

首先要了解二分类、多分类和多标签分类
one-hot
在多分类中,必须知道one-hot编码。独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
举例
假设我们有四个样本(行),每个样本有三个特征(列),如图:
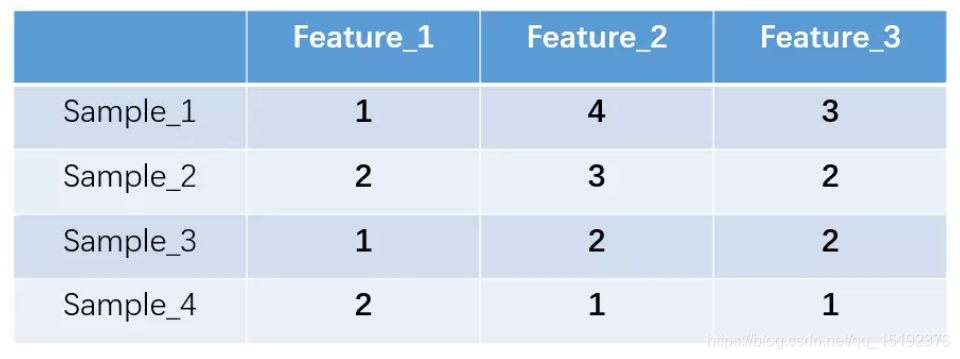

上述feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和 feature_3 各有4种取值(状态)。
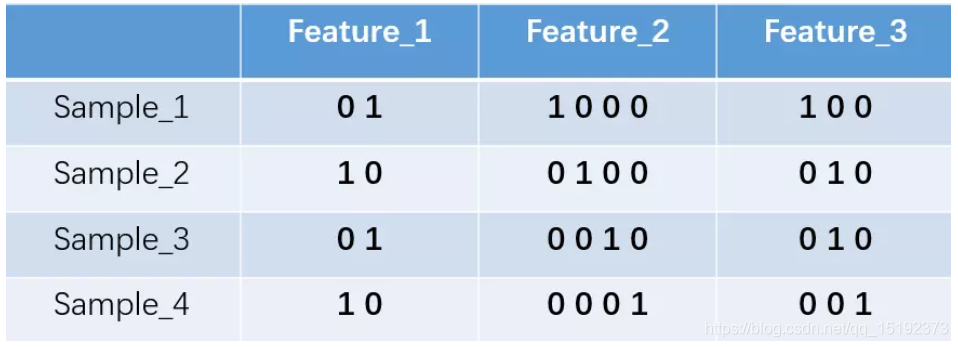
one-hot 编码就是保证 每个样本中的单个特征只有1位处于状态1,其他的都是0。。
上述状态用 one-hot 编码如下图所示:
基于torch的one-hot代码
import torch.nn.functional as F
import torch
num_class = 5
label = torch.tensor([0, 2, 1, 4, 1, 3])
one_hot = F.one_hot(label, num_classes=5 )
print(one_hot)
"""
tensor([[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 0, 0, 1],
[0, 1, 0, 0, 0],
[0, 0, 0, 1, 0]])
"""
基于numpy的one-hot代码
import numpy as np
设置类别的数量
num_classes = 10
需要转换的整数
arr = [1, 3, 4, 5, 9]
将整数转为一个10位的one hot编码
print(np.eye(10)[arr])
多分类的损失函数
多分类问题一般用 softmax作为神经网络的最后一层,然后计算交叉熵损失。
softmax原理
softmax函数的作用是将每个类别所对应的输出分量归一化,使各个分量的和为1。可以理解为将每个输出分量转化为对应的概率。
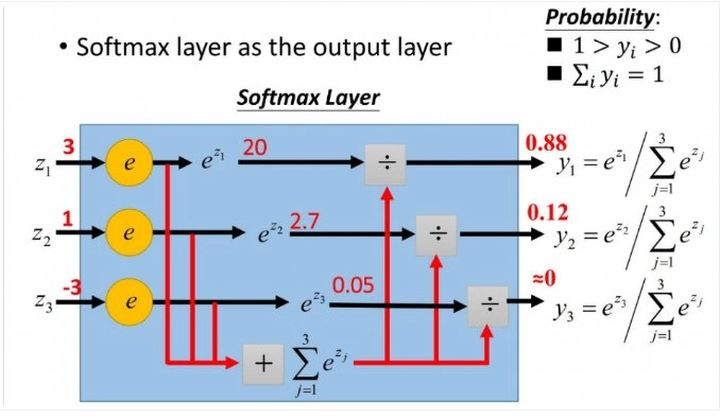
softmax的计算步骤如下:
1.算出e关于每个输入向量的每个元素的幂
2.将所有的幂相加,得到分母
3.每个幂作为相应位置输出结果的分子
4.输出的概率=分子/分母
计算公式:
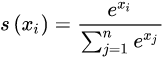
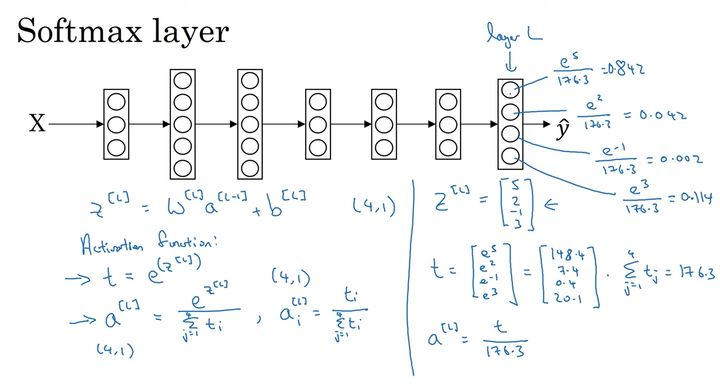
看一个简单是例子,比如输入向量为[-1,0,3,5],softmax的计算结果如下表。

; 交叉熵损失函数
交叉熵的原理
关于样本集的两个概率分布p和q,设p为真实的分布,比如[1,0,0]表示样本属于第一类,q为预测的概率分布,比如[0.7,0.2,0.1]
按照真实分布p来衡量识别一个样本所需的编码长度的期望,即平均编码长度(信息熵):
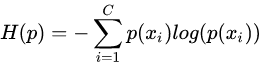
如果使用预测的概率分布q来表示来自真实分布p的编码长度的期望,即平均编码长度(交叉熵):
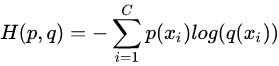
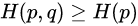
恒成立,当q为真实分布时取等,我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为相对熵,也叫KL散度:
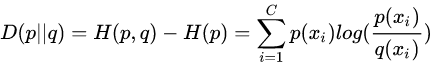
在机器学习的分类问题中,我们希望缩小模型预测和标签之间的差距,即KL散度越小越好,在这里由于KL散度中的H§项不变(在其他问题中未必),故在优化过程中只需要关注交叉熵就可以了,因此一般使用交叉熵作为损失函数。
; 多分类任务中的交叉熵损失函数
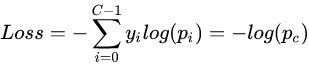

PyTorch中的交叉熵损失函数实现
pytorch提供了两个类来计算交叉熵,分别是CrossEntropyLoss() 和NLLLoss()。
对于torch.nn.CrossEntropyLoss()定义如下:
torch.nn.CrossEntropyLoss(
weight=None,
ignore_index=-100,
reduction="mean",
)
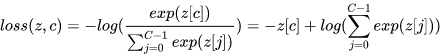
如果weight被指定,
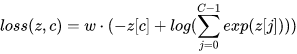
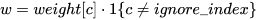
import torch
import torch.nn as nn
model = nn.Linear(10, 3)
criterion = nn.CrossEntropyLoss()
x = torch.randn(16, 10)
y = torch.randint(0, 3, size=(16,)) # (16, )
logits = model(x) # (16, 3)
loss = criterion(logits, y)
对于torch.nn.NLLLoss()定义如下:
torch.nn.NLLLoss(
weight=None,
ignore_index=-100,
reduction="mean",
)
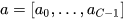
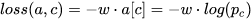
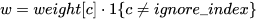
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(10, 3),
nn.LogSoftmax()
)
criterion = nn.NLLLoss()
x = torch.randn(16, 10)
y = torch.randint(0, 3, size=(16,)) # (16, )
out = model(x) # (16, 3)
loss = criterion(out, y)
心得
1.CrossEntropyLoss() 和NLLLoss()的使用是不一样的,使用CrossEntropyLoss() 的网络架构不需要最后一层加入softmax,而NLLLoss()则需要加入softmax.
2.在使用CrossEntropyLoss() 和NLLLoss()的时候,不需要进行one_hot编码,函数会自动处理
3.由于不需要进行one_hot编码,由于网络预测结果的维度会比label的维度多1. 当预测的维度大于2时,第二维度是label的个数(由损失函数的源码可知).
参考链接:
Original: https://blog.csdn.net/qq_42178122/article/details/121459653
Author: Good@dz
Title: 神经网络多分类的实现总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/663459/
转载文章受原作者版权保护。转载请注明原作者出处!