

深度学习——(7)分类任务
文章目录
- 深度学习——(7)分类任务
* - 1. 学习目的
- 2. 上代码
–
+ - 3. 注意
–
+
1. 学习目的
- 以mnist为例,对构建一个10分类的model
- 对model的写法做基本认识
(里面涉及一些详细的知识点,在后期建立model的时候可能不需要这种复杂的写法,只是为了更清楚的了解网络的具体内部运算过程)
注:在jupyter中进行
2. 上代码
2.1 下载数据集
%matplotlib inline
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
2.2 加载数据
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
注:初学者,不要只是运行别人的代码,搞清楚里面的每一步得到的是什么数据,不要ctrl+enter就完事了,如果在ide 可以选择调试,在notebook直接单拎出来打印看看数据类型,数据shape或者直接打印value看看里面到底是什么。


2.3 简单查看数据,熟悉数据
from matplotlib import pyplot
import numpy as np
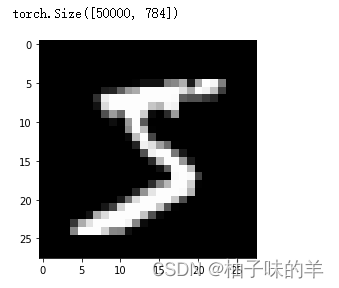
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
2.4 将数据转换为tensor
注:数据需要提前转换为tensor才能参与后续建模训练
import torch
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())

2.5 torch.nn.functional 很多层和函数
torch.nn.functional中有很多功能,后续会常用的。那什么时候使用nn.Module,什么时候使用nn.functional呢?一般情况下,如果模型有可学习的参数,最好用nn.Module,其他情况nn.functional相对更简单一些
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb.mm(weights) + bias
bs = 64
xb = x_train[0:bs]
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
bias = torch.zeros(10, requires_grad=True)
print(loss_func(model(xb), yb))
2.6 创建model
- 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数
- 无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播
- Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器
from torch import nn
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
self.dropout=nn.Dropout(0.5)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = self.out(x)
return x
net = Mnist_NN()
print(net)

2.7 打印权重和偏执
此处没有使用迁移学习,使用别人以前训练好的参数作为权重初始化,所以开始的权重都是随机生成的。
for name, parameter in net.named_parameters():
print(name, parameter,parameter.size())
2.8 使用tensordataset和dataloader对数据进行简化
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
注:shuffle 将数据打乱,使数据尽量没有规律,一般在训练网络时设置为True,让原来的数据没有规律,在验证的时候设置为FALSE
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
2.9 网络训练前准备工作
定义训练函数 , 可不定义,直接写进主函数
import numpy as np
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
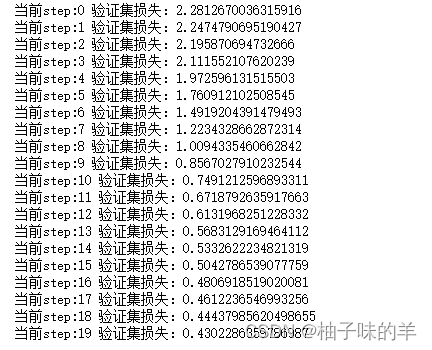
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
注:
- 一般在训练模型时加上model.train(),这样会正常使用Batch Normalization和 Dropout。训练的时候要更新权重
- 测试的时候一般选择model.eval(),这样就不会使用Batch Normalization和 Dropout。验证的时候不更新参数,所以是torch.no_grad()
- zip 两个array进行配对的打包结果,unzip表示解压包。
定义获取model函数
from torch import optim
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
计算batch的loss
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
注:torch上的每一次迭代都是独立的,opt.zero_grad清空以前的梯度,三个要固定一起出现
2.10 训练
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(20, model, loss_func, opt, train_dl, valid_dl)
3. 注意
3.1 可以计算在验证集上的准确率
correct=0
total=0
for xb,yb in valid_dl:
output=model(xb)
_,predict=torch.max(output.data,1)
total += yb.size(0)
correct += (predict==yb).sum().item()
print('ACC of the network on 10000 test image:%d %%' %(100* correct / total))

3.2 optimizer中的SGD和Adam
现在多用Adam,他的下降速度要比其他的快。上面有他和SGD的对比。也可以自己训练的时候试试。
Original: https://blog.csdn.net/qq_43368987/article/details/126581326
Author: 柚子味的羊
Title: 深度学习——(7)分类任务
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/665733/
转载文章受原作者版权保护。转载请注明原作者出处!