

文章目录
一.导言
在实战这块,我们已经具备了一些入门基本的原理和神经网络的整体过程的理解,在训练中为了节省时间,实战以keras进行演示,以便更快地获得模型运行性能并加以分析。如果有时间,后面也会用原生来书写一遍,以便加深对神经网络的认识。
二.电影评论二分类实战
2.1 步骤
导入库 -> 获取数据 -> 建立模型 -> 训练 -> 精度评估 -> 是否改进模型
2.2 导入库
from keras import models
from keras import layers
from tensorflow.keras import optimizers
from keras import losses, metrics
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import imdb
2.3 获取数据
2.3.1 导入数据
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = 10000)
train_data[0]
部分结果:


2.3.2 数据处理
因为电影评论数据加载进来为单词的索引,所以我们需要进行变换来查看语句是什么。
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
decoded_review
结果:

我们会发现通过上述操作,我们就转换成了单词。
2.3.3 向量化数据
我们最终训练的是矩阵,所以上述变换只是用于查看原句子的内容,我们还需要一种常用的方法向量化 将每行的句子按照索引(索引对应向量的列号为1,反之为0) 进行处理
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
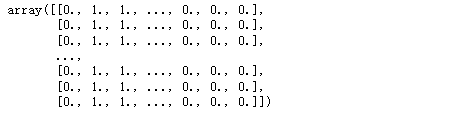
x_train
结果:
2.3.4 处理监督数据(label data)
我们也需要将监督数据转成向量化。
y_train = np.asarray(train_labels).astype(np.float32)
y_test = np.asarray(test_labels).astype(np.float32)
为了更好的理解,我们先打印下监督数据结果:

2.4 建立模型
以下建立了输入层,隐藏层,输出层。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy', metrics=['accuracy'])
2.5 模型训练
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
history = model.fit(partial_x_train,partial_y_train,epochs=20,batch_size=512,validation_data=(x_val,y_val))
history_dict = history.history
history_dict.keys()
结果:
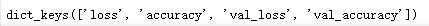
2.6 模型评估
2.6.1 训练损失和验证损失
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
结果:
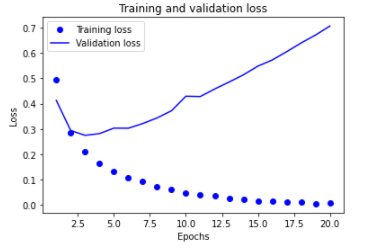
我们发现,随着训练的进行,训练集的损失逐渐减小,验证集的损失逐渐增大。
2.6.2 训练精度和验证精度
plt.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
结果:
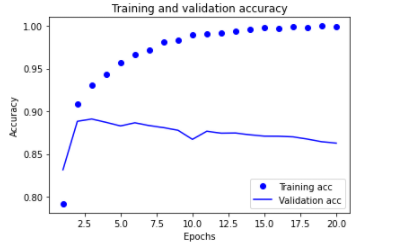
我们发现,通过图中表明,训练集精度逐渐增大,验证集精度逐渐减小。
2.6.3 模型评估结果
我们发现,随着训练的进行,模型在第3轮之后出现了过拟合,因此我们需要改进模型使之达到效果。
2.7 改进模型
重新训练模型。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train,epochs=4,batch_size=512)
results = model.evaluate(x_test, y_test)
results

测试数据评估:
test_result = model.predict(x_test)
np.sum(test_result > 0.9)
最后得到 7817(总数25000)个预测精度达到0.9。
2.8 总结
通过最常用的方法我们达到了上述效果,如果通过最先进的方法,可以达到99% 以上精度。
Original: https://blog.csdn.net/Hhjnv/article/details/121886206
Author: 我不止三岁
Title: 深度学习实战-01 实现一个电影评论二分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666795/
转载文章受原作者版权保护。转载请注明原作者出处!