

Network In Network
文章目录
*
–
+ Network In Network
+
* 摘要
* 1. 介绍
*
–
+ 传统卷积网络有什么问题?
+ 相同点和不同点
+ 平均池化带来的好处?
* 2. 卷积神经网络
*
–
+ 传统卷积神经网络的问题:
+ 之前的改进工作
+ 之前改进工作存在的问题:
+ 本文所做的改进:
* 3. NetWork In Network
*
– 3.1 MLP卷积层
–
+ 为什么选择多层感知机?
+ ==什么是级联跨通道带参数的池化层(cascaded cross channel parametric pooling)==
– 3.2 全局平均池化
–
+ FC层有什么问题?
+ 本文的解决方法
+ 本文方法的优势
– 3.3 Network In Network结构
* 4. 实验
*
– 4.1 C I F A R − 10 4.1 \space CIFAR-10 4 .1 C I F A R −1 0
– 4.5 全局平均池化作为正则方法
– 4.7 NIN的可视化
摘要
作者 提出了一种新的深度网络结构称为”网络中的网络(N I N NIN N I N )”,目的是为了增强对感受野内图像块的辨别能力。
传统的卷积层使用线性滤波器,其后跟着非线性激活函数,用他们两个的组合来扫描输入。相反,作者用一种更复杂的结构去构微建神经网络,以达到抽象感受野内数据的目的。
作者将这种微网络结构用多层感知机的形式实例化。通过以和C N N CNN C N N相似的方式在输入上滑动微网络,就可以获得特征图。这些特征图将作为输入被传递至下一层。
深度N I N NIN N I N能够通过堆叠许多个上述结构来实现,通过微网络来提升局部建模, 作者能够利用在分类层的特征图上进行全局平均池化,这更容易解释并且比传统F C FC F C 层更不具有过拟合的倾向。
作者用N I N NIN N I N在C I F A R − 10 CIFAR-10 C I F A R −1 0和C I F A R − 100 CIFAR-100 C I F A R −1 0 0上展示了达到先进水平的性能,并且在S V H N SVHN S V H N和M N I S T MNIST M N I S T上表现良好。
1. 介绍
下文中”概念”通俗理解就是特征的种类
传统卷积网络有什么问题?
C N N CNN C N N中的传统的卷积核对于图像块来说是一个广义线性模型(G L M GLM G L M),作者认为G L M GLM G L M所提取特征是低层次的,作者认为抽象意味着对于概念相同的变体的特征是不变的。用一种更强劲的非线性函数逼近器来替换G L M GLM G L M能够提增强局部模型抽象的能力。但是在变量是线性可分时,G L M GLM G L M的抽象能力很好,但是同类数据经常线性不可分,因此能够捕捉这种性质的表征经常是输入的高度线性不可分函数。
在N I N NIN N I N中,G L M GLM G L M被替换为一种”微网络”结构,可看成是一种广义的非线性函数逼近器,作者选择多层感知机作为微网络的实现,他是一种通用的函数逼近器,能够用过反向传播训练。
由此而来的,称之为M l p c o n v Mlpconv M l p c o n v的结构在图 1 图1 图1中与C N N CNN C N N进行了对比。
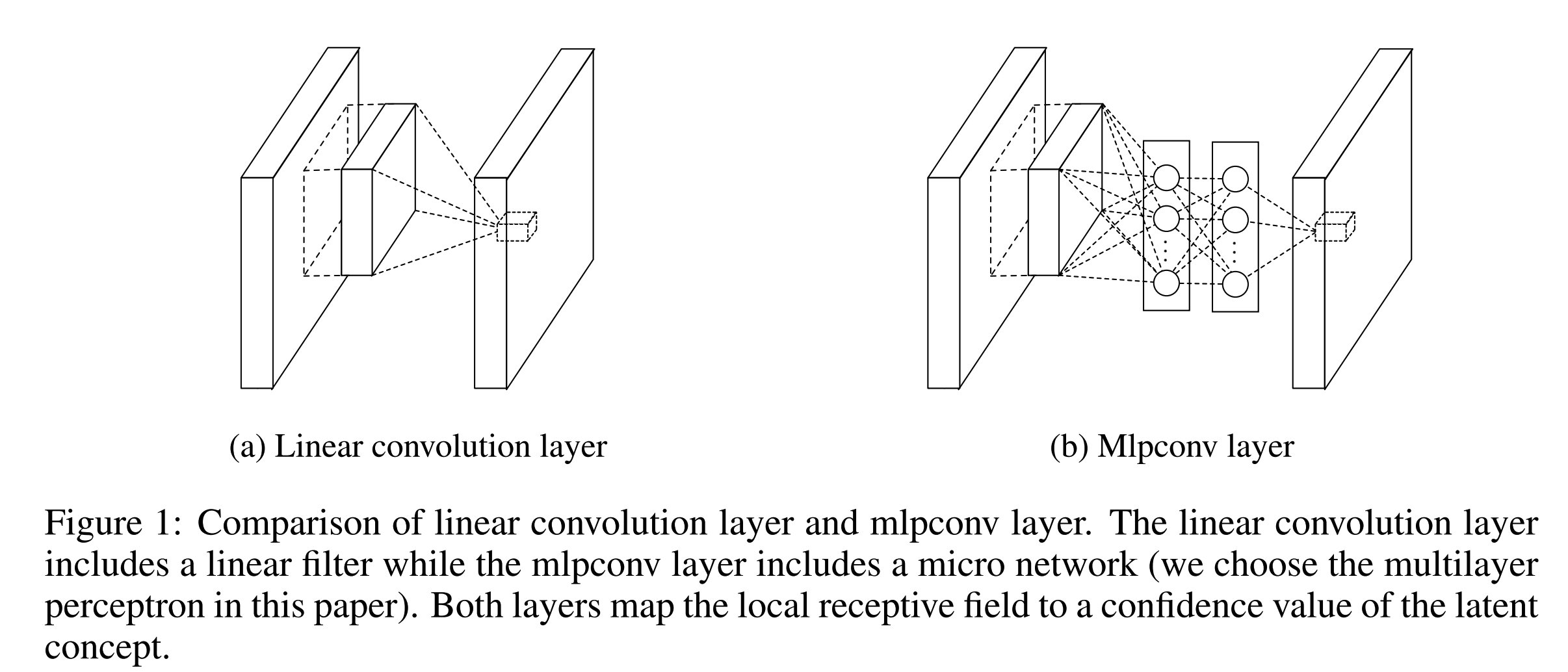

; 相同点和不同点
他们都将局部感受野映射为特征向量,但M l p c o n v Mlpconv M l p c o n v通过多层感知机(M L P MLP M L P)来完成映射,M L P MLP M L P由多个全连接层和非线性激活函数组成,此M L P MLP M L P在所有局部感受野之间共享,特征图通过在输入上滑动 M L P MLP M L P来获得,N I N NIN N I N的整体结构时多个m l p c o n v mlpconv m l p c o n v层的堆叠。
作者没有采用传统CNN中的FC层进行分类,而是直接用全局平均池化对最后的m l p c o n v mlpconv m l p c o n v层取平均值作为类别的置信度,然后将产生的向量直接送入 s o f t m a x softmax s o f t m a x层。
平均池化带来的好处?
在传统的CNN中,很难解释来自目标成本层的类别级信息是如何传递回前一个卷积层的,因为完全连接的层在两者之间充当一个黑匣子。相反,全局平均池化是一种更有意义,解释性更强的方式,因为它加强了特征图和种类之间的对应关系,这是通过使用微网络进行更强的局部建模来实现的。
另外,F C FC F C层更倾向于过拟合,并且严重依赖于d r o p o u t dropout d r o p o u t正则,但是全局平均池化本身就是一种结构正则化方法,能够简单的组织过拟合。
2. 卷积神经网络
传统卷积神经网络的问题:
对于线性可分的表征来说,卷积神经网络用来进行特征抽象是足够的。但是能够实现好的抽象的表征往往是输入数据的高度线性不可分函数。传统C N N CNN C N N中,可以通过使用一整套滤波器来进行补偿,以覆盖潜在概念的所有变体。(通俗来讲就是也能找到属于该种类的线性不可分的样本。)即单个线性滤波器能够学习检测同一个种类的 不同表现形式。 但是对于一个概念用太多滤波器会对下一层施加额外的负担,下一层需要考虑上一层中变体的所有组合。
C N N CNN C N N中越高层的滤波器向原始输入中投射的区域越大。通过组合低等级的属性种类来产生高等级的属性种类。因此,作者认为在将低等级特征组合成高等级特征之前,就在每个局部块上做好抽象比较好。
之前的改进工作
在最近的m a x o u t maxout m a x o u t中,通过在放射特征图上做最大池化来减少特征图数量。线性函数上做最大化产生一个分段线性逼近器,能够逼近任何凸函数。
m a x o u t maxout m a x o u t更加强劲因为它能划分位于凸函数集中的特征种类,这中改进使得m a x o u t maxout m a x o u t网络在许多基准数据集上展示出极佳的表现。
之前改进工作存在的问题:
但是,m a x o u t maxout m a x o u t网络施加了一个先验条件:潜在概念的实例都位于输入空间的凸集中,这不一定成立。所以当潜在概念的分布更复杂时有必要使用一个更具普适性的函数逼近器。
本文所做的改进:
作者希望能通过引入”N I N NIN N I N”来实现这个目的,在每个卷积层中引入”微网络”来计算局部块更加抽象的特征。
之前也有工作提出在输入数据上滑动微型网络来获取特征图,但是这些工作都具有针对性并且只有一层。本文是从一个更加普适的角度提出的N I N NIN N I N,这种微型结构被整合进C N N CNN C N N结构中来更好的对各个等级的特征进行抽象。
3. NetWork In Network
N I N NIN N I N的关键组成部分:
- M L P MLP M L P卷积层
- 全局平均池化层
3.1 MLP卷积层
径向基网络(Radial basis Network)和多层感知机是两个众所周知的通用函数逼近器。
为什么选择多层感知机?
- 卷积神经网络用反向传播来训练,多层感知机适合其结构,
- 多层感知机自己也可以是一个深度模型,遵循特征复用的精神。
本文中将这种新类型的层称为”m l p c o n v mlpconv m l p c o n v”,用M L P MLP M L P代替G L M GLM G L M在输入上进行卷积。所执行的计算如下所示:
f i , j , k 1 1 = m a x ( w k 1 1 T x i , j + b k 1 , 0 ) f_{i,j,k_1}^1=max({w_{k_1}^1}^Tx_{i,j}+b_{k_1},0)f i ,j ,k 1 1 =m a x (w k 1 1 T x i ,j +b k 1 ,0 )
…
f i , j , k n n = m a x ( w k n n T f i , j n − 1 + b k n , 0 ) f_{i,j,k_n}^n=max({w_{k_n}^n}^T{f_{i,j}^{n-1}}+b_{k_n},0)f i ,j ,k n n =m a x (w k n n T f i ,j n −1 +b k n ,0 )
n是多层感知机的层数。
什么是级联跨通道带参数的池化层(cascaded cross channel parametric pooling)
微型网络在输入数据上进行滑动,每滑动一次,在输入数据上产生一个滑动窗口,称为一个p a t c h patch p a t c h。对于一个m × n × k m\times n\times k m ×n ×k的p a t c h patch p a t c h,用p p p个m × n × k m\times n\times k m ×n ×k的卷积核进行卷积,输出k k k个1 × 1 1\times1 1 ×1的特征图,然后再将这k k k个1 × 1 1\times1 1 ×1的
作为F C FC F C层的输入,输出k k k个1 × 1 1\times1 1 ×1的特征图,如下图所示:
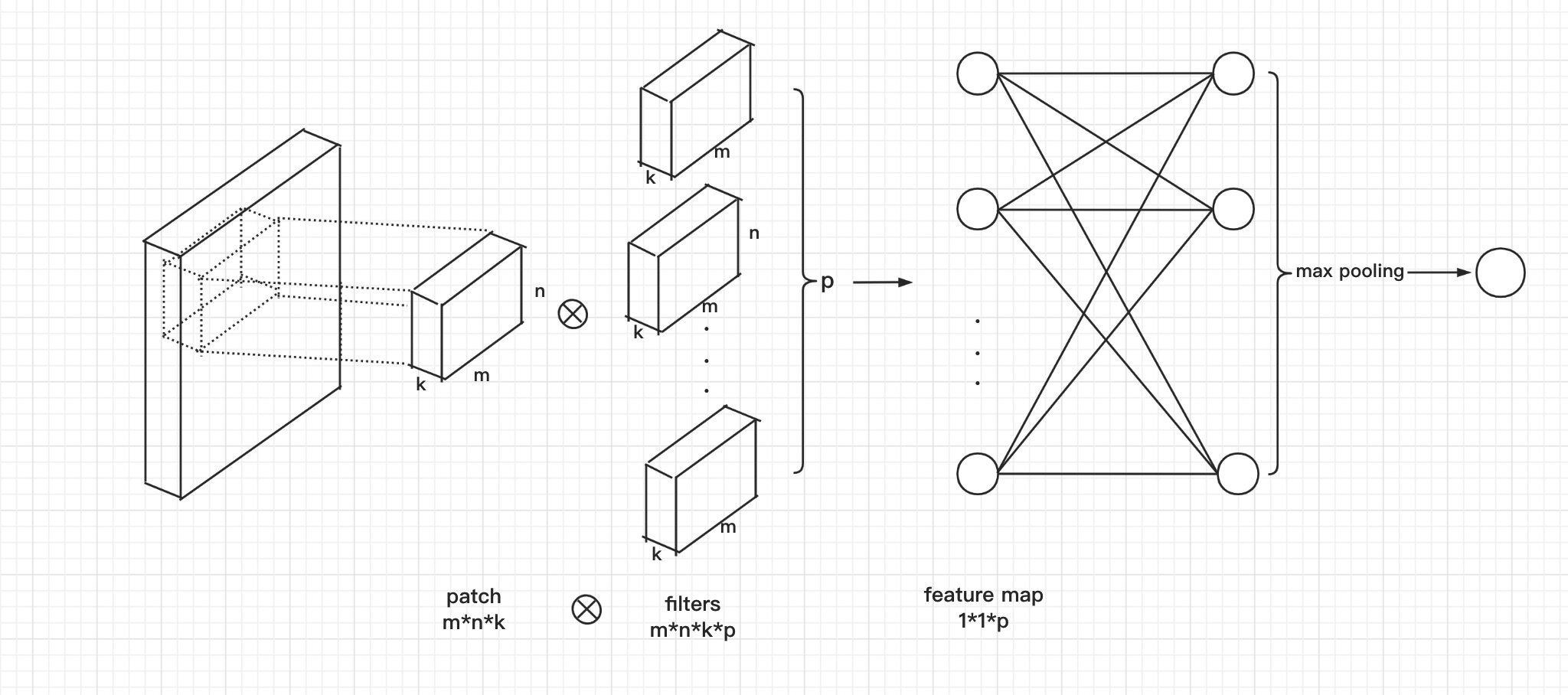
其中全连接层可以通过1 × 1 1\times 1 1 ×1的卷积来替代,就是对 1 × 1 × p 1\times1\times p 1 ×1 ×p的f e a t u r e m a p feature\space map f e a t u r e m a p用p p p个1 × 1 × p 1\times1\times p 1 ×1 ×p的卷积核进行卷积,输出结果的s i z e size s i z e同样为 1 × 1 × p 1\times1\times p 1 ×1 ×p。
上图省略了激活函数和池化函数
这也是级联跨通道带参数的池化层名称的由来,本来是由卷积产生的 1 × 1 × p 1\times1\times p 1 ×1 ×p的特征图,p p p代表的是特征的个数,我们将这p p p个1 × 1 1\times 1 1 ×1的特征用不同的参数进行赋权组合,所以称为跨通道带参数的池化层。这一过程本身是通过F C FC F C层来完成的,但是使用1 × 1 1\times 1 1 ×1的卷积层来进行代替。
优点:允许跨通道信息的复杂的可学习的交互。
这里也提出了一个概念:全连接网络可以用1 × 1 1\times 1 1 ×1 的卷积层来进行代替,很多论文中都引用了这一观点。
; 3.2 全局平均池化
传统的卷积神经网络都是在提取特征时执行卷积,然后分类时将提取到的特征传入F C FC F C层以及气候的s o f t m a x softmax s o f t m a x层。这种结构将卷积结构和传统的神经网络分类器连接起来,将卷积层作为特征提取器。
FC层有什么问题?
F C FC F C层容易过拟合。为解决此问题所提出的D r o p o u t Dropout D r o p o u t有效提升了模型泛化能力,抑制过拟合。
本文的解决方法
作者提出了一种称作全局平均池化的策略来替换CNN中的F C FC F C层。主要思想是在最后一个m l p c o n v mlpconv m l p c o n v层中,为分类任务的每个对应的种类产生一个特征图。
本文方法的优势
1. 相比于$FC$层,全局平均池化层强制要求特征图和种类之间的对饮关系,因此更加适合卷积结构。
2. 没有参数,无需优化,所以在这层中不会出现过拟合。
3. 将空间信息相加,对于输入信息的空间移动更加健壮。
作者认为,可以将全局平均池化看成是结构正则化方法,强制地将特征图强制映射为置信度图。这点可以通过m l p c o n v mlpconv m l p c o n v层来实现 。
3.3 Network In Network结构
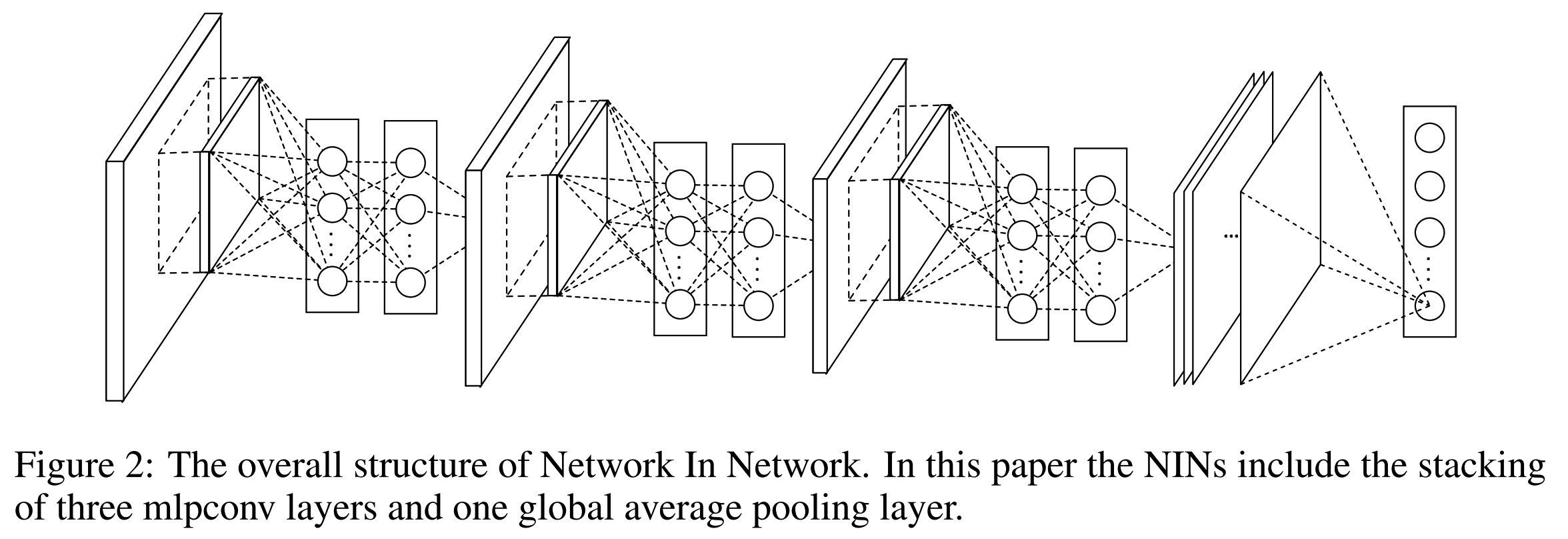
N e t w o r k I n N e t w o r k Network\space In\space Network N e t w o r k I n N e t w o r k整体结构就是许多m l p c o n v mlpconv m l p c o n v堆叠起来,最上层是全局平均池化层和分类层。可以在C N N CNN C N N和m a x o u t maxout m a x o u t网络中的m l p c o n v mlpconv m l p c o n v层之间添加子采样层。图 2 图2 图2 展示了具有三个m l p c o n v mlpconv m l p c o n v层的N e t w o r k I n N e t w o r k Network\space In\space Network N e t w o r k I n N e t w o r k结构。在每个m l p c o n v mlpconv m l p c o n v层内有一个三层感知机,网络中的层数量对于特定的任务是可变的。
; 4. 实验
- C I F A R − 10 CIFAR-10 C I F A R −1 0
- C I F A R − 100 CIFAR-100 C I F A R −1 0 0
- S V H N SVHN S V H N
- M N I S T MNIST M N I S T
实验中所有m l p c o n v mlpconv m l p c o n v层后面都跟着空间最大池化层。并且以d r o p o u t dropout d r o p o u t作为正则用在除了最后一层之外的所有m l p c o n v mlpconv m l p c o n v层后。
除非特殊说明,否则本文中的所有网络都用用全局平均池化来代替顶部的F C FC F C层。
还用了权重衰减。
人工设置了权重了学习率的初始值,用128 128 1 2 8的小批次训练,学习率在训练集的准确率停止增长后以10 10 1 0为比例下降。
4.1 C I F A R − 10 4.1 \space CIFAR-10 4 .1 C I F A R −1 0
使用了和G o o d f e l l o w Goodfellow G o o d f e l l o w在m a x o u t maxout m a x o u t网络中使用的一样的全局对比度归一化和Z C A ZCA Z C A白化。
结果:10.41 10.41%1 0 .4 1的误差,比前沿水平提升了多于1%。

如图 3 图3 图3所示,在两个m l p c o n v mlpconv m l p c o n v层之间引入d r o p o u t dropout d r o p o u t层能够降低20 % 20\%2 0 %多的测试误差。结果与G o o d f e l l o w Goodfellow G o o d f e l l o w一致。
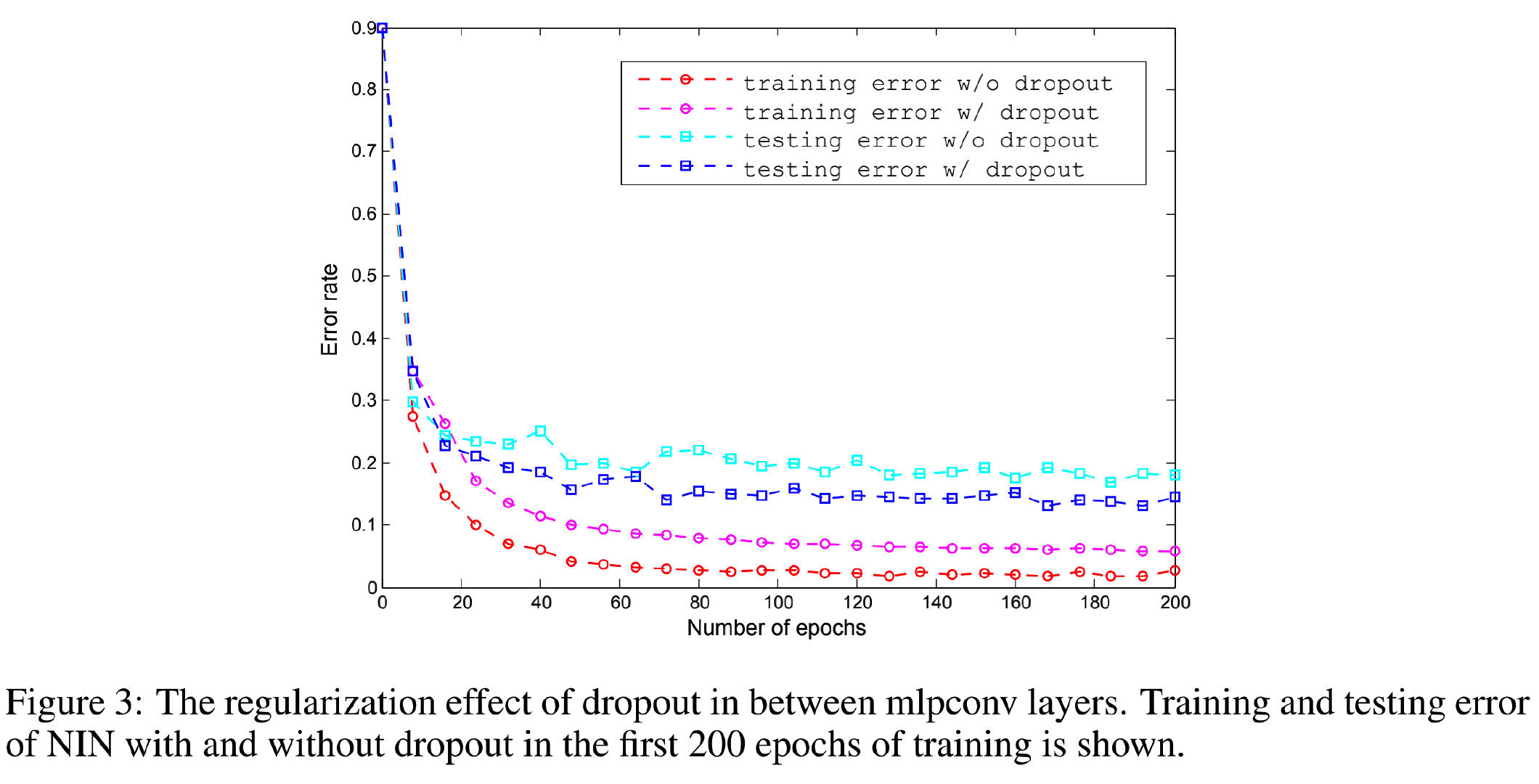
不加d r o p o u t dropout d r o p o u t层的误差为14.51 % 14.51\%1 4 .5 1 %,也已经超过了之前使用了正则的先进技术了。
4.2 C I F A R − 100 4.2 \space CIFAR-100 4 .2 C I F A R −1 0 0
没有调节超参数,而是用之前C I F A R − 10 CIFAR-10 C I F A R −1 0的,并且将最后一层数层100 100 1 0 0路特征图。
结果:测试误差为35.68 % 35.68\%3 5 .6 8 %,比先进水平高了1%。

4.3 S V H N 4.3 \space SVHN 4 .3 S V H N
预处理方式与 C I F A R − 10 相 同 CIFAR-10相同C I F A R −1 0 相同。
结果:误差率为2.35 % 2.35\%2 .3 5 %

4.4 M I N I S T 4.4 \space MINIST 4 .4 M I N I S T
结果:误差率:0.47 % 0.47\%0 .4 7 %和先进水平持平,但没有进步。
; 4.5 全局平均池化作为正则方法
全局平均池化层和全连接层很相似,因为他们都对向量化的特征图执行线性变换。
区别在于变换矩阵不同。
对于全局平均池,变换矩阵是带前缀的,并且仅在共享相同值的对角线元素上变换矩阵是非零的。
对于全连接层来说,可以具有密集的变换矩阵,并且值能够用反向传播算法进行优化。
作者为了研究全局平均池化的正则作用,做了一组对比实验,将N I N NIN N I N顶部的全局平均池化层换成了全连接层,然后比较了在全连接层前面加d r o p o u t dropout d r o p o u t和不佳d r o p o u t dropout d r o p o u t层,以及N I N NIN N I N本身,实验结果如表 5 表5 表5:

没有d r o p o u t dropout d r o p o u t层的全连接层结果最差,这是因为没用正则方法,发生了过拟合。全局平均池化的误差率最低。
作者随后证明了全局平均池化对传统的卷积神经网络具有同样的正则效果。
4.7 NIN的可视化
Original: https://blog.csdn.net/weixin_43669978/article/details/121448008
Author: 俯仰天地
Title: 【论文精读】Network In Network(1*1 卷积层代替FC层 global average pooling)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/667323/
转载文章受原作者版权保护。转载请注明原作者出处!