

多标签分类与视觉属性预测
0. 问题概述
对于标签分类问题,表示事物本身可以分为多个类别,但是对于每一个样本存在至少一个类别,例如分类猫、狗、植物、动物。一个样本是猫的同时,又属于动物。因此就不能再像以往的模型一样,输出用 softmax激活函数激活,因为我们最终的输出标签可能同时有很多的类,例如鸟类有羽毛和啄。
1. 搭建模型
通常对多标签任务可以采取两种网络模型,一种是直接输出一个全连接层分支,最后一层输出的神经元数应与标签数量相同,使用 Sigmoid函数激活,将数值映射在 0~1之间。不像 Softmax函数,最后一层输出层数值之和并不等于1,而是全部都介于0与1之间,这样我们便可以设置一个阈值,当某类输出层数值大于这个阈值,则判断该标签为Positive,反之为Negative。模型如下图所示:
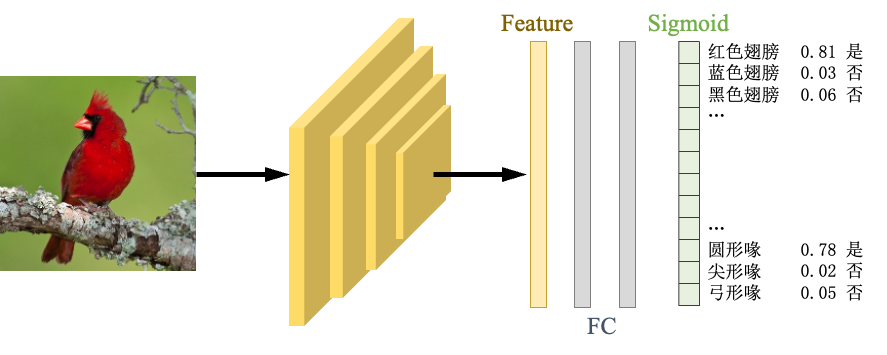

假设我们的图像属性类别为C ∈ { c 1 , c 2 , . . . , c N } C \in {c_1,c_2,…,c_N}C ∈{c 1 ,c 2 ,…,c N },N N N个标签类。最后一层的输出为f ∈ R b a t c h × N f \in \mathbb{R}^{batch \times N}f ∈R b a t c h ×N,经过 Sigmoid函数激活输出的值在 0-1之间,则判断属性时只要设置阈值t h r e s h thresh t h r e s h,大于阈值表示该标签存在,否则不存在:
c i = { 1 f i ≥ t h r e s h 0 f i < t h r e s h c_i = \left{\begin{matrix} 1 & f_i \geq thresh \ 0 & f_i < thresh \end{matrix}\right.c i ={1 0 f i ≥t h r e s h f i <t h r e s h
; 2. 损失函数与标签数据平衡
由于最后的激活函数是 Sigmoid函数,因此我们需要用二分类的损失函数:Binary Cross Entropy。假设预测为x x x,标签为y y y,x x x为经过激活函数 Sigmoid的结果。则我们可以构建损失函数:
l ( x n , y n ) = − ω n [ y n ⋅ log x n + ( 1 − y n ) ⋅ log ( 1 − x n ) ] l(x_n,y_n)=-\omega_n \begin{bmatrix} y_n\cdot \log x_n +(1-y_n) \cdot \log(1-x_n) \end{bmatrix}l (x n ,y n )=−ωn [y n ⋅lo g x n +(1 −y n )⋅lo g (1 −x n )]
我们会考虑到,不同的标签会存在正样本与负样本失衡的情况,例如300张图像中,红色翅膀属性有100,蓝色翅膀属性有200,正负样本不均匀,因此需要我们调节正负样本比例,但是数据不好扩增,因此我们可以修改损失函数:
l n , c = − ω n , c [ p c y n , c ⋅ log x n , c + ( 1 − y n , c ) ⋅ log ( 1 − x n , c ) ] l_{n,c}=-\omega_{n,c} \begin{bmatrix}p_c y_{n,c}\cdot \log x_{n,c} +(1-y_{n,c}) \cdot \log(1-x_{n,c})\end{bmatrix}l n ,c =−ωn ,c [p c y n ,c ⋅lo g x n ,c +(1 −y n ,c )⋅lo g (1 −x n ,c )]
其中ω \omega ω为调节不同属性的重要性,例如我希望模型更倾向于红色翅膀属性预测的正确性,可以在该类下调大比例。p p p为调节正负样本均衡的参数,例如在红色翅膀属性下,有100个正例,400个负例,则在该属性下的p p p我们可以设置为:400 100 = 4 \frac{400}{100}=4 1 0 0 4 0 0 =4。在 Pytorch框架中函数 torch.nn.BCEWithLogitsLoss实现了该功能,其中ω \omega ω对应超参w e i g h t weight w e i g h t,p p p对应超参 pos_weight。更多细节见BCEWithLogitsLoss。
3. 视觉属性预测
基于深度学习的视觉属性通常预测方法包括 多标签分类与 多任务学习,在TPAMI 2018一篇文章中提到:
Attribute learning problem can be formulated in the multi-task learning framework, where each task corresponds to learning one semantic attribute.
属性学习问题可以在多任务学习框架中形成,每个任务对应学习一个语义属性。
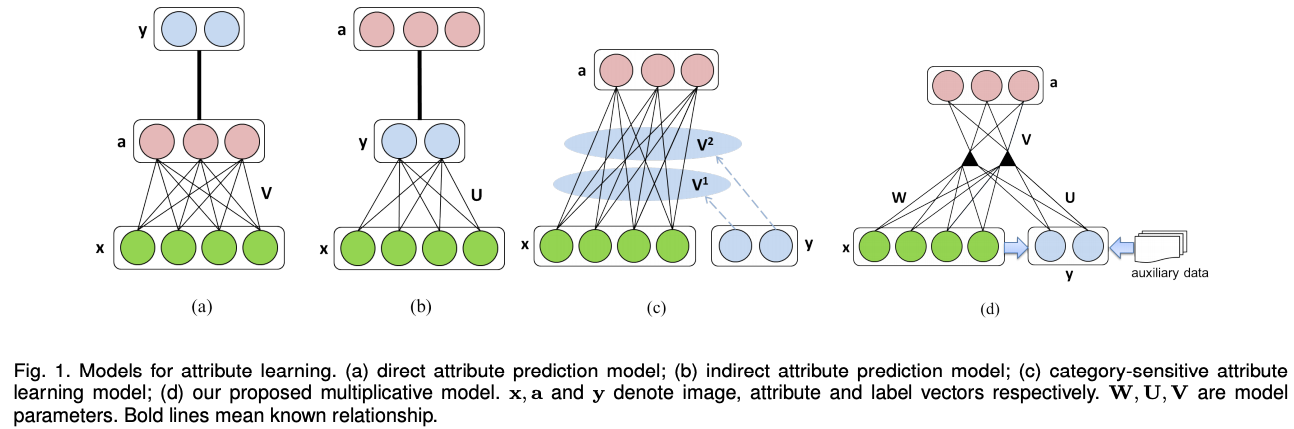
即可以在最后一层连接多个softmax二分类层或者用Sigmoid激活向量做多属性预测,通常其也会加入原物体类别信息,这样是防止偏见性。例如海豹在海水中,蓝色并不能作为海豹的属性,加入人为先验会更好一些,当然也可以直接进行属性预测。
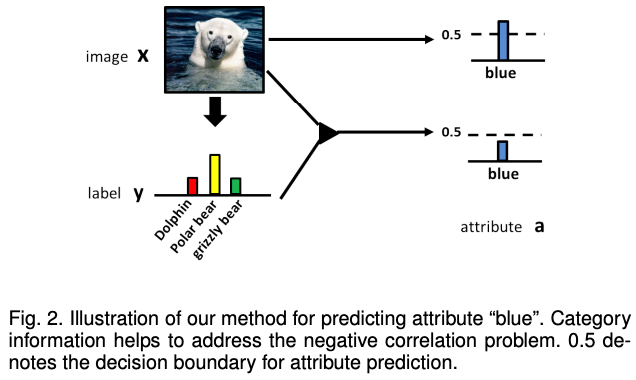
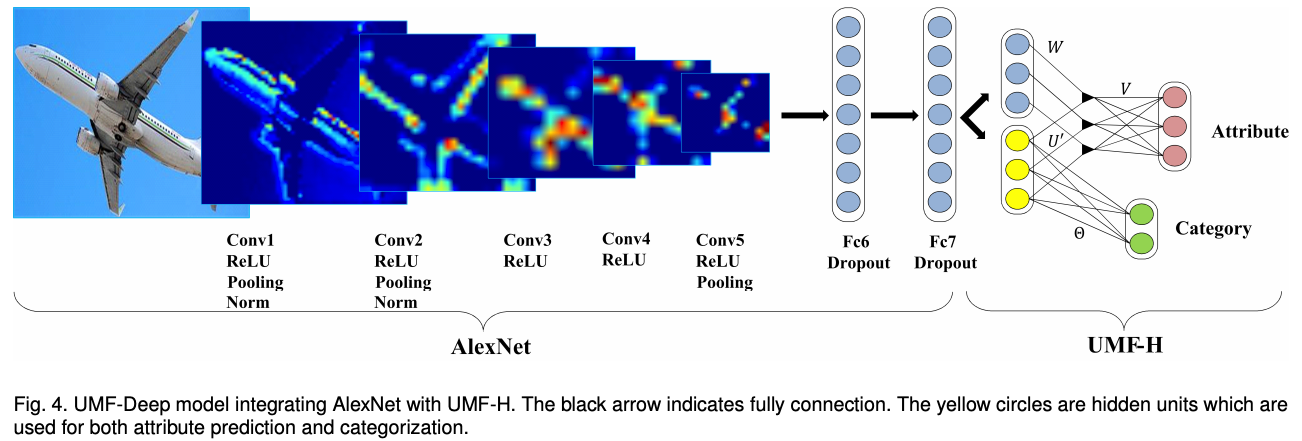
在论文MAAD-Face: A Massively Annotated Attribute Dataset for Face Images中提供了人脸属性的标注,数据集来源于VGGFace2,在该数据集上训练了一个人脸属性模型,具体便是采用
多任务学习的方法。Backbone便采用了Resnet50,最后的特征共享,并行输出多个全连接层。例如性别一栏,人只有男女之分,因此我不需要对男女进行二分类,而是直接分类性别,非男即女。种族也是,只有黄种人,白种人和黑种人,这个分支只输出3类。而人的胡子却不一样,有的人会同时有山羊胡和痄腮胡等,因此需要多个二分网络,最终将多个任务的交叉熵loss直接求和即可。这里值得提及一下pytorch的多输出网络方便的实现方法,以及多任务交叉熵Loss的写法,首先大概展示下网络的架构,与论文Multi-task deep neural network for multi-label learning中一个架构相似,如下图(a)所示:
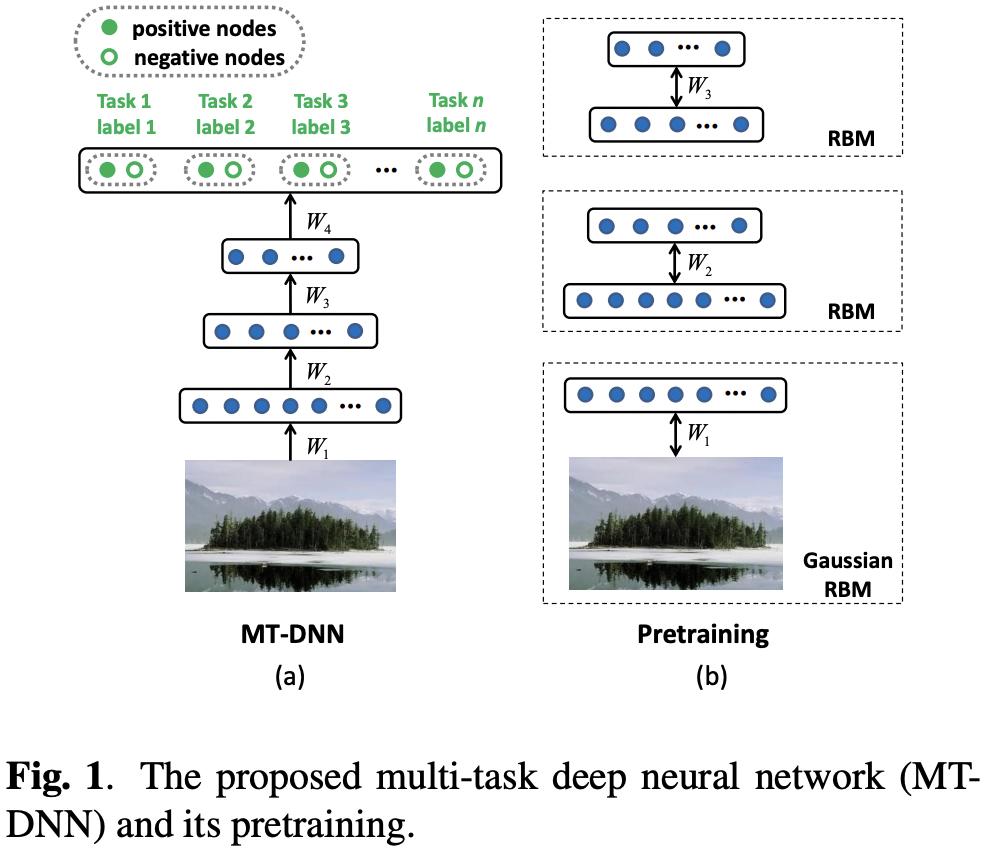
下方代码主要部分是函数 _make_multi_output,这里需要注意的是 nn.ModuleList,因为循环中没有顺序,所以不能用 nn.Sequential。如果不加 nn.ModuleList而只用列表存储,则在 model.cuda时不会将列表中的模型参数放入GPU,因为列表不会被识别为pytorch的方法。
class ResNet(nn.Module):
def __init__(self, block, layers, attribute_classes):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.layers = self._make_multi_output(block, attribute_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 0.001)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def _make_multi_output(self,block,attribute_classes):
"""
Created by Ruoyu Chen on 07/15/2021
"""
layers = []
for i in range(attribute_classes):
layers.append(nn.Linear(512*block.expansion, 2))
return nn.ModuleList(layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
outs = []
for layer in self.layers:
outs.append(layer(x))
return outs
损失函数需要注意的是outs和labels的shape:
class MultiBranchLabelLoss(nn.Module):
def __init__(self):
super(MultiBranchLabelLoss, self).__init__()
self.criterion = nn.CrossEntropyLoss()
def forward(self, outs, labels):
"""
outs: List[Torch_size(batch,2)]
labels: Torch_size(batch, attributes)
"""
loss = 0
for out,label in zip(outs,labels.t()):
criterion_loss = self.criterion(out, label)
loss += criterion_loss
return loss
4. 物体检测的属性数据集
最早的关于物体检测中的属性分布,原网站https://vision.cs.uiuc.edu/attributes/,基于Pasc VOC2008标注,2009年的一篇文章。
最新根据CVPR2021的一篇文章Learning To Predict Visual Attributes in the Wild的统计,有如下的最新的物体检测相关属性数据集:
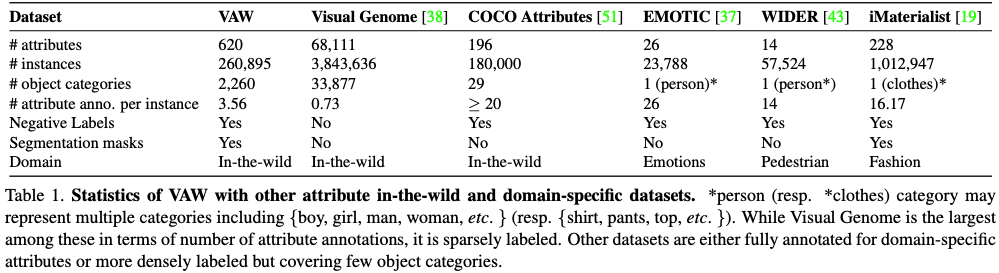
; 5. 多任务学习
Multitask Learning: A Knowledge-Based Source of Inductive Bias
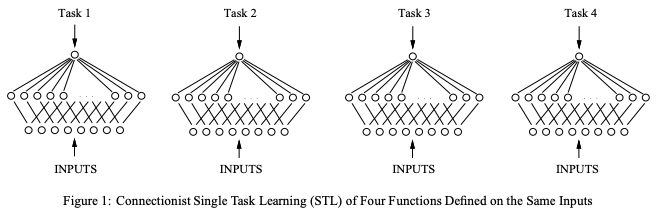
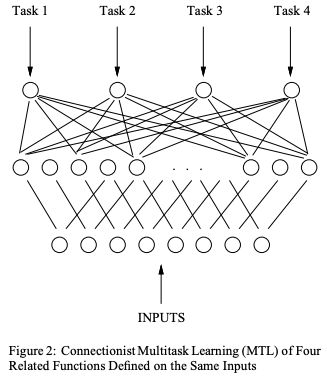
; 6. 根据多标签学习训练Pasc VOC2008属性
首先,根据pasc voc2008数据集,下载:https://www.kaggle.com/sulaimannadeem/pascal-voc-2008
代码及结果请见我的github:https://github.com/RuoyuChen10/Multi-label-on-VOC2008-attributes
Original: https://blog.csdn.net/Exploer_TRY/article/details/118910514
Author: CExploer
Title: 多标签分类与多任务学习
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/665282/
转载文章受原作者版权保护。转载请注明原作者出处!