

请采用决策树的集成学习方法——随机森林完成第三次作业中, 对男女生样本数据中的(喜欢颜色,喜欢运动,喜欢文学)3 个特征进行分类,计算模型预测性能(包含 SE、SP、ACC),并以友好的方式图示化结果,与决策树分类的结果进行比较。
目录
1.调节随机森林的参数
1.1调n_estimators参数
本文先找出用几棵树模型的表现最好。首先,找到这个n_estimators最值的大概区间。为了观察得分随着树增多的变化,绘制决策树调参时的学习曲线如图。
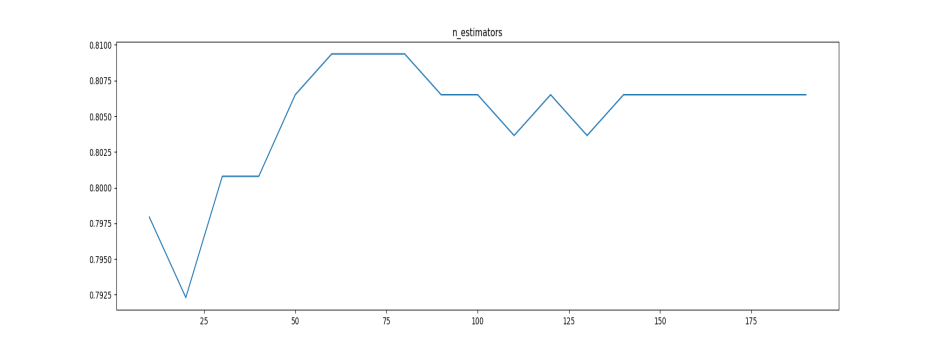

图1
最优参数以及最高得分: [60.000, 0.809]
根据曲线,本文进一步缩小范围,搜索50~80之间的得分。
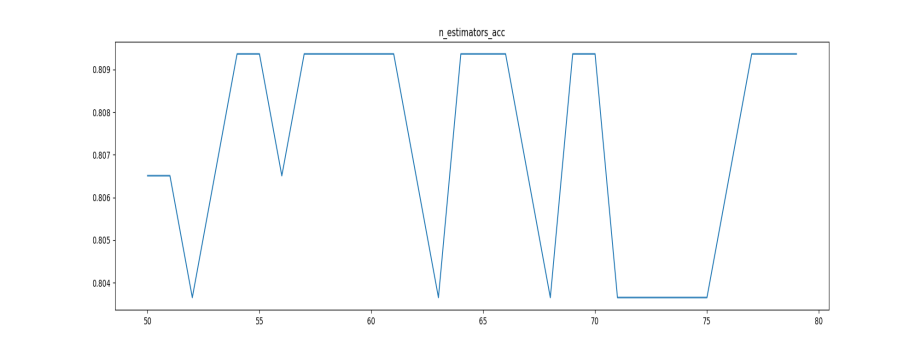
图2
最优参数以及最高得分: [54. 000, 0.809]
可以看到,54为得分最高点,我们暂定n_estimators为54,接着调下边的参数。
1.2探索max_depth(树的最大深度)最佳参数
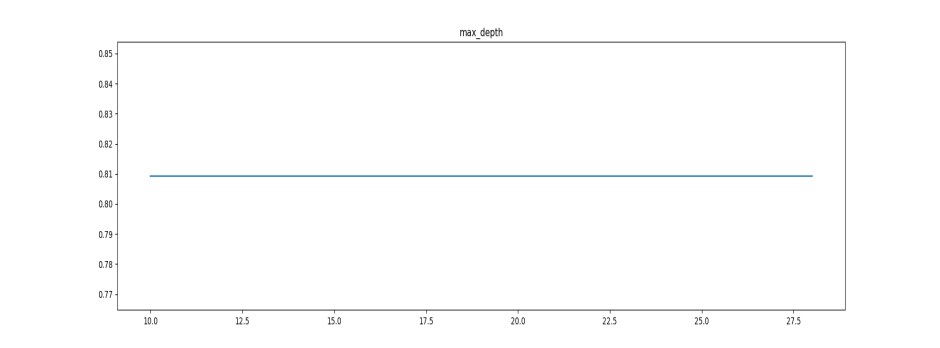
图3
最优参数以及最高得分: [10.000, 0.809]
10之后一直没有变化,可以说明就算不限制,所有树的最大深度也就是10左右,因为我们以步长为3搜索的,所以还需要进一步搜索一下10附近的值。精细搜索之后发现,10这个值就是转折点,所以暂定max_depth = 10。
1.3 min_samples_split
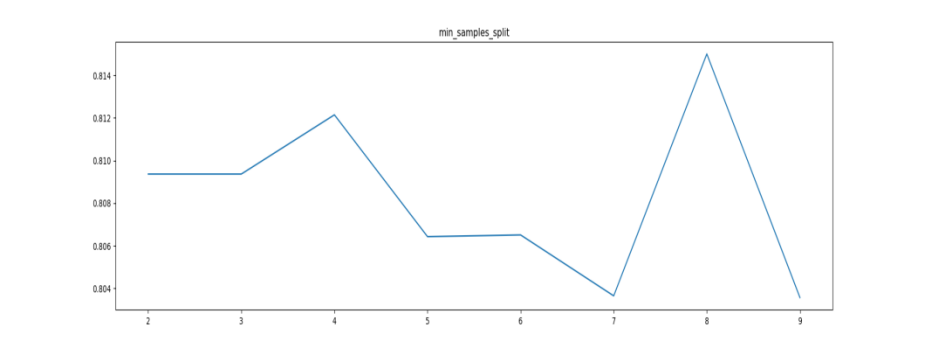
图4
最优参数以及最高得分: [8.000, 0.815]
可以看到,随着min_samples_split增大,模型得分在4和8处有两个峰值,因此min_samples_split暂定8。
1.4 min_samples_leaf
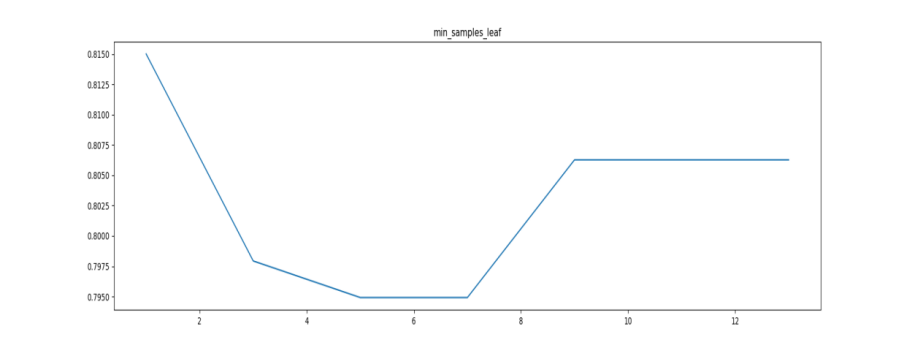
图5
最优参数以及最高得分: [1.000, 0.815]
因此,随机森林最优参数可设定如下表1
n_estimators
max_depth
min_samples_split
min_samples_leaf
Best value
54
10
8
1
Score
0.809
0.809
0.815
0.815
表1
2.模型预测性能
2.1 SE、SP、ACC
敏感性SE
特异性SP
准确率ACC
Decision Tree
0.942
0.300
0.821
Random Forest
0.857
0.200
0.764
表2
- 由表2可知,ACC准确率,决策树和随机森林能够正确预测的样本总数的82.1%和76.4%;由敏感性SE可知,两模型对男生(正样本)的预测正确率高达94.2%和85.7%;而由特异性SP可知,两模型对女生(负样本)的分类正确率只有30%和20%,这可能是在模型训练的过程中,女生(负样本)数量过少,导致训练的模型不够准确,因而正确率不高。
2.2决策树随机森林分类效果对比
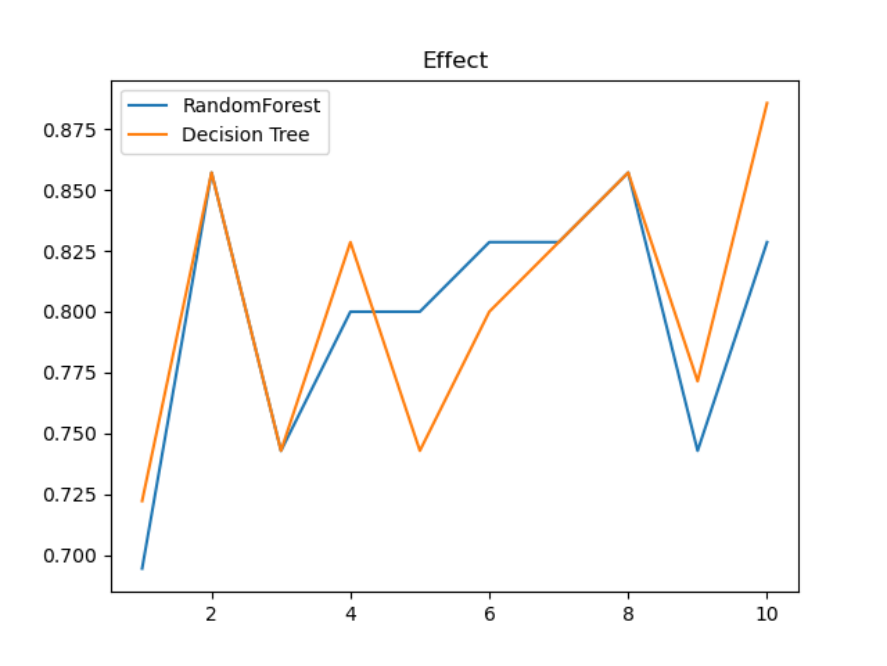
图6 随机森林和决策树在一组交叉验证下的效果对比
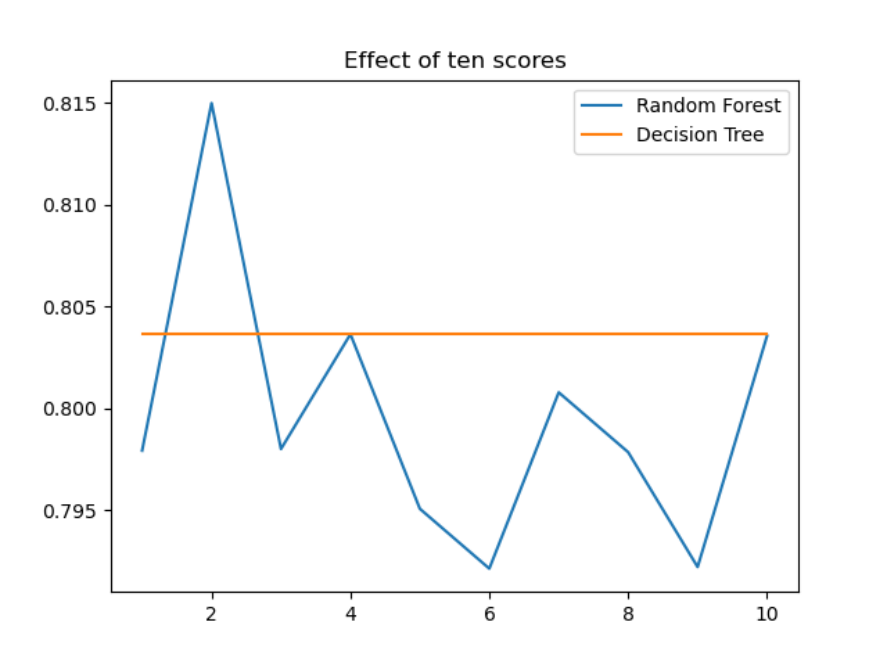
图7 随机森林和决策树在 十 组交叉验证下的效果对比
由图6可知单个决策树的准确率越高,随机森林的准确率也会越高。由图7 可知决策树分类的分数非常稳定,而随机森林非常不稳定,变化幅度很大。
2.3 分类评分
采用score函数对随机森林与决策树进行分数比对,随机森林设定最优参数如表1,决策树设定与随机森林相似,比对结果如下。
SingleTree
Random Forest
0.830
0.764
表3
由表2,3,图6,7知,总体来说,决策树的分类表现要优于随机森林,这可能是由于以下两点:
(1)某些数据集没有训练到,导致分类结果不如决策树;
(2)颜色属性取值划分较多 ,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种颜色特征上产出的属性权值是不可信的。
3.随机森林可视化
本次实验共设定54颗子决策树,其中的一棵子决策树如图8所示。
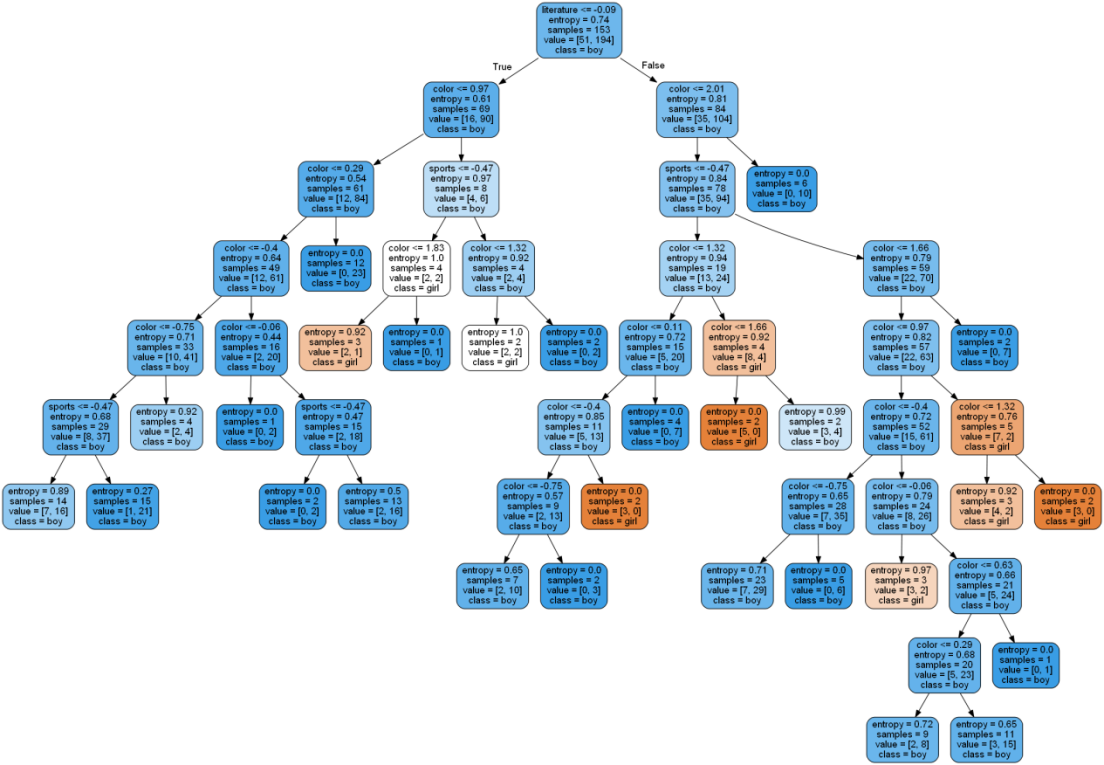
图8 随机森林子决策树
代码
随机森林参数调节
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
Importing the dataset
data = pd.read_csv('data_favorite.txt', header=0, sep=' ')
处理非数字
data["color"] = pd.factorize(data["color"])[0].astype(np.uint16)
X = data.iloc[:, data.columns != "sex"]
y = data.iloc[:, data.columns == "sex"]
RF = RandomForestClassifier(random_state = 66)
score = cross_val_score(RF,X,y,cv=10).mean()
print('交叉验证得分: %.4f'%score)
'''
调n_estimators参数
ScoreAll = []
for i in range(10,200,10):
DT = RandomForestClassifier(n_estimators=i,random_state=66) #,criterion = 'entropy'
score = cross_val_score(DT, X, y,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.title('n_estimators')
plt.savefig("n_estimators")
plt.show()
进一步缩小范围,调n_estimators参数
ScoreAll = []
for i in range(50,80):
DT = RandomForestClassifier(n_estimators=i,random_state = 66) #criterion = 'entropy',
score = cross_val_score(DT, X, y, cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.title('n_estimators_acc')
plt.savefig("n_estimators_acc")
plt.show()
粗调max_depth参数
ScoreAll = []
for i in range(10,30,3):
DT = RandomForestClassifier(n_estimators = 54,random_state = 66,max_depth =i ) #,criterion = 'entropy'
score = cross_val_score(DT, X, y, cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.title('max_depth')
plt.savefig("max_depth")
plt.show()
###调min_samples_split参数
ScoreAll = []
for i in range(2,10):
RF = RandomForestClassifier(n_estimators =54,random_state = 66,max_depth =10,min_samples_split = i ) #,criterion = 'entropy'
score = cross_val_score(RF,X, y,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.title('min_samples_split')
plt.savefig("min_samples_split")
plt.show()
'''
###调min_samples_leaf参数
ScoreAll = []
for i in range(1,15,2):
DT = RandomForestClassifier(n_estimators = 54,random_state = 66,max_depth =10,min_samples_leaf = i,min_samples_split = 8 )
score = cross_val_score(DT,X ,y, cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.title('min_samples_leaf')
plt.savefig("min_samples_leaf")
plt.show()
随机森林模型预测与可视化
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.ensemble import RandomForestClassifier # 集成学习中的随机森林
Importing the dataset
data = pd.read_csv('data_favorite.txt', header=0, sep=' ')
处理非数字
data["color"] = pd.factorize(data["color"])[0].astype(np.uint16)
feature_names = ['sports', 'literature']
X = data[feature_names].values
X = data.iloc[:, data.columns != "sex"]
y = data.iloc[:, data.columns == "sex"]
首先将pandas读取的数据转化为array
X = np.array(X)
y = np.array(y)
Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
Feature Scaling 特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler() # 归一化
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
调试训练集的随机森林
clf = DecisionTreeClassifier(criterion='gini', random_state=66)
rfc = RandomForestClassifier(n_estimators=54, criterion='gini', random_state=66)
clf.fit(X_train, y_train) # ravel()方法将数组维度拉成一维数组
rfc.fit(X_train, y_train)
***********************************************************************
score_c = clf.score(X_test, y_test) # 是精确度
score_r = rfc.score(X_test, y_test)
print('Single Tree:{}'.format(score_c)
,'Random Forest:{}'.format(score_r)) # format是将分数转换放在{}中
4. 画出随机森林和决策树在一组交叉验证下的效果对比
交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=54)
rfc_s = cross_val_score(rfc, X, y, cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, X, y, cv=10)
plt.plot(range(1, 11), rfc_s, label="RandomForest")
plt.plot(range(1, 11), clf_s, label="Decision Tree")
plt.legend()
plt.title('Effect')
plt.savefig("Effect of R_Forest_D_Tree")
plt.show()
5. 画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=54)
rfc_s = cross_val_score(rfc, X, y, cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, X, y, cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1, 11), rfc_l, label="Random Forest")
plt.plot(range(1, 11), clf_l, label="Decision Tree")
plt.legend()
plt.title('Effect of ten scores')
plt.savefig("Effect of ten scores")
plt.show()
****************************************************************
根据真实值和预测值计算评价指标SE, SP, ACC
def performance(labelArr, predictArr): # 样本一定要是数组narray类型 类标签为1,0 # labelArr[i]真实的类别,predictArr[i]预测的类别
# labelArr[i] is actual value,predictArr[i] is predict value
TP = 0.; TN = 0.; FP = 0.; FN = 0.
for i in range(len(labelArr)):
if labelArr[i] == 1 and predictArr[i] == 1:
TP += 1.
elif labelArr[i] == 1 and predictArr[i] == 0:
FN += 1.
elif labelArr[i] == 0 and predictArr[i] == 1:
FP += 1.
elif labelArr[i] == 0 and predictArr[i] == 0:
TN += 1.
SE = TP / (TP + FN) # Sensitivity = TP/P and P = TP + FN
SP = TN / (FP + TN) # Specificity = TN/N and N = TN + FP
# MCC = (TP * TN - FP * FN) / math.sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN))
ACC = (TP + TN) / (TP + TN + FP + FN)
return SE, SP, ACC
y_pred = rfc.predict(X_test)
print(performance(y_test, y_pred)) # 测试集特征经过决策树判断出的标签与测试集实际标签输入performance
Making the Confusion Matrix 混淆矩阵评估模型性能
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
import os
from sklearn.tree import export_graphviz
data_feature_names = ['color', 'sports', 'literature']
循环打印每棵树
for idx, estimator in enumerate(rfc.estimators_):
# 导出dot文件
export_graphviz(estimator,
out_file='tree{}.dot'.format(idx),
feature_names=data_feature_names,
class_names=['girl', 'boy'],
rounded=True,
proportion=False,
precision=2,
filled=True)
# 转换为png文件
os.system('dot -Tpng tree{}.dot -o tree{}.png'.format(idx, idx))
Original: https://blog.csdn.net/weixin_43793397/article/details/121964500
Author: 是阿晨啊leo
Title: 随机森林 分类 预测性能SE,SP,ACC 与决策树比较
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664153/
转载文章受原作者版权保护。转载请注明原作者出处!