

在多分类问题中,我们常常使用softmax作为输出层函数。下面来介绍softmax函数。
1 softmax数学形式:
通过数学表达式,我们可以看到,softmax函数将向量映射为一个概率分布(0,1)对于n维向量最后映射为n维的概率分布。
σ ( x ) i = e x p ( x i ) ∑ j = 1 n e x p ( x j ) \sigma(x)i=\frac{exp(x_i)}{\sum{j=1}^{n}exp(x_j)}σ(x )i =∑j =1 n e x p (x j )e x p (x i )
在n分类问题中,神经网络的输出元有n个,将n个输出值作为softmax的输入,即可以得到n个概率分布,对应位置就是第n类的预测概率。可以看下例讲解:
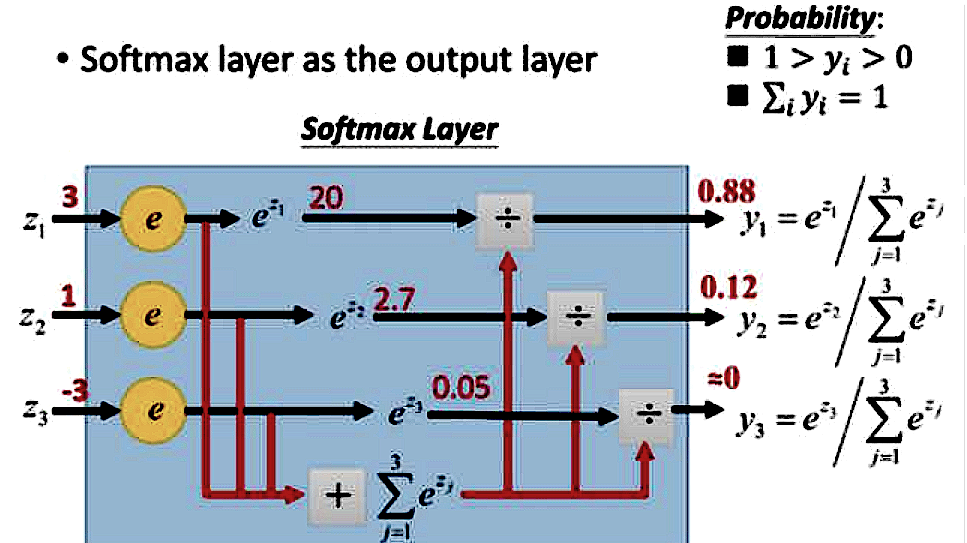

; 2 损失函数——为什么是交叉熵/对数损失函数?
交叉熵最早起源于信息论,1948 年,香农提出了”信息熵”(shāng) 的概念,才解决了对信息的量化度量问题。关于信息论和交叉熵的解读,可以看我这篇文章 从信息熵到交叉熵
根据交叉熵的公式,我们可以衡量两个概率分布之间的相似度.。因此在多分类问题中,使用交叉熵函数可以刻画输出概率和实际标签的相似度。
H ( p , q ) = − ∑ p ( x ) l o g ( q ( x ) ) H(p,q)=-\sum p(x)log(q(x))H (p ,q )=−∑p (x )l o g (q (x ))
所以在多分类问题中,我们通过softmax函数得到一个n维概率分布( p 1 , p 2 , . . . , p n ) (p_1,p_2,…,p_n)(p 1 ,p 2 ,…,p n ),对于实际的标签向量y = ( 0 , 0 , . . . , 1 , 0 ) y=(0,0,…,1,0)y =(0 ,0 ,…,1 ,0 ),使用交叉熵损失函数就可以得到我们的输出层的目标函数。
L o s s C r o s s E n t r o p y = − ∑ i y i l n ( σ ( x ) i ) Loss_{Cross Entropy} = -\sum _iy_iln(\sigma(x)_i)L o s s C r o s s E n t r o p y =−i ∑y i l n (σ(x )i )
实际中,由于我们的标签是类别,只有一个维度是1,所以上面的求和符号可以省去,改写为:
L o s s = − l n ( σ ( x ) k ) Loss = -ln(\sigma(x)_k)L o s s =−l n (σ(x )k )
通过梯度下降反向传播。即完成整个神经网络的参数更新。
∂ Loss ∂ x j = ∂ ( − ln ( σ ( x ) k ) ) ∂ σ ( x ) k ⋅ ∂ σ ( x ) k ∂ x j = − 1 σ ( x ) k ⋅ ∂ σ ( x ) k ∂ x j = { σ ( x ) j − 1 , j = k σ ( x ) j , j ≠ k \frac{\partial \text { Loss }}{\partial x_{j}}=\frac{\partial\left(-\ln \left(\sigma(\boldsymbol{x}){k}\right)\right)}{\partial \sigma(\boldsymbol{x}){k}} \cdot \frac{\partial \sigma(\boldsymbol{x}){k}}{\partial x{j}}=-\frac{1}{\sigma(\boldsymbol{x}){k}} \cdot \frac{\partial \sigma(\boldsymbol{x}){k}}{\partial x_{j}}=\left{\begin{array}{l} \sigma(\boldsymbol{x}){j}-1, j=k \ \sigma(\boldsymbol{x}){j}, j \neq k \end{array}\right.∂x j ∂Loss =∂σ(x )k ∂(−ln (σ(x )k ))⋅∂x j ∂σ(x )k =−σ(x )k 1 ⋅∂x j ∂σ(x )k ={σ(x )j −1 ,j =k σ(x )j ,j =k
Softmax+Cross Entropy的结合不仅在数学进行了完美的定义,而且整个表达式十分简洁。
3 举个例子
对于n=3,期望输出p=(1,0,0),实际输出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1)
H ( p , q 1 ) = − ( 1 × log 0.5 + 0 × log 0.2 + 0 × log 0.3 ) H ( p , q 1 ) = 0.3 H ( p , q 2 ) = − ( 1 × log 0.8 + 0 × log 0.1 + 0 × log 0.1 ) H ( p , q 2 ) = 0.1 \begin{aligned} &H\left(p, q_{1}\right)=-\left(1 \times \log ^{0.5}+0 \times \log ^{0.2}+0 \times \log ^{0.3}\right) \ &H\left(p, q_{1}\right)=0.3 \ &H\left(p, q_{2}\right)=-\left(1 \times \log ^{0.8}+0 \times \log ^{0.1}+0 \times \log ^{0.1}\right) \ &H\left(p, q_{2}\right)=0.1 \end{aligned}H (p ,q 1 )=−(1 ×lo g 0 .5 +0 ×lo g 0 .2 +0 ×lo g 0 .3 )H (p ,q 1 )=0 .3 H (p ,q 2 )=−(1 ×lo g 0 .8 +0 ×lo g 0 .1 +0 ×lo g 0 .1 )H (p ,q 2 )=0 .1
p2和实际值q更接近。
对于交叉熵公式,还可以改写成以下形式:
H ( p , q ) = − ∑ x ( p ( x ) log q ( x ) + ( 1 − p ( x ) ) log ( 1 − q ( x ) ) ) H(p, q)=-\sum_{x}(p(x) \log q(x)+(1-p(x)) \log (1-q(x)))H (p ,q )=−x ∑(p (x )lo g q (x )+(1 −p (x ))lo g (1 −q (x )))
其结果为:
H ( p , q 1 ) = − ( 1 × log 0.5 + 0 × log 0.2 + 0 × log 0.2 + 0 × log 0.5 + 1 × log 0.8 + 1 × log 0.7 ) H ( p , q 1 ) = 0.55 H ( p , q 2 ) = − ( 1 × log 0.8 + 0 × log 0.1 + 0 × log 0.1 + 0 × log 0.2 + 1 × log 0.9 + 1 × log 0.9 ) H ( p , q 2 ) = 0.19 \begin{aligned} &H\left(p, q_{1}\right)=-\left(1 \times \log ^{0.5}+0 \times \log ^{0.2}+0 \times \log ^{0.2}+0 \times \log ^{0.5}+1 \times \log ^{0.8}+1 \times \log ^{0.7}\right) \ &H\left(p, q_{1}\right)=0.55 \ &H\left(p, q_{2}\right)=-\left(1 \times \log ^{0.8}+0 \times \log ^{0.1}+0 \times \log ^{0.1}+0 \times \log ^{0.2}+1 \times \log ^{0.9}+1 \times \log ^{0.9}\right) \ &H\left(p, q_{2}\right)=0.19 \end{aligned}H (p ,q 1 )=−(1 ×lo g 0 .5 +0 ×lo g 0 .2 +0 ×lo g 0 .2 +0 ×lo g 0 .5 +1 ×lo g 0 .8 +1 ×lo g 0 .7 )H (p ,q 1 )=0 .5 5 H (p ,q 2 )=−(1 ×lo g 0 .8 +0 ×lo g 0 .1 +0 ×lo g 0 .1 +0 ×lo g 0 .2 +1 ×lo g 0 .9 +1 ×lo g 0 .9 )H (p ,q 2 )=0 .1 9
以上的所有说明针对的都是单个样例的情况,而在实际的使用训练过程中,数据往往是组合成为一个batch来使用,所以对用的神经网络的输出应该是一个m*n的二维矩阵,其中m为batch的个数,n为分类数目,而对应的Label也是一个二维矩阵,还是拿上面的数据,组合成一个batch=2的矩阵:
q = ( 0.5 0.2 0.3 0.8 0.1 0.1 ) p = ( 1 0 0 1 0 0 ) \begin{aligned} &q=\left(\begin{array}{lll} 0.5 & 0.2 & 0.3 \ 0.8 & 0.1 & 0.1 \end{array}\right) \ &p=\left(\begin{array}{lll} 1 & 0 & 0 \ 1 & 0 & 0 \end{array}\right) \end{aligned}q =(0 .5 0 .8 0 .2 0 .1 0 .3 0 .1 )p =(1 1 0 0 0 0 )
所以交叉樀的结果应该是一个列向量 (根据第一种方法):
H ( p , q ) = ( 0.3 0.1 ) H(p, q)=\left(\begin{array}{l} 0.3 \ 0.1 \end{array}\right)H (p ,q )=(0 .3 0 .1 )
而对于一个 batch,最后取平均为 0.2 0.2 0 .2 。
Original: https://blog.csdn.net/weixin_42327752/article/details/122333995
Author: Weiyaner
Title: softmax函数用于多分类问题的解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664031/
转载文章受原作者版权保护。转载请注明原作者出处!