

在二分类条件下,我们可以很轻易的在混淆矩阵的基础上定义出各种指标(例如Accurarcy, precision, F 1 F_1 F 1 , recall),其定义方法如下:
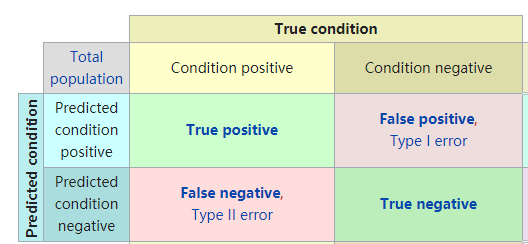

true positive: TP,真实情况为True,预测也为正的样本数。
false positive:FP,真实情况为False,预测为正的样本数。
false negative:FN,真实情况为True,预测为负的样本数。
true negative: TN,真实情况为False,预测为负的样本数。
对于这四个指标,在英文的取名是是两个形容词【A 1 A_1 A 1 ,A 2 A_2 A 2 】,其中第二个形容词是主体,表示预测的结果(预测目标的是正样本,还是负样本),它其实对应着一个命题:预测该样本为正或负样本。第一个形容词是对这个命题的判断结果,表示这个命题的正确与否。
例如: false negative: negative表示”分类器预测该样本为负样本”这个命题。 false则表示这个命题(”分类器预测该样本为负样本”)是错误的,既然命题是错误的,说明这个样本的实际情况是正样本。
在这些指标下,acc,recall,precision的值定义如下:
A c c u r a c y = T P + T N T P + F P + F N + T N Accuracy=\frac{TP+TN}{TP+FP+FN+TN}A c c u r a c y =T P +F P +F N +T N T P +T N
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN}R e c a l l =T P +F N T P
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP}P r e c i s i o n =T P +F P T P
那么对于多分类,如何定义混淆矩阵的TP,FP,FN,TN?
一般的做法是,对于多分类里面的每个类别,将自身类作为正类,其他所有类作为反类,然后定义出各自的T P i , F P i , F N i , T N i TP_i,FP_i,FN_i,TN_i T P i ,F P i ,F N i ,T N i ,然后再去计算各个类别的a c c u r a c y i accuracy_i a c c u r a c y i ,r e c a l l i recall_i r e c a l l i 和F 1 i F_{1i}F 1 i ,其中i i i 表示第i个类别。
如果要计算出分类器对于所有类别的acc和recall,需要把所有类别的结果都汇聚起来,而Macro-average,Micro-average和Weighted-average就是三种汇聚所有类的指标的方式。
具体来说:
Macro-average下的accuracy的计算方式是:
A c c u r a c y m a c r o _ a v g = ∑ i = 1 N 1 N × a c c u r a c y i = ∑ i = 1 N 1 N × T P i + T N i T P i + T N i + F P i + F N i Accuracy_{macro_avg}=\sum^{N}{i=1}\frac{1}{N} \times accuracy_i=\sum^{N}{i=1}\frac{1}{N}\times \frac{TP_i+TN_i}{TP_i+TN_i+FP_i+FN_i}A c c u r a c y m a c r o a v g =i =1 ∑N N 1 ×a c c u r a c y i =i =1 ∑N N 1 ×T P i +T N i +F P i +F N i T P i +T N i
这相当于把所有类别的权重都是设置为一致,这种方式在测试样本的类别在数量上极端不均衡的时候极端的不合理。
因此,为了考虑到不同类别的样本不均衡,就有所谓的Weighted-average计算方式:
A c c u r a c y w e i g h t _ a v g = ∑ i = 1 N T P i + F N i ∑ j = 1 N T P i + F N i × a c c u r a c y i Accuracy{weight_avg}=\sum^{N}{i=1}\frac{TP_i+FN_i}{\sum^{N}{j=1} TP_i+FN_i}\times accuracy_i A c c u r a c y w e i g h t _a v g =i =1 ∑N ∑j =1 N T P i +F N i T P i +F N i ×a c c u r a c y i
这是把第i个类别的权重设置为了第i类样本占所有类别样本的比例了。
而Micro-average下的Precision和recall的计算方式和accuracy的计算方式还不太一样:
R e c a l l = ∑ i = 1 N T P i ∑ j = 1 N T P j + F N j Recall=\frac{\sum_{i=1}^{N}TPi}{\sum_{j=1}^N TP_j+FN_j}R e c a l l =∑j =1 N T P j +F N j ∑i =1 N T P i
P r e c i s i o n = ∑ i = 1 N T P i ∑ j = 1 N T P j + F P j Precision=\frac{\sum_{i=1}^{N}TPi}{\sum_{j=1}^N TP_j+FP_j}P r e c i s i o n =∑j =1 N T P j +F P j ∑i =1 N T P i
而Accuracy是说,所有这些样本里面,有多少个样本是识别正确的,因此它的计算方式为:
A c c u r a c y = ∑ i = 1 N T P i 总 样 本 数 Accuracy=\frac{\sum_{i=1}^{N}TPi}{总样本数}A c c u r a c y =总样本数∑i =1 N T P i
; 举例说明
我们举个三分类的例子加以说明。
如下图所示的混淆矩阵:
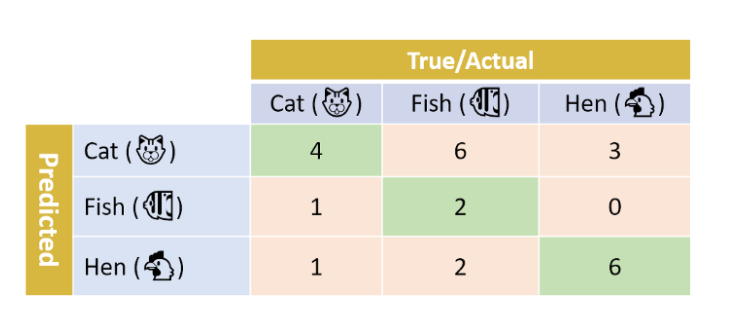
对猫,鱼,鸡,我们可以分别求出各自的TP,TN,FP,FN:
T P 猫 = 4 TP_{猫}=4 T P 猫=4,T P 鱼 = 2 TP_{鱼}=2 T P 鱼=2,T P 鸡 = 6 TP_{鸡}=6 T P 鸡=6
T N 猫 = 2 + 2 + 0 + 6 = 10 TN_{猫}=2+2+0+6=10 T N 猫=2 +2 +0 +6 =1 0,T N 鱼 = 4 + 3 + 1 + 6 = 14 TN_{鱼}=4+3+1+6=14 T N 鱼=4 +3 +1 +6 =1 4,T N 鸡 = 4 + 6 + 1 + 2 = 13 TN_{鸡}=4+6+1+2=13 T N 鸡=4 +6 +1 +2 =1 3
F P 猫 = 6 + 3 = 9 , F P 鱼 = 1 + 0 = 1 , F P 鸡 = 1 + 2 = 3 FP_{猫}=6+3=9,FP_{鱼}=1+0=1,FP_{鸡}=1+2=3 F P 猫=6 +3 =9 ,F P 鱼=1 +0 =1 ,F P 鸡=1 +2 =3
F N 猫 = 1 + 1 = 2 , F N 鱼 = 6 + 2 = 8 , F N 鸡 = 3 + 0 = 3 FN_{猫}=1+1=2,FN_{鱼}=6+2=8,FN_{鸡}=3+0=3 F N 猫=1 +1 =2 ,F N 鱼=6 +2 =8 ,F N 鸡=3 +0 =3
于是对于猫来说:
A c c u r a c y 猫 = 4 + 10 4 + 10 + 9 + 2 = 0.56 Accuracy_{猫}=\frac{4+10}{4+10+9+2}=0.56 A c c u r a c y 猫=4 +1 0 +9 +2 4 +1 0 =0 .5 6
r e c a l l 猫 = 4 6 = 0.66 recall_{猫}=\frac{4}{6}=0.66 r e c a l l 猫=6 4 =0 .6 6
p r e c i s i o n 猫 = T P 猫 T P 猫 + F P 猫 = 4 4 + 9 = 0.3076 precision_{猫}=\frac{TP_{猫}}{TP_{猫}+FP_{猫}}=\frac{4}{4+9}=0.3076 p r e c i s i o n 猫=T P 猫+F P 猫T P 猫=4 +9 4 =0 .3 0 7 6
对于鱼来说:
A c c u r a c y 鱼 = 2 + 14 2 + 14 + 1 + 8 = 0.64 Accuracy_{鱼}=\frac{2+14}{2+14+1+8}=0.64 A c c u r a c y 鱼=2 +1 4 +1 +8 2 +1 4 =0 .6 4
r e c a l l 鱼 = 2 2 + 8 = 0.20 recall_{鱼}=\frac{2}{2+8}=0.20 r e c a l l 鱼=2 +8 2 =0 .2 0
p r e c i s i o n 鱼 = T P 鱼 T P 鱼 + F P 鱼 = 2 2 + 1 = 0.66 precision_{鱼}=\frac{TP_{鱼}}{TP_{鱼}+FP_{鱼}}=\frac{2}{2+1}=0.66 p r e c i s i o n 鱼=T P 鱼+F P 鱼T P 鱼=2 +1 2 =0 .6 6
对于鸡来说:
A c c u r a c y 鸡 = 6 + 13 6 + 13 + 3 + 3 = 0.76 Accuracy_{鸡}=\frac{6+13}{6+13+3+3}=0.76 A c c u r a c y 鸡=6 +1 3 +3 +3 6 +1 3 =0 .7 6
r e c a l l 鸡 = 6 6 + 3 = 0.66 recall_{鸡}=\frac{6}{6+3}=0.66 r e c a l l 鸡=6 +3 6 =0 .6 6
p r e c i s i o n 鸡 = T P 鸡 T P 鸡 + F P 鸡 = 6 6 + 3 = 0.66 precision_{鸡}=\frac{TP_{鸡}}{TP_{鸡}+FP_{鸡}}=\frac{6}{6+3}=0.66 p r e c i s i o n 鸡=T P 鸡+F P 鸡T P 鸡=6 +3 6 =0 .6 6
接下来,我们分别计算Macro-average,Micro-average和Weighted-average下的三种指标:
Macro-average 情况下 :
a c c = 0.56 + 0.64 + 0.76 3 acc=\frac{0.56+0.64+0.76}{3}a c c =3 0 .5 6 +0 .6 4 +0 .7 6
r e c a l l = 0.66 + 0.66 + 0.20 3 recall=\frac{0.66+0.66+0.20}{3}r e c a l l =3 0 .6 6 +0 .6 6 +0 .2 0
p r e c i s i o n = 0.3076 + 0.66 + 0.66 3 precision=\frac{0.3076+0.66+0.66}{3}p r e c i s i o n =3 0 .3 0 7 6 +0 .6 6 +0 .6 6
Micro-average 情况下:
a c c = 4 + 2 + 6 6 + 4 + 9 = 12 25 = 0.48 acc=\frac{4+2+6}{6+4+9}=\frac{12}{25}=0.48 a c c =6 +4 +9 4 +2 +6 =2 5 1 2 =0 .4 8
r e c a l l = 4 + 2 + 6 4 + 2 + 6 + 2 + 8 + 3 = 12 25 = 0.48 recall=\frac{4+2+6}{4+2+6+2+8+3}=\frac{12}{25}=0.48 r e c a l l =4 +2 +6 +2 +8 +3 4 +2 +6 =2 5 1 2 =0 .4 8
p r e c i s i o n = 4 + 2 + 6 4 + 2 + 6 + 9 + 1 + 3 = 12 25 = 0.48 precision=\frac{4+2+6}{4+2+6+9+1+3}=\frac{12}{25}=0.48 p r e c i s i o n =4 +2 +6 +9 +1 +3 4 +2 +6 =2 5 1 2 =0 .4 8
以及Weighted情况下:
我们首先计算出三个类别的样本比例:
样本总数目:T P 猫 + F N 猫 + T P 鱼 + F N 鱼 + T P 鸡 + F N 鸡 TP_{猫}+FN_{猫}+TP_{鱼}+FN_{鱼}+TP_{鸡}+FN_{鸡}T P 猫+F N 猫+T P 鱼+F N 鱼+T P 鸡+F N 鸡=4+2+2+8+6+3=25
猫占比 r 猫 r_猫r 猫:T P 猫 + F N 猫 T P 猫 + F N 猫 + T P 鱼 + F N 鱼 + T P 鸡 + F N 鸡 = 6 25 = 0.24 \frac{TP_{猫}+FN_{猫}}{TP_{猫}+FN_{猫}+TP_{鱼}+FN_{鱼}+TP_{鸡}+FN_{鸡}}=\frac{6}{25}=0.24 T P 猫+F N 猫+T P 鱼+F N 鱼+T P 鸡+F N 鸡T P 猫+F N 猫=2 5 6 =0 .2 4
鱼占比 r 鱼 r_鱼r 鱼:T P 鱼 + F N 鱼 T P 猫 + F N 猫 + T P 鱼 + F N 鱼 + T P 鸡 + F N 鸡 = 10 25 = 0.4 \frac{TP_{鱼}+FN_{鱼}}{TP_{猫}+FN_{猫}+TP_{鱼}+FN_{鱼}+TP_{鸡}+FN_{鸡}}=\frac{10}{25}=0.4 T P 猫+F N 猫+T P 鱼+F N 鱼+T P 鸡+F N 鸡T P 鱼+F N 鱼=2 5 1 0 =0 .4
鸡占比 r 鸡 r_鸡r 鸡:T P 鸡 + F N 鸡 T P 猫 + F N 猫 + T P 鱼 + F N 鱼 + T P 鸡 + F N 鸡 = 9 25 = 0.36 \frac{TP_{鸡}+FN_{鸡}}{TP_{猫}+FN_{猫}+TP_{鱼}+FN_{鱼}+TP_{鸡}+FN_{鸡}}=\frac{9}{25}=0.36 T P 猫+F N 猫+T P 鱼+F N 鱼+T P 鸡+F N 鸡T P 鸡+F N 鸡=2 5 9 =0 .3 6
于是各个指标就是加权求和了:
a c c = a c c 猫 × r 猫 + a c c 鱼 × r 鱼 + a c c 鸡 × r 鸡 acc=acc_猫\times r_猫+ acc_鱼 \times r_鱼+ acc_鸡 \times r_鸡a c c =a c c 猫×r 猫+a c c 鱼×r 鱼+a c c 鸡×r 鸡=0.56 _0.24+0.64_0.4+0.76*0.36=0.664
r e c a l l = r e c a l l 猫 × r 猫 + r e c a l l 鱼 × r 鱼 + r e c a l l 鸡 × r 鸡 recall=recall_猫\times r_猫+recall_鱼 \times r_鱼+ recall_鸡 \times r_鸡r e c a l l =r e c a l l 猫×r 猫+r e c a l l 鱼×r 鱼+r e c a l l 鸡×r 鸡=0.66 _0.24+0.20_0.4+0.66*0.36=0.476
p r e c i s i o n = p r e c i s i o n 猫 × r 猫 + p r e c i s i o n 鱼 × r 鱼 + p r e c i s i o n 鸡 × r 鸡 precision=precision_猫\times r_猫+ precision_鱼 \times r_鱼+ precision_鸡 \times r_鸡p r e c i s i o n =p r e c i s i o n 猫×r 猫+p r e c i s i o n 鱼×r 鱼+p r e c i s i o n 鸡×r 鸡=0.3076 _0.24+0.66_0.4+0.66*0.36=0.5754
其它
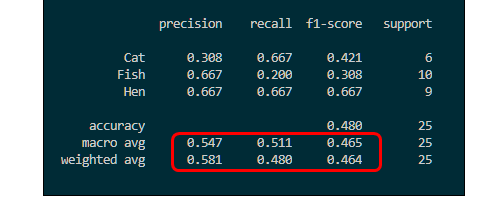
我们会看到上面这个例子里面,Micro-average下,多分类的accuracy,recall和precision会相同。这不是个例,而是多分类任务下,micro-average指标的常态。
这是因为在多分类里面,micro-average情况下,recall和precision的计算公式为:
R e c a l l = ∑ i = 1 N T P i ∑ j = 1 N T P j + F N j Recall=\frac{\sum_{i=1}^{N}TPi}{\sum_{j=1}^N TP_j+FN_j}R e c a l l =∑j =1 N T P j +F N j ∑i =1 N T P i
P r e c i s i o n = ∑ i = 1 N T P i ∑ j = 1 N T P j + F P j Precision=\frac{\sum_{i=1}^{N}TPi}{\sum_{j=1}^N TP_j+FP_j}P r e c i s i o n =∑j =1 N T P j +F P j ∑i =1 N T P i
其中∑ j = 1 N F N j \sum^N_{j=1}FN_j ∑j =1 N F N j 含义为所有类别里面,把【本属于自己类】的样本错误的识别为其他类别的样本数之和;∑ j = 1 N F P j \sum^N_{j=1}FP_j ∑j =1 N F P j 含义为所有类别里面,把【不属于自己类】的样本错误的识别为本类的样本数之和。
假设样本x x x的正确类别为y r y_r y r ,但是预测的类别为y p y_p y p ,且y r ≠ y p y_r\neq y_p y r =y p 。
毫无疑问,对于类别y r y_r y r 来说,它被错误的识别为其他类了,因此这个样本会被统计到∑ j = 1 N F N j \sum^N_{j=1}FN_j ∑j =1 N F N j 里面去。
同时对于类别y p y_p y p 来说,这个样本也会一样统计到∑ j = 1 N F P j \sum^N_{j=1}FP_j ∑j =1 N F P j ,因为它是属于把本不是y p y_p y p 类的样本错误的识别为y p y_p y p 类了。
因此对所有类别求和以后,即有:∑ j = 1 N F N j \sum^N_{j=1}FN_j ∑j =1 N F N j =∑ j = 1 N F P j \sum^N_{j=1}FP_j ∑j =1 N F P j 。
同时注意到,对于每个样本x x x,其预测结果与真实标签之间只存在相等于不相等的关系。如果y r ≠ y p y_r\neq y_p y r =y p 那么这个样本会被统计进∑ j = 1 N F P j \sum^N_{j=1}FP_j ∑j =1 N F P j 或者∑ j = 1 N F N j \sum^N_{j=1}FN_j ∑j =1 N F N j ;如果y r = y p y_r=y_p y r =y p ,那么这个样本会被统计进 ∑ j = 1 N T P j \sum^N_{j=1}TP_j ∑j =1 N T P j ,因此统计量∑ j = 1 N T P j + F N j \sum^N_{j=1}TP_j+ FN_j ∑j =1 N T P j +F N j 其实也等于样本总数;
而a c c u r a c y = ∑ i = 1 N T P i 总 样 本 数 accuracy=\frac{\sum_{i=1}^{N}TPi}{总样本数}a c c u r a c y =总样本数∑i =1 N T P i 。因此,Micro-average平均下,多分类的accuracy,recall和precision其实是一致的。而这也是为什么sklearn里面classification_report在输出的时候,没有micro-average,只有accuracy,macro-average和weighted-average的结果。其实,第一行的accuracy就把micro-average下的三个值都显示出来了,因为precision,recall都是和accuracy相等的。
Original: https://blog.csdn.net/jmh1996/article/details/114935105
Author: Icoding_F2014
Title: 多分类条件下分类指标:Macro-average和Micro-average,以及Weighted-average
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/665609/
转载文章受原作者版权保护。转载请注明原作者出处!