

前言
quickdraw数据集是序列数据集,包含画画的动作等信息。我将quickdraw数据集转换成黑底白字的png图片,对其做多分类。本文使用pytorch,和预训练过的resnet50深度神经网络。


导包
from glob import glob
import os
import numpy as np
import matplotlib.pyplot as plt
import shutil
from torchvision import transforms
from torchvision import models
import torch
from torch.autograd import Variable
import torch.nn as nn
from torch.optim import lr_scheduler
from torch import optim
from torchvision.datasets import ImageFolder
from torchvision.utils import make_grid
import time
%matplotlib inline
数据集处理
将数据集处理成三个文件夹:train,valid,test
每个文件夹下面有n个分类文件夹,每个分类文件夹下面是对应的图片。
读取文件夹内的文件
path = 'data/image345/'
files = glob.glob(os.path.join(path,'*/*.png'))
#创建保存验证图片集的valid/train/test的目录
path2 = 'data/'
os.mkdir(path2 )
os.mkdir(os.path.join(path2 ,'valid'))
os.mkdir(os.path.join(path2 ,'train'))
os.mkdir(os.path.join(path2 ,'test'))
获取所有标签类别
fileslist = [f for f in os.listdir(path)]
#使用标签名称创建目录
for t in ['train','valid','test']:
for folder in fileslist:
os.mkdir(os.path.join(path2,t,folder))
test:valid:train 1:1:8
for folder in fileslist:
path = 'data/'
path = os.path.join(path,folder)
# 获取到该文件夹下面的200张图片
files = glob.glob(os.path.join(path,'*.png'))
images_num = len(files)
#创建可用于创建验证数据集的混合索引
shuffle = np.random.permutation(images_num)
# 将图片的一小部分子集复制到valid文件夹
for i in shuffle[:100]:
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join('data/valid',folder,image))
# 将图片的一小部分子集复制到train文件夹
for i in shuffle[100:900]:
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join('data/train',folder,image))
for i in shuffle[900:]:
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join('data/test',folder,image))
获取数据
batchsize设置为32(因为我的gpu只要8G,在大就爆栈了,留下了穷逼的眼泪!),图片裁剪为224*224
if torch.cuda.is_available():
is_cuda = True
simple_transform = transforms.Compose([transforms.Resize((224,224))
,transforms.ToTensor()
,transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
train = ImageFolder('data/train',simple_transform)
valid = ImageFolder('data/valid',simple_transform)
test = ImageFolder('data/test',simple_transform)
train_data_gen = torch.utils.data.DataLoader(train,shuffle=True,batch_size=32,num_workers=3)
valid_data_gen = torch.utils.data.DataLoader(valid,batch_size=32,num_workers=3)
test_data_gen = torch.utils.data.DataLoader(test ,batch_size=32,num_workers=3)
dataset_sizes = {'train':len(train_data_gen.dataset),'valid':len(valid_data_gen.dataset),'test':len(test_data_gen )}
dataloaders = {'train':train_data_gen,'valid':valid_data_gen,'test':test_data_gen }
深度神经网络
model_ft = models.resnet50(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 345)
超参数
交叉熵损失函数
criterion = nn.CrossEntropyLoss()
优化器
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.01, momentum=0.9)
自动调整学习率
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)
训练函数
def train_model(model, criterion, optimizer, scheduler, device, num_epochs=5):
model.to(device)
print('training on', device)
since = time.time()
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
for phase in ['train', 'valid']:
s = time.time()
if phase == 'train':
scheduler.step()
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for data in dataloaders[phase]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if torch.cuda.is_available():
inputs = Variable(inputs.to(device))
labels = Variable(labels.to(device))
else:
inputs, labels = Variable(inputs), Variable(labels)
if phase == 'train':
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# statistics
running_loss += loss.data
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
if phase == 'valid':
val_losses.append(epoch_loss)
val_accuracy.append(epoch_acc)
if phase == 'train':
train_lossed.append(epoch_loss)
train_accuracy.append(epoch_acc)
print('Epoch {}/{} - {} Loss: {:.4f} Acc: {:.4f} Time:{:.1f}s'.format(
epoch + 1, num_epochs, phase, epoch_loss, epoch_acc,
time.time() - s))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
if phase == 'train':
scheduler.step()
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
选择GPU函数
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
开始训练
train_lossed, train_accuracy = [], []
val_losses, val_accuracy = [], []
model_ft = train_model(model_ft,
criterion, optimizer_ft, exp_lr_scheduler, try_gpu(0), num_epochs=10)
画图
plt.plot(range(1, len(train_lossed)+1),train_lossed, 'b', label='training loss')
plt.plot(range(1, len(val_losses)+1), val_losses, 'r', label='val loss')
plt.legend()
plt.plot(range(1,len(train_accuracy)+1),train_accuracy,'b--',label = 'train accuracy')
plt.plot(range(1,len(val_accuracy)+1),val_accuracy,'r--',label = 'val accuracy')
plt.legend()
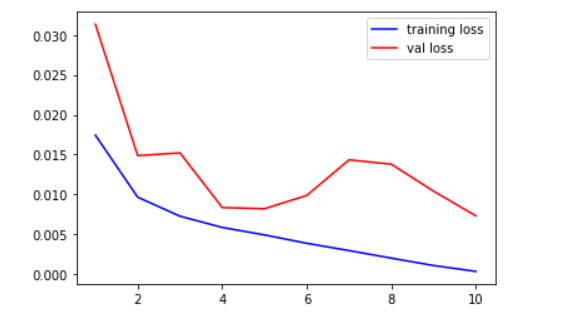

测试
def data_test(model, criterion, device):
model.to(device)
print('Testing on', device)
s = time.time()
model.eval()
running_loss = 0.0
running_corrects = 0
# Iterate over data.
phase = "test"
for data in dataloaders["test"]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if torch.cuda.is_available():
inputs = Variable(inputs.to(device))
labels = Variable(labels.to(device))
else:
inputs, labels = Variable(inputs), Variable(labels)
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
# statistics
running_loss += loss.data
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
print('Loss: {:.4f} Acc: {:.4f} Time:{:.1f}s'.format(
epoch_loss, epoch_acc,
time.time() - s))
model_ft = train_model(model_ft, criterion, try_gpu(1))
保存模型
torch.save(model_ft, 'data/models/net50.pth')
分析
数据集为345类,每类取了200张图片。最终把测试精度训练到70左右,还是有提升空间。
提升策略:
1、 优化数据集,每类取1000张图片。
2、做数据增强。加噪音,随机翻转,变颜色,图片叠加等操作
3、优化深度神经网络resnet50,可以使用更深的网络,比如resnet101.Original: https://blog.csdn.net/qq_42391248/article/details/122113643
Author: Wonder-King
Title: 使用ResNet50对QuickDraw数据集做图像分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664589/
转载文章受原作者版权保护。转载请注明原作者出处!