

文章目录
*
– 前言
– 什么是BERT?
–
+ 它与其他机器学习算法的不同之处
– 代码示例
–
+ 开始设置
+ 准备数据
+ 训练模型
+ 做一个预测
+ 鸣谢!!!!
前言
*Bert的原理资料已经很多这里不多陈述,仅仅用一个实际例子来说明。文章用详细的步骤演示BERT的使用过程。
机器学习有很多应用程序,其中之一是自然语言处理或 NLP。NLP 处理诸如文本响应、在上下文中找出单词的含义以及与我们进行对话之类的事情。它帮助计算机理解人类语言,以便我们可以用不同的方式进行交流。从聊天机器人到求职申请,再到将您的电子邮件分类到不同的文件夹中,NLP 在我们周围无处不在。自然语言处理的核心是计算机科学和语言学的融合。语言学为我们提供了用于训练机器学习模型并获得所需结果的规则。自然语言处理成为机器学习的重要组成部分的原因有很多。它可以帮助机器从客户的反馈中检测情绪,它可以帮助对你正在处理的任何项目的支持票进行排序,并且它可以一致地阅读和理解文本。而且由于它是根据一组语言规则运作的,因此它不会像人类那样有偏见。
由于 NLP 是一个如此大的研究领域,因此您可以使用许多工具来分析特定目的的数据。
有一种 基于规则的方法,您可以在其中设置大量 if-then 语句来处理文本的解释方式。通常语言学家会负责这项任务,他们产生的东西很容易被人们理解。这可能是一个很好的开始,但是当您开始使用大型数据集时,它会变得非常复杂。另一种方法是在不需要定义规则的情况下使用机器学习。当您尝试快速准确地分析大量数据时,这非常有用。
*选择正确的算法以便机器学习方法在效率和准确性方面发挥作用非常重要。有一些常见的算法,如朴素贝叶斯和支持向量机。然后是更具体的算法,如 Google BERT。
什么是BERT?
*BERT 是 Google 于 2018 年创建的开源库。这是 NLP 的一项新技术,它采用与任何其他技术完全不同的方法来训练模型。
BERT 是来自 Transformers 的双向编码器表示的首字母缩写词。这意味着与大多数从左到右或从右到左分析句子的技术不同,BERT使用 Transformer 编码器进行双向分析。它的目标是生成一个语言模型。这使它在较小的数据集上具有令人难以置信的准确性和性能,从而解决了自然语言处理中的一个巨大问题。虽然有大量基于文本的数据可用,但很少有标记用于训练机器学习模型。
由于大多数NLP 问题的方法都利用了深度学习,因此您需要使用大量数据进行训练。当使用数百万个数据点训练模型时,您会真正看到模型的巨大改进。为了帮助解决没有足够标记数据的问题,研究人员想出了通过使用互联网上的文本进行预训练来训练通用语言表示模型的方法。然后可以对这些预先训练的表示模型进行微调,以处理比深度学习中常用的数据集更小的特定数据集。这些较小的数据集可以用于情感分析或垃圾邮件检测等问题。这是处理大多数NLP 问题的方式,因为与从较小的数据集开始相比,它提供了更准确的结果。
*这就是为什么 BERT 是一个如此重大的发现。它提供了一种使用更少数据更准确地预训练模型的方法。它使用的双向方法意味着它可以获得更多的单词上下文,而不仅仅是在一个方向上进行训练。有了这个额外的上下文,它就可以利用另一种称为掩码LM 的技术。
它与其他机器学习算法的不同之处
*Masked LM 使用 [MASK] 标记随机屏蔽句子中 15% 的单词,然后尝试根据 被屏蔽单词周围的单词来 预测它们。这就是 BERT 能够 从左到右和从右到左查看单词的方式。
*这与其他所有现有语言模型完全不同,因为它同时查看掩码单词前后的单词。BERT 的很多准确性都可以归因于此。要让 BERT 处理您的数据集,您必须添加一些元数据。需要 token embeddings来标记句子的 开头和 结尾。您需要有 segment embeddings才能 区分不同的句子。最后,您需要 positional embeddings 来 指示单词在句子中的位置。它看起来与此类似。
[CLS] the [MASK] has blue spots [SEP] it rolls [MASK] the parking lot [SEP]
*将元数据添加到您的数据点后,掩码 LM 就可以开始工作了。
一旦完成单词的预测,BERT 就会利用下一句预测。这着眼于两个句子之间的关系。它这样做是为了更好地理解整个数据集的上下文,通过取 一对句子并 根据原文预测第二个句子是否是下一个句子。为了在 BERT 技术中进行下一句预测,第二句通过 基于 Transformer 的模型发送。
BERT 有 四种不同的预训练版本,具体取决于您处理的数据规模。您可以在此处了解有关它们的更多信息: https : //github.com/google-research/bert#bert
这种方法的 缺点是 损失函数只考虑掩码词的预测,而不考虑其他词的预测。这意味着 BERT 技术比其他从右到左或从左到右的技术 收敛得更慢。
***BERT 可以应用于您能想到的任何 NLP 问题,包括 意图预测、 问答应用和 文本分类。
代码示例
开始设置
现在我们将通过一个运行中的 BERT 示例。您需要做的第一件事是 克隆 Bert 存储库。
git clone https://github.com/google-research/bert.git
*现在您需要从 BERT GitHub 页面下载预训练的 BERT 模型文件。
我将使用 BERT-Base, Uncased 模型,但您会在 GitHub 页面上找到跨不同语言的其他几个选项。选择 BERT-Base, Uncased 模型的一些原因是如果您 无权访问 Google TPU,在这种情况下您通常会 选择 Base 模型。如果您认为要分析的文本的大小写 区分大小写(文本的大小写给出了真正的上下文含义),那么您将 使用 Cased 模型。如果casing不重要或者您还不太确定,那么 Uncased 模型将是一个有效的选择。
***我们将使用一些 Yelp 评论作为我们的 数据集。请记住,BERT 期望使用这些 token embedding和 其他格式的数据。我们需要将它们添加到 .tsv 文件中。该文件类似于 .csv,但它有四列, 没有标题行。
下面是四列的样子。
第 0 列:行 ID
第 1 列:行标签(必须是整数)
第 2 列:所有行的相同字母的列(它不用于任何事情,但 BERT 期望它)
第 3 列:我们要分类的文本
*需要在克隆 BERT 的目录中创建一个名为 data 的文件夹,并在其中添加三个文件: train.tsv、 dev.tsv、 test.tsv。
*在 train.tsv和 dev.tsv文件中,我们将拥有我们之前讨论过的四列。在 test.tsv文件中,我们将只有要分类为列的行 ID 和 文本。这些将是我们用来 训练和 测试模型的数据文件。
准备数据
*首先,我们需要获取将要使用的数据。您可以在此处为自己下载 Yelp 评论: https://course.fast.ai/datasets#nlp 它位于 NLP 部分下,您将需要 Polarity 版本。
我们将使用此版本的原因是因为数据已经具有极性,这意味着它已经具有与之关联的情绪。将此文件保存在数据目录中。
***现在我们准备 开始编写代码。在 根目录中创建一个名为 pre_processing.py的新文件并添加以下代码。
import pandas as pd
import tarfile
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
yelp_reviews = tarfile.open('data/yelp_review_polarity_csv.tgz')
yelp_reviews.extractall('data')
yelp_reviews.close()
train_df = pd.read_csv('data/yelp_review_polarity_csv/train.csv', header=None)
print(train_df.head())
test_df = pd.read_csv('data/yelp_review_polarity_csv/test.csv', header=None)
print(test_df.head())
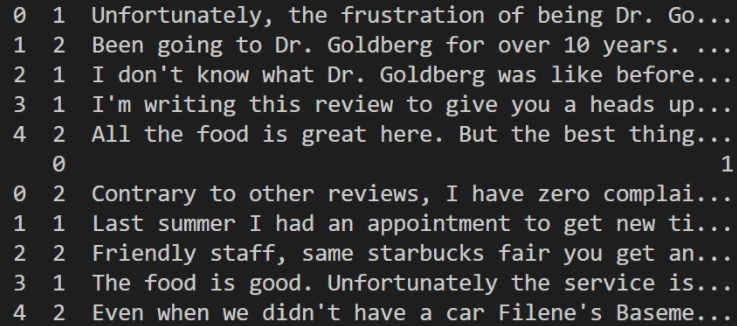

****在这段代码中,我们导入了一些
Python 包并解压缩了数据以查看数据的样子。您会注意到与评论相关的值是 1 和 2, 1 表示差评, 2 表示好评。我们需要将这些值转换为更标准的标签,即 0 和 1。您可以使用以下代码来实现。
train_df[0] = (train_df[0] == 2).astype(int)
test_df[0] = (test_df[0] == 2).astype(int)
每当您对数据进行更新时,务必查看结果是否正确。所以我们将使用以下命令来做到这一点。
print(train_df.head())
print(test_df.head())
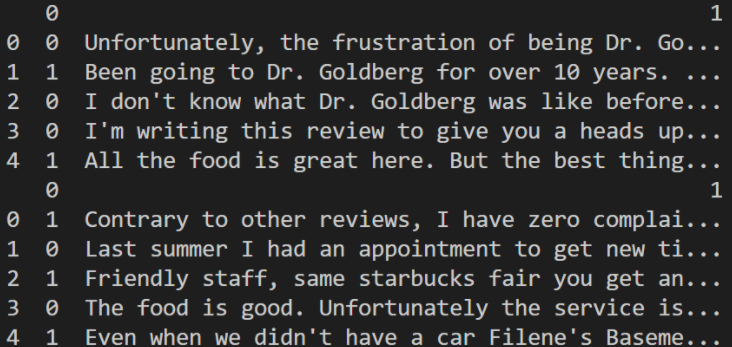
当您看到您的极性值已更改为您
预期的值时。现在数据应该有 1 和 0。****由于我们已经清理了初始数据,是时候为 BERT 做好准备了。我们必须使我们的数据适合我们之前讨论过的列格式。让我们从训练数据开始。
****训练数据将包含所有四列: 行 id、 行标签、 单个字母、 我们要分类的文本。
****BERT 需要两个名为 train和 dev 的训练文件。在使用以下命令格式化数据后,我们将通过将初始训练文件拆分为两个文件来制作这些文件。
bert_df = pd.DataFrame({
'id': range(len(train_df)),
'label': train_df[0],
'alpha': ['q']*train_df.shape[0],
'text': train_df[1].replace(r'\n', ' ', regex=True)
})
train_bert_df, dev_bert_df = train_test_split(bert_df, test_size=0.01)
****使用 bert_df变量,我们将数据格式化为 BERT 所期望的。如果您愿意,您可以为 alpha 值选择任何其他字母。我们在开始时导入的 train_test_split方法处理将 训练数据拆分为我们需要的两个文件。
看看如何使用此命令格式化数据。
print(train_bert_df.head())
****现在我们需要 格式化测试数据。这看起来与我们处理训练数据的方式不同。BERT 只需要两列用于测试数据: 行 id,我们 要分类的文本。一旦我们拥有这种格式的测试数据,我们就不需要对其进行任何其他操作,我们将使用以下命令执行此操作。
test_bert_df = pd.DataFrame({
'id': range(len(test_df)),
'text': test_df[1].replace(r'\n', ' ', regex=True)
})
这与我们对训练数据所做的类似,只是没有两列。看看新格式化的测试数据。
test_bert_df.head()
如果一切正常,您可以将这些变量保存为 BERT 将使用的 .tsv 文件。
train_bert_df.to_csv('data/train.tsv', sep='\t', index=False, header=False)
dev_bert_df.to_csv('data/dev.tsv', sep='\t', index=False, header=False)
test_bert_df.to_csv('data/test.tsv', sep='\t', index=False, header=False)
训练模型
****在我们开始训练模型之前的一个简短说明:BERT 在笔记本电脑上可能会 占用大量资源。它可能会导致内存错误,因为没有足够的 RAM 或其他一些 硬件不够强大。您可以尝试使 training_batch_size更小,但这会使模型 训练变得非常缓慢。
****将一个文件夹添加到名为 model_output的根目录。这就是训练完成后我们的模型将被保存的地方。现在打开一个终端并转到该项目的根目录。进入正确的目录后,运行以下命令,它将开始训练您的模型
python run_classifier.py --task_name=cola --do_train=true --do_eval=true --data_dir=./data/ --vocab_file=./uncased_L-12_H-768_A-12/vocab.txt --bert_config_file=./uncased_L-12_H-768_A-12/bert_config.json --init_checkpoint=./uncased_L-12_H768_A-12/bert_model.ckpt.index --max_seq_length=128 --train_batch_size=32 --learning_rate=2e-5 --num_train_epochs=3.0 --output_dir=./model_output --do_lower_case=False
您应该会看到一些输出在终端中滚动。运行完成后,您将拥有一个训练有素的模型,可以进行预测!
做一个预测
****如果您查看 model_output目录,您会注意到有一堆 model.ckpt文件。这些文件在训练期间的不同点具有训练模型的权重,因此您希望找到数字最高的那个。这将是您要使用的最终训练模型。
****现在我们将使用稍微不同的选项再次运行 run_classifier.py。特别是,我们将 init_checkpoint值更改为 最高模型检查点,并将新的 --do_predict值设置为 true。这是您需要在 终端中运行的命令。
python run_classifier.py --task_name=cola --do_predict=true --data_dir=./data --vocab_file=./uncased_L-12_H-768-A-12/bert_config.json --init_checkpoint=./model_output/model.ckpt-<highest checkpoint number> --max_seq_length=128 --output_dir=./model_output
鸣谢!!!!
Original: https://blog.csdn.net/shdabai/article/details/118675146
Author: QuietNightThought
Title: 深度学习 一 :使用BERT做 NLP分类任务
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666627/
转载文章受原作者版权保护。转载请注明原作者出处!