

文章目录
*
–
+ k近邻分类算法
+
* K = 1时的预测情况
* k = 3 时的预测情况
* k = 5 时的预测情况
+ 实战—-鸢尾花分类(不同k值对预测值的影响)
+ 总结
k近邻分类算法
k近邻分类算法,即k-NN算法,可以说是最简单的机器学习算法。
核心思想就是,通过测量预测的数据点与已训练数据点之间 距离,寻找距离 最近的已训练数据点(最近的训练数据点 个数由算法使用者自己指定,适中即可)的标签结果,即为测试数据点的预测结果。
K = 1时的预测情况
可见下图:
import mglearn
mglearn.plots.plot_knn_classification(n_neighbors=1)
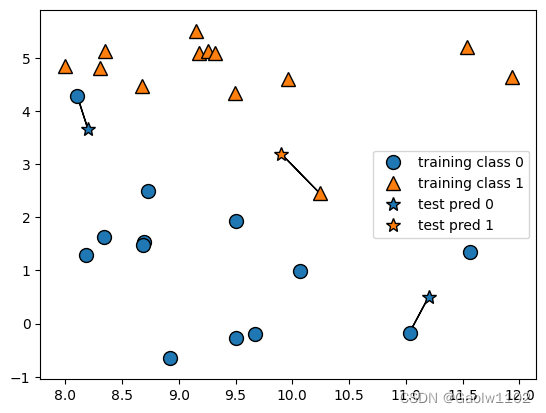

其中三个预测点(五角星标识test pred),分别找到了与它们最近的一个已训练数据点,并根据近邻训练点的结果,得到预测结果。
k = 3 时的预测情况
在考虑多余一个邻居的情况下,使用投票法(voting)来指定标签,即出现次数更多的类别作为预测结果。
可见下图:
import mglearn
mglearn.plots.plot_knn_classification(n_neighbors=3)
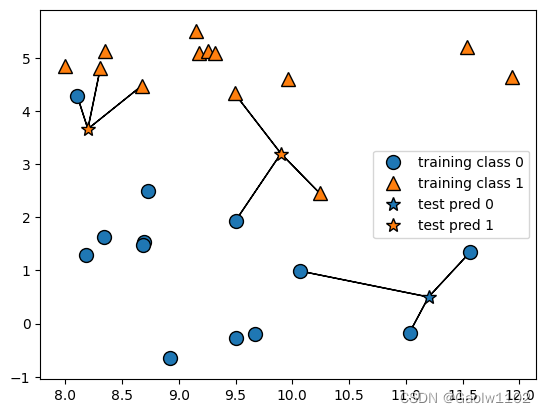
同上图,预测结果也可以从五角星的颜色中得出,可得,当邻居个数不同时,预测结果也会不同。
k = 5 时的预测情况
可见下图:
import mglearn
mglearn.plots.plot_knn_classification(n_neighbors=5)
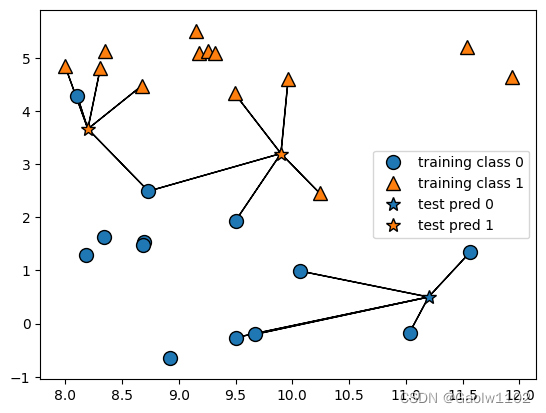
可见,预测需要考虑的情况越来越复杂。
那么是否是选定邻居越多时预测越准确呢?
答案是否定的,我们可以使用鸢尾花分类这个案例对 k-NN 算法进行分析。
实战—-鸢尾花分类(不同k值对预测值的影响)
from IPython.display import display
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
print('X_train shape: {}'.format(X_train.shape))
print('y_train shape: {}'.format(y_train.shape))
print('X_test shape: {}'.format(X_test.shape))
print('y_test shape: {}'.format(y_test.shape))
print('--------------------------------------')
train_pres = []
test_pres = []
for i in range(1, 39):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
train_pre = knn.score(X_train, y_train)
test_pre = knn.score(X_test, y_test)
train_pres.append(train_pre)
test_pres.append(test_pre)
train_pre_points = np.array(train_pres)
test_pre_points = np.array(test_pres)
plt.plot(train_pre_points, '.-r')
plt.plot(test_pre_points, '.-g')
`
X_train shape: (112, 4)
y_train shape: (112,)
X_test shape: (38, 4)
y_test shape: (38,)
Original: https://blog.csdn.net/weixin_43479947/article/details/126687136
Author: Gaolw1102
Title: k-NN分类算法详解与分析(k近邻分类算法)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666429/
转载文章受原作者版权保护。转载请注明原作者出处!