\n') # 按行写入txt换行
hp()
cp()
qb()
评论情感分析代码
coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import jieba
from nltk import FreqDist
from pandas import DataFrame
from sklearn.model_selection import train_test_split
import keras.preprocessing.text as text
import re
from sklearn.feature_extraction.text import CountVectorizer
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
"""将京东的好评和差评分别放到两个不同的dataframe"""
df1 = pd.read_csv('商品好评.csv',encoding='gbk',header=None,sep = '\t')
df1['comment']=df1#给评论放上comment的列名
df1 = df1.drop(0, axis=1)#删除原来有列明为0的那一行
print(df1)
df2 = pd.read_csv('商品差评.csv',encoding='gbk',header=None,sep = '\t')
df2['comment']=df2
df2 = df2.drop(0, axis=1)
df1['comment'] = df1.comment.apply(lambda x:' '.join(jieba.cut(x)))#结巴分词
print(df1)
df2['comment'] = df2.comment.apply(lambda x:' '.join(jieba.cut(x)))
df1['yn']=1#分别给好评和差评附上0和1的标签
df2['yn']=0
df_p=pd.concat([df1,df2])
print(df1)
l1 = []
l2= []
def r1():
global l1,l2#声明为全局变量
for s1 in df1['comment']:
# print('9999')
# print(s1)
s1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!, ,: : 。?、~@#¥%……&*()]+", "", s1)#用正则表达式除去特殊符号
s1 = re.sub(r'[0-9]', '', s1)#用正则表达式除去数组
s1 = re.sub(r'[A-Za-z]', ' ', s1)#用正则表达式除去英文
cut = jieba.lcut(s1) # 结巴分
l1.append(cut)#将结巴的词放进l1里
for s1 in df2['comment']:
s1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!, ,: : 。?、~@#¥%……&*()]+", "", s1)
s1 = re.sub(r'[0-9]', '', s1)
s1 = re.sub(r'[A-Za-z]', ' ', s1) # 用正则表达式除去英文
cut = jieba.lcut(s1) # 结巴分
l2.append(cut)
l1 = {'comment': l1}#将数组l1变成字典
l2 = {'comment': l2}
l1 = DataFrame(l1)#将字典l变成datafram
l2 = DataFrame(l2)
df1['comment']= l1['comment']#将df1的评论换成l1结巴去杂的评论
df2['comment'] =l2['comment']
r1()
df=pd.concat([df1,df2])#拼接好评和坏品
d_n = df[df['yn']==0]#把0和1的评论分别放如两个dataframe
d_y = df[df['yn']==1]
d_y = d_y.iloc[:len(d_n)]#把差评好评弄成一样多
print(len(d_y),len(d_n))
data = pd.concat([d_y, d_n])
data = data.sample(len(data))#将好评差评全部打乱顺序
print(data)
word_set = set()#新建一个集合用于把全部评论放进去
for text in data.comment:
for word in text:
if (word not in word_set):#除去重复的词语
word_set.add(word)
word_list = list(word_set)
print('word_list')
print(word_list)
print(word_list.index('响应速度'))
word_index = dict((word, word_list.index(word)+1) for word in word_list)#word_list.index(word)+1是为了让单词和数字对应从1开始,一般情况下索引是从0开始的,给他们标上索引
print('word_index')
print(word_index)
data_ok = data.comment.apply(lambda x: [word_index.get(word, 0) for word in x])#把评论这列词语替换成索引
print('data_ok1')
print(data_ok)
print(len(data_ok.iloc[2]))
"""因为每条评论长度不一样,我们需要填充成长度一致的向量,不够的用0填充,这就是word_index是从1开始的原因"""
maxlen = max(len(x) for x in data_ok)#查看最长评论
max_word = len(word_set) + 1
data_ok = tf.keras.preprocessing.sequence.pad_sequences(data_ok.values, maxlen=maxlen )#不够长的填充为0,变为一样长
print('data_ok2')
print(data_ok)
print('data_ok[0:1]')
print(data_ok[1:2])
print(data_ok.shape)
print(data.yn.values)
"""构建模型"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(max_word, 50, input_length=maxlen))
model.add(tf.keras.layers.LSTM(64))#64是隐藏单元个数
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
"""训练模型"""
print('总样本数量:%d' % (len(data)))
print('训练集数量:%d' % (len(data_ok)))
history = model.fit(data_ok, data.yn, epochs=15, batch_size=128, validation_split=0.2 )
x_train, x_test, y_train, y_test = train_test_split(data_ok,data.yn, random_state=1)
print('测试集数量:%d' % (len(x_train)))
loss, acc = model.evaluate(x_test, y_test)
print('输出损失值:', loss)
print('准确率:',acc)
"""将训练结果可视化"""
plt.plot(history.epoch, history.history.get('acc'), 'r', label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), 'b', label='val_acc')
plt.legend()
plt.show()
"""使用模型进行评论测试"""
z1 = {}
for s1 in df_p['comment']:
s1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!, ,: : 。?、~@#¥%……&*()]+", "", s1)
cut = jieba.cut(s1)# 结巴分词
for word in cut:
if not (word in z1):
z1[word] = 0
else:
z1[word] += 1
w1 = sorted(z1.items(), key=lambda kv: kv[1], reverse=True)#对词语进行排序
print("查看全部词语出现频率")
print(w1)
model.save('pinglun.h5')#保存模型
model=tf.keras.models.load_model('pinglun.h5')#使用模型
p2 =model.predict(data_ok[0:1])
for i in range(10):
try:
predict_text = input('输入你的评论:') # predict_text='小米发热严重'
predict_text = ' '.join(jieba.lcut(predict_text)) # 将你输入的评论结巴好,并用空格分开
print(predict_text)
text = []
text_list = predict_text.split(' ') # 将每个词语放入列表里
word_z = ['小米', '手机', '的', '了'] # 做一个中性词词表提高准确率
# print(text_list)
for word in text_list: # 将输入的词语和训练集的词语做对比,如果输入的词语不在训练集里则忽略,剩下的放如text里
if (word in word_index) and (word not in word_z):
# print(word)
text.append(word_index.get(word, 0))
# print(text)
text = DataFrame(text) # 转为datafram,格式要和训练的格式一样,跟data_ok[0:1]一样,data_ok[0:1]表示为第一条评论
a1 = 0
p2 = model.predict(text) # 将输入的评论放如模型测试
for p in p2: # 神经网络贝叶斯
a1 = a1 + p[0]
a1 = a1 / len(p2)
print(a1)
if a1 > 0.50: # 判断标准,机器人智障就改这里
print('评论是积极的')
else:
print('评论是消极的')
except:
print("AI没有见过该词语,或者输入有误")
pass
finally:
continue
Original: https://blog.csdn.net/qq_39454086/article/details/125352967
Author: 茶啊二中病娇
Title: 基于循环神经网络lstm构建一个商品评论分类模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/667665/
转载文章受原作者版权保护。转载请注明原作者出处!