

ROC概念
在信号检测理论中,接收者操作特征曲线,或者叫ROC曲线(Receiver operating characteristic curve),用于选择最佳的信号侦测模型、舍弃次佳的模型或者在同一模型中设置最佳阈值。最近在机器学习领域也得到了很好的发展。
ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,例如(阴性/阳性),(垃圾邮件/非垃圾邮件)
混淆矩阵


; ROC 空间
ROC空间将伪阳率(FPR)定义为X轴,将真阳率(TPR)定义为y轴,从(0,0)到(1,1)的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。
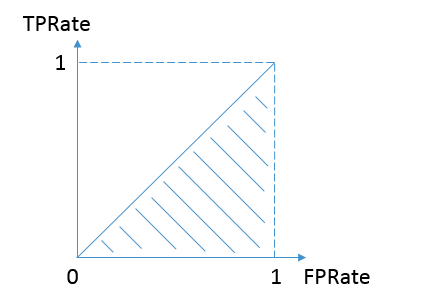
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
ROC曲线
将同一二分类模型每个阈值的 (FPR, TPR) 坐标都画在ROC空间里,就成为特定模型的ROC曲线。
在同一个分类器之内,阈值的不同设置对ROC曲线的影响,有一定规律可循:
- 当阈值设置为最高时,亦即所有样本都被预测为阴性,没有样本被预测为阳性,此时在伪阳性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同时在真阳性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%
当阈值设置为最高时,必得出ROC坐标系左下角的点 (0, 0)。 - 当阈值设置为最低时,亦即所有样本都被预测为阳性,没有样本被预测为阴性,此时在伪阳性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同时在真阳性率 TPR = TP / ( TP + FN ) 算式中的 FN = 0,所以 TPR=100%
当阈值设置为最低时,必得出ROC坐标系右上角的点 (1, 1)。 - 因为TP、FP、TN、FN都是累积次数,TN和FN随着阈值调低而减少(或持平),TP和FP随着阈值调低而增加(或持平),所以FPR和TPR皆必随着阈值调低而增加(或持平)。
随着阈值调低,ROC点 往右上(或右/或上)移动,或不动;但绝不会往左下(或左/或下)移动。
AUC
ROC曲线下方的面积(Area under the Curve of ROC AUC ROC)
AUC计算公式
假设数据集共有M个正样本,N个负样本,预测值也就是M+N个。首先将所有样本按照预测值进行从小到大的排序,并排序编号由1到M+N
- 对于正样本概率最大的,假设排序编号为r a n k 1 rank_{1}r a n k 1 ,比它概率小的负样本个数=r a n k 1 rank_{1}r a n k 1 – M;
- 对于正样本概率第二大的,假设排序编号为r a n k 2 rank_{2}r a n k 2 ,比它概率小的负样本个数=r a n k 1 rank_{1}r a n k 1 – (M-1);
-
…
-
对于正样本概率最小的,假设排序编号为r a n k M rank_{M}r a n k M ,比它概率小的负样本个数=r a n k 1 rank_{1}r a n k 1 – (M-1);
所以在所有情况下,正样本打分大于负样本的个数为:
r a n k 1 rank_{1}r a n k 1 +r a n k 2 rank_{2}r a n k 2 +r a n k M rank_{M}r a n k M -(1+2+…+M)
A U C = ∑ i ∈ p o s i t i v e C l a s s r a n k i − M ( 1 + M ) 2 M ∗ N AUC = \frac{\sum_{i\in positiveClass}rank_{i}- \frac{M(1+M)}{2}}{M*N}A U C =M ∗N ∑i ∈p o s i t i v e C l a s s r a n k i −2 M (1 +M )
AUC意义
由计算公式可知,AUC越大,说明分类器越可能把正样本排在前面,衡量的是一种排序的性能。
如果ROC面积越大,说明曲线越往左上角靠过去。那么对于任意截断点,(FPR,TPR)坐标点越往左上角(0,1)靠,说明FPR较小趋于0(根据定义得知,就是在所有真实负样本中,基本没有预测为正的样本),TRP较大趋于1(根据定义得知,也就是在所有真实正样本中,基本全都是预测为正的样本)。并且上述是对于任意截断点来说的,很明显,那就是分类器对正样本的打分基本要大于负样本的打分(一般预测值也叫打分),衡量的不就是排序能力嘛!
所以AUC含义即为:随机从正样本和负样本中各选一个,分类器对于该正样本打分大于该负样本打分的概率。
AUC优缺点
优点:
● AUC衡量的是一种排序能力,因此特别适合排序类业务;
● AUC对正负样本均衡并不敏感,在样本不均衡的情况下,也可以做出合理的评估。
● 其他指标比如precision,recall,F1,根据区分正负样本阈值的变化会有不同的结果,而AUC不需要手动设定阈值,是一种整体上的衡量方法。
缺点:
● 忽略了预测的概率值和模型的拟合程度;
● AUC反应了太过笼统的信息。无法反应召回率、精确率等在实际业务中经常关心的指标;
● 它没有给出模型误差的空间分布信息,AUC只关注正负样本之间的排序,并不关心正样本内部,或者负样本内部的排序,这样我们也无法衡量样本对于好坏客户的好坏程度的刻画能力;
GAUC
AUC反映的是整体样本间的一个排序能力,但是无法从更加个性化的角度进行分析。推荐系统本身是针对不同用户进行个性化推荐,因此有时候我们在进行分析的时候不能只看整体的AUC。GAUC是AUC的改进版,将样本进行分组后,在组内计算AUC。
GAUC在单个用户AUC的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响:
G A U C = ∑ i = 1 n w i ∗ A U C i ∑ i = 1 n w i GAUC=\frac{\sum_{i=1}^{n}w_{i}*AUC_{i}}{\sum_{i=1}^{n}w_{i}}G A U C =∑i =1 n w i ∑i =1 n w i ∗A U C i
实际处理时权重一般可以设为每个用户view的次数,或click的次数,而且一般计算时,会过滤掉单个用户全是正样本或负样本的情况。
Original: https://blog.csdn.net/qinlingheshang/article/details/123409355
Author: 秦岭小和尚
Title: ROC和AUC
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/663024/
转载文章受原作者版权保护。转载请注明原作者出处!