

题目:
1.已知一个文本集合为:
[[‘my’, ‘dog’,’has’,’false’,’problems’,’help’,’please’],
[‘maybe’,’not’,’take’,’him’,’to’,’dog’,’park’,’stupid’],
[‘my’,’dalmation’,’is’,’so’,’cute’,’I’,’love’,’him’,’my’],
[‘stop’,’posting’,’stupid’,’worthless’,’garbage’], [‘mr’,’licks’,’ate’,’my’,’steak’,’how’,’to’,’stop’,’him’],
[‘quit’,’buying’,’worthless’,’dog’,’food’,’stupid’]]
此数据集有6个文本,其对应标签为classVec={0,1,0,1,0,1},标签为1表示此文本带有侮辱性词语,否则标签为0。要求:
(1)得到数据集的所有出现的单词构成的无重复词的词典。即为:
[‘cute’, ‘love’, ‘help’, ‘garbage’, ‘quit’, ‘I’, ‘problems’, ‘is’, ‘park’, ‘stop’, ‘flea’, ‘dalmation’, ‘licks’, ‘food’, ‘not’, ‘him’, ‘buying’, ‘posting’, ‘has’, ‘worthless’, ‘ate’, ‘to’, ‘maybe’, ‘please’, ‘dog’, ‘how’, ‘stupid’, ‘so’, ‘take’, ‘mr’, ‘steak’, ‘my’]
(2)根据词典将原始的6个文本表示成0或1数字构成的词向量形式。例如,第一个文本对应的词向量为:
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]
(3)利用朴素贝叶斯分类模型。
(4)现有两个文本:[‘love’, ‘my’, ‘dalmation’], [‘stupid’, ‘garbage’],用(3)得到的朴素贝叶斯分类器对其进行分类,即给出其标签为0(非侮辱性文本)或1(侮辱性文本)。
2.在(1)-(4)的基础上,对给出的50个邮件,其中25个垃圾邮件,25个非垃圾邮件进行分类,随机选取20个垃圾邮件和20个非垃圾邮件作为训练集,剩余10个文本为测试集,用训练集文本得到朴素贝叶斯文本分类器的多项式模型或贝努力模型,然后对测试集文本进行测试,得到其accuracy值。
步骤:
代码如下:
from numpy import*
def loadDataSet():
postingList=[
['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','dog','part','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']
]
classVec=[0,1,0,1,0,1]
return postingList,classVec
def createVocabList(dataSet):
vocabSet=set([])
for document in dataSet:
vocabSet=vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList,inputSet):
returnVec=[0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]=1
else:
print("the word: %s is not in my Vocabulary!" %word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix)
numWords=len(trainMatrix[0])
pAbusive=sum(trainCategory)/float(numTrainDocs)
p0Num=ones(numWords);p1Num=ones(numWords)
p0Denom=2.0;p1Denom=2.0
for i in range(numTrainDocs):
if trainCategory[i]==1:
p1Num+=trainMatrix[i]
p1Denom+=sum(trainMatrix[i])
else:
p0Num+=trainMatrix[i]
p0Denom+=sum(trainMatrix[i])
p1Vect=log(p1Num/p1Denom)
p0Vect=log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1=sum(vec2Classify*p1Vec)+log(pClass1)
p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
def testingNB():
listOposts,listClasses=loadDataSet()
myVocablist=createVocabList(listOposts)
print(myVocablist)
trainMat=[]
for postinDoc in listOposts:
trainMat.append(setOfWords2Vec(myVocablist, postinDoc))
p0V,p1V,pAb=trainNB0(trainMat,listClasses)
testEntry=['love','my','dalmation']
thisDoc=array(setOfWords2Vec(myVocablist, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc, p0V, p1V,pAb))
testEntry=['stupid','garbge']
thisDoc=array(setOfWords2Vec(myVocablist, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc, p0V, p1V,pAb))
def textParse(bigString):
import re
listOftokens=re.split(r'\w*',bigString)
return [tok.lower() for tok in listOftokens if len(tok)>2]
def spamTest():
docList=[]
classList=[]
for i in range(1,26):
wordList=textParse(open('E:/pywork/test/sy-7/email/spam/%d.txt' %i).read())
docList.append(wordList)
classList.append(1)
wordList=textParse(open('E:/pywork/test/sy-7/email/ham/%d.txt' %i).read())
docList.append(wordList)
classList.append(0)
vocabList=createVocabList(docList)
trainingSet=list(range(50))
testSet=[]
times=0
while True:
randIndex=int(random.uniform(0,len(trainingSet)))
if classList[trainingSet[randIndex]]==1:
testSet.append(trainingSet[randIndex])
del (trainingSet[randIndex])
times +=1
if times==5:
break
while True:
randIndex=int(random.uniform(0,len(trainingSet)))
if classList[trainingSet[randIndex]]==0:
testSet.append(trainingSet[randIndex])
del (trainingSet[randIndex])
times+=1
if times==10:
break
trainMat=[];trainClasses=[]
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses))
rightCount=0
for docIndex in testSet:
wordVector=setOfWords2Vec(vocabList,docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam)==classList[docIndex]:
rightCount+=1
return float(rightCount)/len(testSet)
def multiTest():
numTests=10;rightSum=0.0
for k in range(numTests):
rightSum += spamTest()
testingNB()
multiTest()
运行结果:
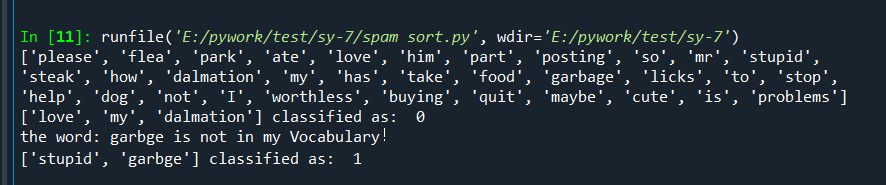

Original: https://blog.csdn.net/weixin_45652976/article/details/122530659
Author: Y_ni
Title: python—利用朴素贝叶斯分类器对文本进行分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664441/
转载文章受原作者版权保护。转载请注明原作者出处!