

目录
01 | SVM简介
02 | 乳腺癌诊断
1.先导入需要的库
2.设置seabon,matplotlib中文显示,pycharm显示行数扩大
3.svm实例化
4.数据集准备
5.数据集预处理
6.描述分析
7.模型训练
01 | SVM简介
SVM(支持向量机)算法是通过对数据的训练,利用间隔最大化找到一个最优分离超平面。下面我们用一个例子来说明。
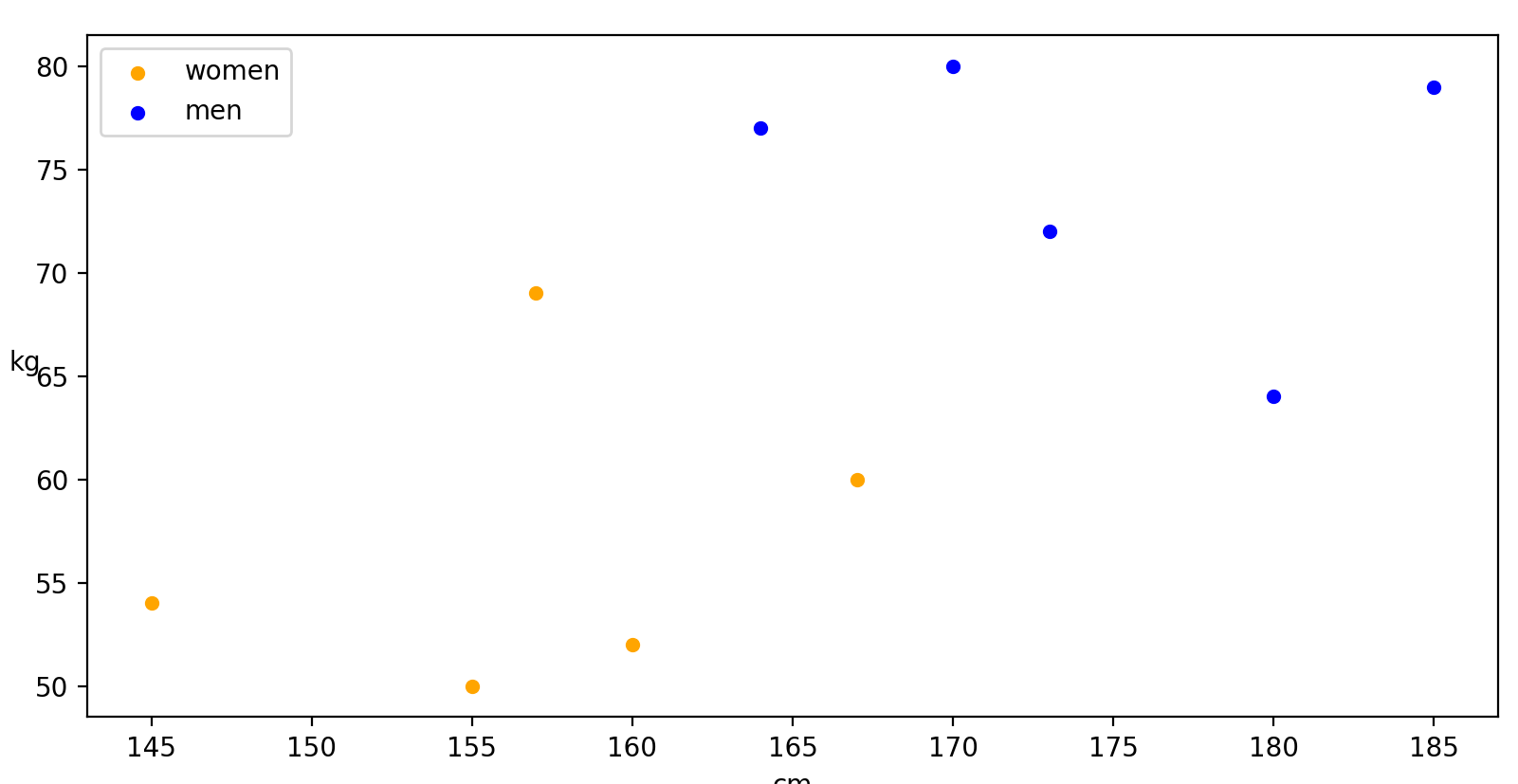
我们生成一个男女身高体重的数据,现在拿到一个新的数据(x,y),利用已知的数据能否推断出新的数据是一名男性或者是女性吗。
①通过画一条直线,将已知的点分为两部分,直线以上是男生,直线以下是女生。
②这个是一个二维平面,可以画直线。但是在三维的平面中,它是面。在更高的维度中,我们称之为超平面
③面有若干个,最合适的被称之为最优分离超平面
import matplotlib.pyplot as plt
import seaborn as sns
women_heigth = [155,145,157,160,167]
women_weigth = [50,54,69,52,60]
men_heigth = [164,170,173,180,185]
men_weigth = [77,80,72,64,79]
sns.scatterplot(x = women_heigth,y = women_weigth,markers = '+',color = 'orange',label = 'women')
sns.scatterplot(x = men_heigth,y = men_weigth,markers = '^',color = 'blue',label = 'men')
plt.xlabel('cm')
plt.ylabel('kg',rotation = '0')
plt.legend()
plt.show()

02 | 乳腺癌诊断
数据集:
https://github.com/cystanford/breast_cancer_data/
1.先导入需要的库
①常规的数据预处理库pandas,numpy。图库matplotlib,seaborn
②SVM库
③数据处理归一化sklearn.preprocessing,数据集划分train_test_split
④模型评分metrics,模型参数选择GridSearchCV
from sklearn import svm
import pandas as pd
import sklearn.preprocessing
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
import numpy as np
2.设置seabon,matplotlib中文显示,pycharm显示行数扩大
pd.set_option('display.max_columns',1000)
pd.set_option('display.width',1000)
pd.set_option('display.max_colwidth',1000)
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})
3.svm实例化
①kernel代表核函数的选择,有四种选择,默认rbf(即高斯核函数)
②C代表目标函数的惩罚系数,默认情况下为 1.0
③gamma代表核函数的系数,默认为样本特征数的倒数
model = svm.SVC(kernel = 'rbf',C = 1.0,gamma = '0.001')
4.数据集准备
除去id字段,实际上包含的字段有:
① mean结尾的代表平均值、se结尾的代表标准差、worst结尾代表最坏值(这里具体指肿瘤的特征最大值)。
② diagnosis代表特征
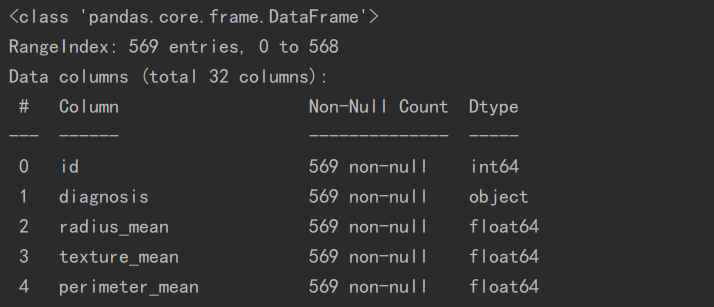
df = pd.read_csv(r'D:\pycharm\data\breast_cancer_data-master\data.csv')
print(df.info())
print(df.head())

5.数据预处理
① 因为特征diagnosis为字符串,在放进模型里面之前要转为数字类型
② mean,se,worst中,mean最能代表特征整体情况
le = sklearn.preprocessing.LabelEncoder()
le.fit(df['diagnosis'])
df['diagnosis'] = le.transform(df['diagnosis'])
print(df['diagnosis'])
df_X = df.filter(regex = '_mean')
df_Y = pd.DataFrame(data = df['diagnosis'],columns = ['diagnosis'])
6.描述分析
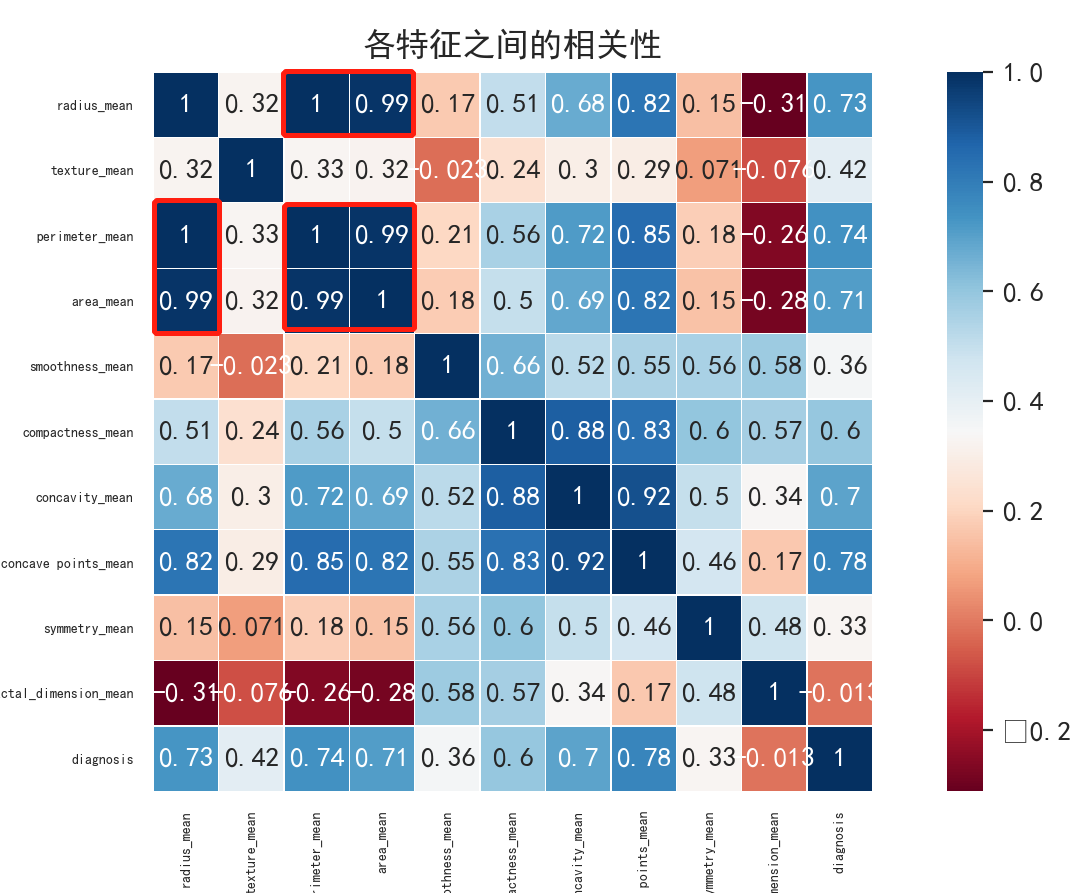
① 查看mean各要素之间的关系
② 通过热力图可以发现,radius_mean、perimeter_mean和area_mean这三个特征强相关,那么只保留一个最高的perimeter_mean
③ 因为是连续数值,最好通过preprocessing.StandardScaler()对其进行标准化
plt.figure(figsize = (8,15))
sns.heatmap(df_X.corr(),linewidths = 0.1,vmax=1.0,square=True,cmap=sns.color_palette('RdBu', n_colors=256),
linecolor='white', annot=True)
plt.xticks(fontsize = 5)
plt.yticks(fontsize = 5)
plt.title('各特征之间的相关性')
plt.show()
df_X.drop(['radius_mean', 'area_mean'], axis=1)
df_X = sklearn.preprocessing.StandardScaler().fit_transform(df_X)
df_Y = sklearn.preprocessing.LabelEncoder().fit_transform(df['diagnosis'])
print(df_X)
print(df_Y)

7.模型训练
① 方法一:LinearSVC 自动调参
② 方法二:主动调参
'''
方法①
X_train, X_test, y_train, y_test = train_test_split(df_X,df_Y,test_size = 0.3,random_state = 0)
svm_model = svm.LinearSVC().fit(X_train,y_train)
pred = svm_model.predict(X_test)
print('准确率:',metrics.accuracy_score(pred,y_test))
'''
parameters = {
'gamma': np.linspace(0.0001, 0.1),
'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
}
svm_model1 = svm.SVC()
grid_model = GridSearchCV(svm_model1,parameters,cv=10,return_train_score=True)
X_train, X_test, y_train, y_test = train_test_split(df_X,df_Y,test_size = 0.2)
grid_model.fit(X_train,y_train)
pred_label = grid_model.predict(X_test)
print(grid_model.best_params_)
print('准确率:',metrics.accuracy_score(pred_label,y_test))

Original: https://blog.csdn.net/weixin_52730784/article/details/116177407
Author: 冷淡的蛋黄酱
Title: sklearn-SVM-乳腺癌诊断分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666163/
转载文章受原作者版权保护。转载请注明原作者出处!